并发编程之List&Queue体系分析
List
ArrayList线程不安全
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| public class ArrayListSample {
public static void main(String[] args) throws InterruptedException {
final List<Integer> list = new ArrayList<Integer>();
new Thread(new Runnable() {
public void run() {
for (int i = 0; i < 10000 ; i++) {
list.add(i);
}
}
}).start();
new Thread(new Runnable() {
public void run() {
for (int i = 10000; i < 20000 ; i++) {
list.add(i);
}
}
}).start();
Thread.sleep(1000);
System.out.println(list.size());
for (int i = 0; i < list.size(); i++) {
System.out.println("第" + (i + 1) + "个元素为:" + list.get(i));
}
}
}
|
CopyOnWriteArrayList线程安全
写时复制List,增删操作时,加锁并且复制另一个数组来进行修改,修改后再替换原来的数组,读操作不做控制
优点:适用于读多写少,数据量较小的场景,支持在遍历迭代式增删元素
缺点:数据量大时占用内存大,易引发GC。
BlockingQueue阻塞队列
https://blog.csdn.net/qq_45105530/article/details/122490152
实质就是一种存储数据的结构
通常用链表或者数组实现
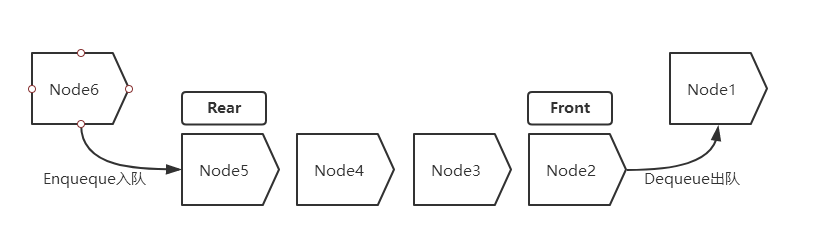
一般而言队列具备FIFO先进先出的特性,当然也有双端队列(Deque)优先级队列
主要操作:入队(EnQueue)与出队(Dequeue)
种类
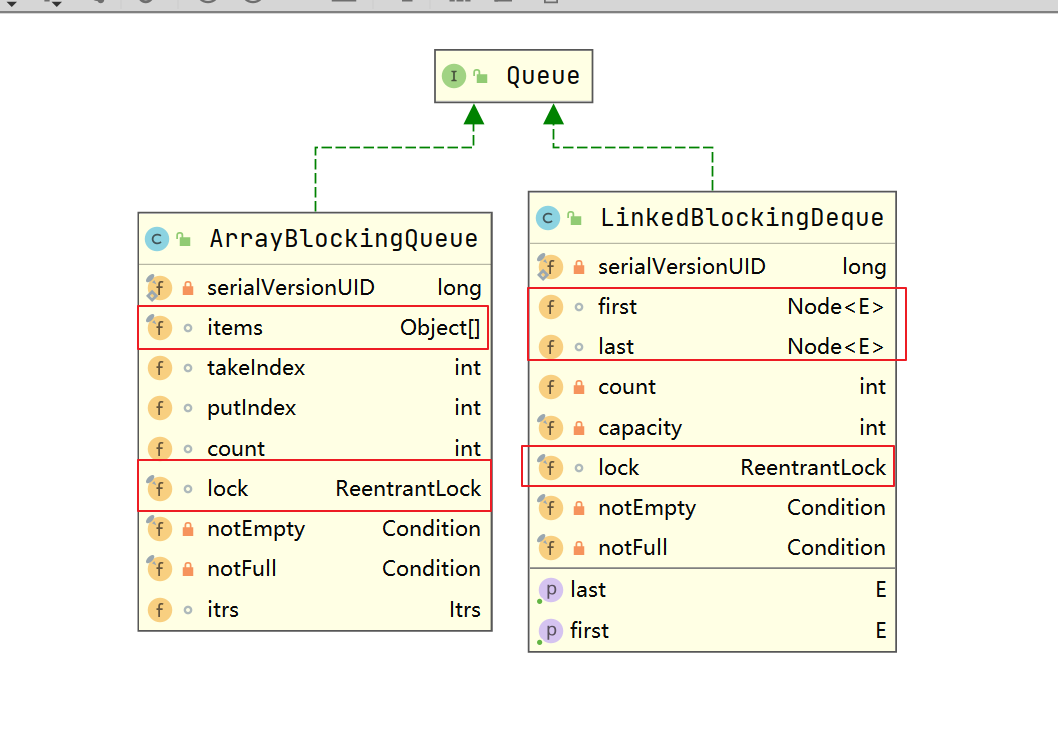
1、ArrayBlockingQueue 由数组支持的有界队列
2、LinkedBlockingQueue 由链接节点支持的可选有界队列
3、PriorityBlockingQueue 由优先级堆支持的无界优先级队列
4、DelayQueue 由优先级堆支持的、基于时间的调度队列
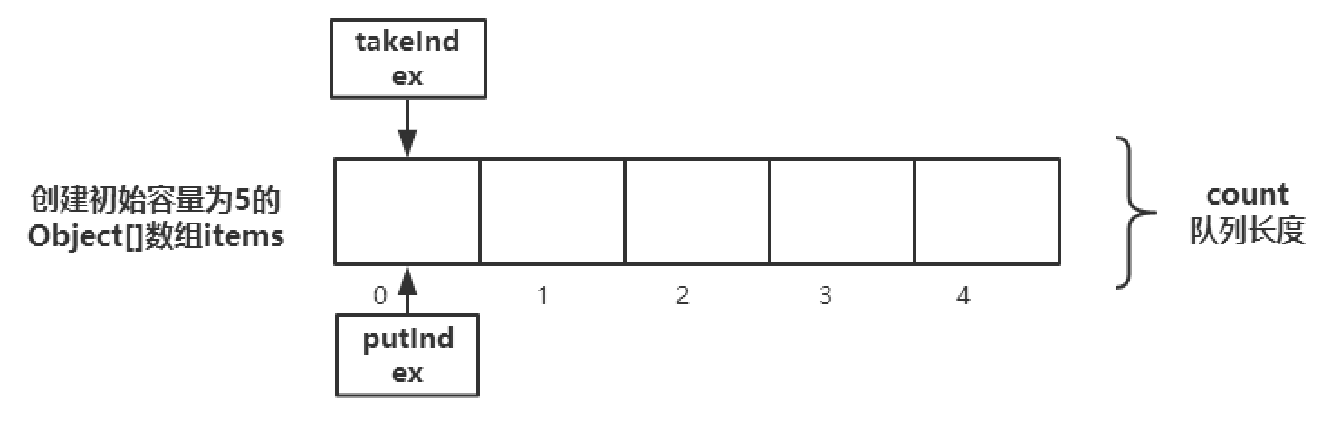
ArrayBlockingQueue数据结构
队列基于数组实现,容量大小在创建ArrayBlockingQueue对象时已定义好
样例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
| public class Ball {
private String number ;
private String color ;
public String getNumber() {
return number;
}
public void setNumber(String number) {
this.number = number;
}
public String getColor() {
return color;
}
public void setColor(String color) {
this.color = color;
}
}
public class ArrayBlockingQueueTest {
private BlockingQueue<Ball> blockingQueue = new ArrayBlockingQueue<Ball>(5);
public int queueSize(){
return blockingQueue.size();
}
public void produce(Ball ball) throws InterruptedException{
blockingQueue.put(ball);
}
public Ball consume() throws InterruptedException {
return blockingQueue.take();
}
public static void main(String[] args){
final ArrayBlockingQueueTest box = new ArrayBlockingQueueTest();
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.submit(new Runnable() {
@Override
public void run() {
int i = 0;
while (true){
Ball ball = new Ball();
ball.setNumber("乒乓球编号:"+i);
ball.setColor("yellow");
try {
System.out.println(System.currentTimeMillis()+
":准备往箱子里放入乒乓球:--->"+ball.getNumber());
box.produce(ball);
System.out.println(System.currentTimeMillis()+
":往箱子里放入乒乓球:--->"+ball.getNumber());
System.out.println("put操作后,当前箱子中共有乒乓球:--->"
+ box.queueSize() + "个");
Thread.sleep(new Random().nextInt(3) * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
i++;
}
}
});
executorService.submit(new Runnable() {
@Override
public void run() {
while (true){
try {
System.out.println(System.currentTimeMillis()+
"准备到箱子中拿乒乓球:--->");
Ball ball = box.consume();
System.out.println(System.currentTimeMillis()+
"拿到箱子中的乒乓球:--->"+ball.getNumber());
System.out.println("take操作后,当前箱子中共有乒乓球:--->"
+ box.queueSize() + "个");
Thread.sleep(new Random().nextInt(3) * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
}
}
|
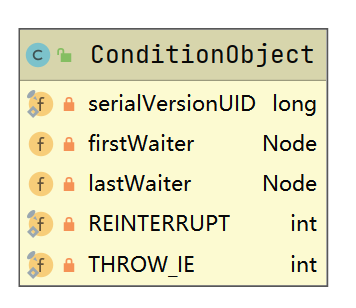
条件等待队列
put方法中,使用了AQS的条件等待队列
条件队列中的结点是不会被唤醒去争夺锁的,只能通过转移至CLH同步等待队列才能参与争夺锁
在ArrayBlockingQueue中,维护了 2个条件等待队列,具体实现是AQS的ConditionObject
1
2
3
4
5
|
private final Condition notEmpty;
private final Condition notFull;
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
| public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}
public final void await() throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
Node node = addConditionWaiter();
int savedState = fullyRelease(node);
int interruptMode = 0;
while (!isOnSyncQueue(node)) {
LockSupport.park(this);
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null)
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
}
private Node addConditionWaiter() {
Node t = lastWaiter;
if (t != null && t.waitStatus != Node.CONDITION) {
unlinkCancelledWaiters();
t = lastWaiter;
}
Node node = new Node(Thread.currentThread(), Node.CONDITION);
if (t == null)
firstWaiter = node;
else
t.nextWaiter = node;
lastWaiter = node;
return node;
}
|
PriorityBlockingQueue
实质是小顶堆,小的在前,大的在后
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| public class PriorityQueueTest {
public static void main(String[] args) throws InterruptedException {
PriorityBlockingQueue<Integer> priorityQueue = new PriorityBlockingQueue<>(5);
add(priorityQueue,2);
add(priorityQueue,3);
add(priorityQueue,4);
add(priorityQueue,5);
add(priorityQueue,6);
add(priorityQueue,7);
add(priorityQueue,1);
while(true){
Integer peek = priorityQueue.take();
System.out.println(peek);
}
}
public static void add(PriorityBlockingQueue<Integer> priorityQueue,Integer num){
priorityQueue.add(num);
if(priorityQueue.size() > 5 ){
priorityQueue.remove();
}
}
}
3
4
5
6
7
线程阻塞
|
DelayQueue
由优先级堆支持的、基于时间的调度队列,内部基于无界队列PriorityQueue实现,而无界队列基于数组的扩容实现。
应用场景:电影票
要求入队的对象必须要实现Delayed接口,而Delayed集成自Comparable接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
| public class MovieTiket implements Delayed {
private final long delay;
private final long expire;
private final String msg;
private final long now;
public long getDelay() {
return delay;
}
public long getExpire() {
return expire;
}
public String getMsg() {
return msg;
}
public long getNow() {
return now;
}
public MovieTiket(String msg , long delay) {
this.delay = delay;
this.msg = msg;
expire = System.currentTimeMillis() + delay;
now = System.currentTimeMillis();
}
public MovieTiket(String msg){
this(msg,1000);
}
public MovieTiket(){
this(null,1000);
}
public long getDelay(TimeUnit unit) {
return unit.convert(this.expire
- System.currentTimeMillis() , TimeUnit.MILLISECONDS);
}
public int compareTo(Delayed delayed) {
return (int) (this.getDelay(TimeUnit.MILLISECONDS)
- delayed.getDelay(TimeUnit.MILLISECONDS));
}
@Override
public String toString() {
return "MovieTiket{" +
"delay=" + delay +
", expire=" + expire +
", msg='" + msg + '\'' +
", now=" + now +
'}';
}
}
public class DelayedQueueTest {
public static void main(String[] args) {
DelayQueue<MovieTiket> delayQueue = new DelayQueue<MovieTiket>();
MovieTiket tiket = new MovieTiket("电影票0",10000);
delayQueue.put(tiket);
MovieTiket tiket1 = new MovieTiket("电影票1",5000);
delayQueue.put(tiket1);
MovieTiket tiket2 = new MovieTiket("电影票2",8000);
delayQueue.put(tiket2);
System.out.println("message:--->入队完毕");
while( delayQueue.size() > 0 ){
try {
tiket = delayQueue.take();
System.out.println("电影票出队:"+tiket.getMsg());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
message:--->入队完毕
电影票出队:电影票1
电影票出队:电影票2
电影票出队:电影票0
|
HashMap
是什么
基本结构
HashMap存储的是存在映射关系的键值对,存储在被称为哈希表(数组+链表或红黑树(JDK>7后))的数据结构中。通过计算key的hashCode值来确定键值对在数组中的位置,假如产生碰撞,则使用链表或红黑树。
而为了避免hashcode碰撞,就涉及了元素的分布策略和动态扩容
分布策略
分布策略的体现主要有3个点
1、HashMap的底层数组长度始终保存为2的次幂
2、hash算法使用了key哈希值的高位
3、通过与操作对数组长度取模

动态扩容
HashMap长度默认为16
loadFactor负载因子默认为0.75
threshold容量=loadFactor * length,每当hashmap的数组长度超过threshold时,hashmap就会进行扩容一倍,避免因为数组太满导致过多的hash碰撞
动态扩容方面,由于底层数组的长度始终为2的次幂,也就是说每次扩容,长度值都会扩大一倍,数组长度length的二进制表示在高位会多出1bit。而扩容时,该length值将会参与位于操作来确定元素所在数组中的新位置。所以,原数组中的元素所在位置要么保持不动,要么就是移动2次幂个位置。但是,HashMap美中不足的是∶它不是线程安全的。主要体现在两个方面∶
扩容时出现著名的环形链表异常,此问题在JDK1.8版本被解决。·
并发下脏读脏写
Java7HashMap
Hash表 = 数组 + 链表
扩容闭环导致死锁
扩容时可能会产生死锁,多线程扩容时链表头插法并发扩容时,可能产生闭环
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| public class MapResizer implements Runnable {
private static Map<Integer,Integer> map = new HashMap<Integer, Integer>(2);
private static AtomicInteger atomicInteger = new AtomicInteger();
@Override
public void run() {
while(atomicInteger.get() < 100000){
map.put(atomicInteger.get(),atomicInteger.get());
atomicInteger.incrementAndGet();
}
System.out.println( Thread.currentThread().getName() + "线程结束");
}
}
public class MapTest {
public static void main(String[] args) {
for (int i=0;i<30;i++){
new Thread(new MapResizer()).start();
}
}
}
|
产生闭环的原因
https://blog.csdn.net/Krone_/article/details/125101531
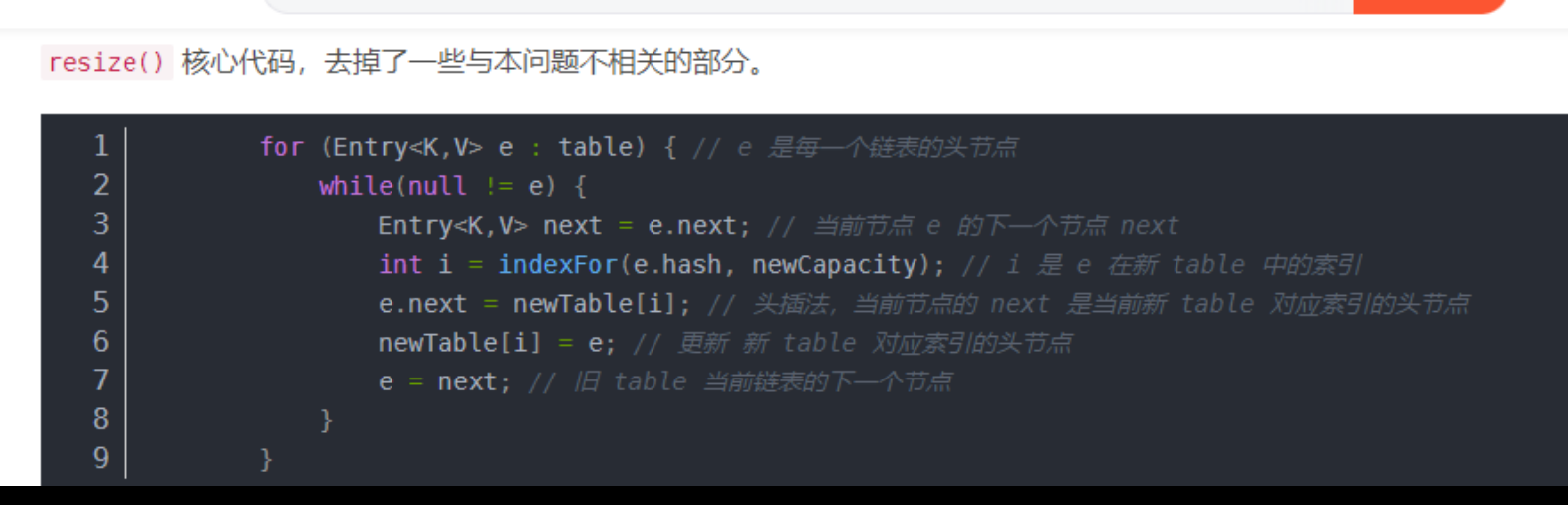
A线程:e0 -> e1,切换时间片
B线程:e0 -> e1,扩容完成后,e1->e0
A线程:e1 -> e0 -> e1,无法跳出循环
jdk8后,改用了尾插法,避免了这个问题,但还是存在其他并发问题
Java8HashMap
Hash表 = 数组 + 链表 + 红黑树
数组扩容时,高低位搭配,不可能形成闭环
扩容时不会形成闭环,而是采用高低位插入,if((e.hash & oldCap) == 0) 判断是否需要移动元素,hash值在oldCap的最高位=1则扩容后下标=扩容前大小+原下标,否则=原下标。
扩容后原链表大概会被拆成2段,一段在原下标,一段在(扩容前长度+原下标)的位置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
|
1
2
3
4
5
6
7
8
| if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
|
链表长度大于8并且数组的长度大于64,会把链表转换成红黑树,当链表长度小于等于6时恢复为链表
1、TreeNodes占用空间是普通Nodes的两倍,所以只有当Entry链包含足够多的节点且数组长度足够大时才会转成TreeNodes以追求查询速度log2N。
2、且正常来说如果hashcode的离散性好的话,value会均匀分布在数组中而很难达到长度为8的地步。
3、所以当出现了碰撞度比较高的离散算法时,才会使用到红黑树
理想情况下我们可以看到,一个bin中链表长度达到8个元素的概率为0.00000006,几乎是不可能事件,
0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.00000006
扩容过程
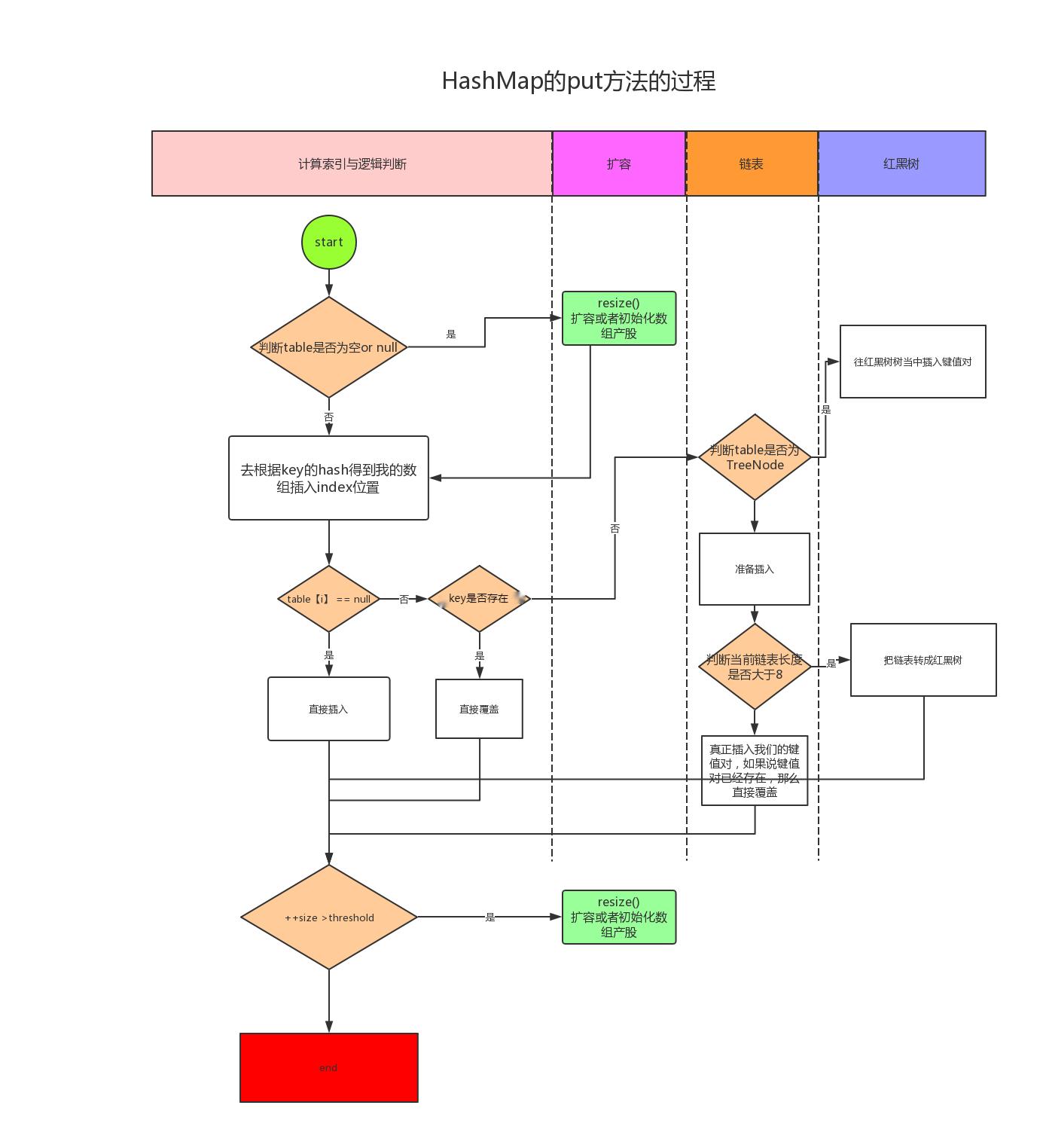
基本步骤如下:
1、数组[i]对象是否存在,不存在则直接插入
2、存在,判断链表或者红黑树中key是否存在,不存在则直接插入
3、存在则直接覆盖
4、插入后更具size++ > threshold?判断是否需要扩容
数据丢失问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| public class HashMapDataLost {
public static final Map<String, String> map = new HashMap<String, String>();
public static void main(String[] args) throws InterruptedException {
new Thread() {
public void run() {
for (int i = 0; i < 1000; i++) {
map.put(String.valueOf(i), String.valueOf(i));
}
}
}.start();
new Thread(){
public void run() {
for(int j=1000;j<2000;j++){
map.put(String.valueOf(j), String.valueOf(j));
}
}
}.start();
try {
Thread.currentThread().sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("map.size"+map.size());
for(int i=0;i<2000;i++){
if(Objects.isNull(map.get(String.valueOf(i)))){
System.out.println("_________________________________________________________________");
}
System.out.println("第:"+i+"元素,值:"+map.get(String.valueOf(i)));
}
}
}
map.size1978
...
第:53元素,值:53
_________________________________________________________________
第:54元素,值:null
...
|
HashTable
既然HashMap是线程不安全的,那我每次put/get操作时都用锁进行控制不就好了?HashTable确实是这么做的,给get/put操作加上了synchronized关键字。
但是这样会导致效率低下,在多线程环境下进行读写操作时,其他操作都会被阻塞。
所以基本上不推荐使用HashTable。
ConcurrentHashMap
ConcurrentHashMap是线程安全
1.7分段锁
ConcurrentHashMap 1.7 = Segment数组(继承ReentrantLock) + HashEntry数组 + 链表,从而实现分段锁,支持并发。
HashTable是用一把锁锁住了所有数据,而ConcurrentHashMap是将数组分为多个段,每把锁只锁数组中的一段数据,就能大大减少锁的竞争。
JDK7组成结构
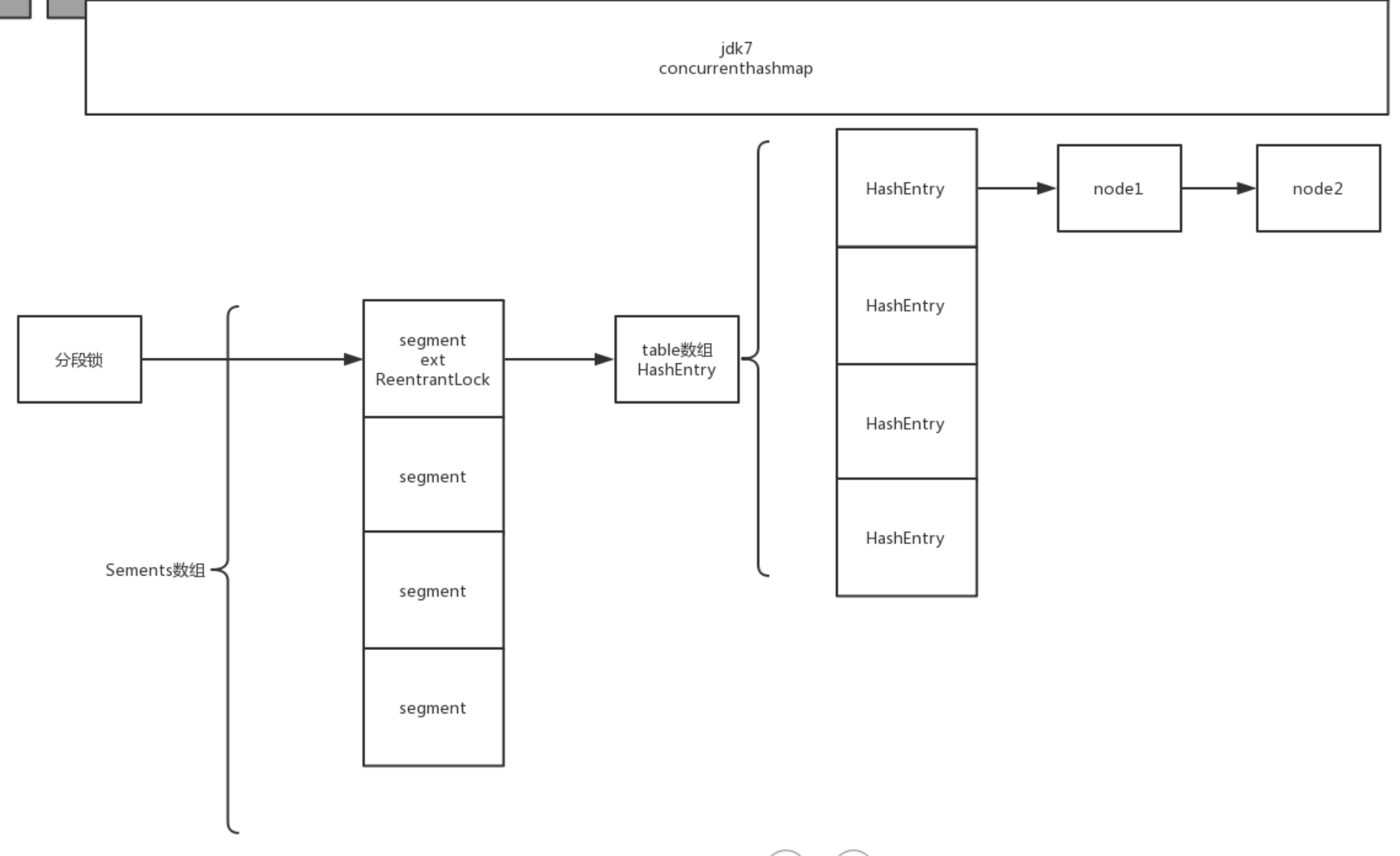
扩容
1、扩容仅仅针对HashEntry数组,Segement数组在初始化后就无法扩容
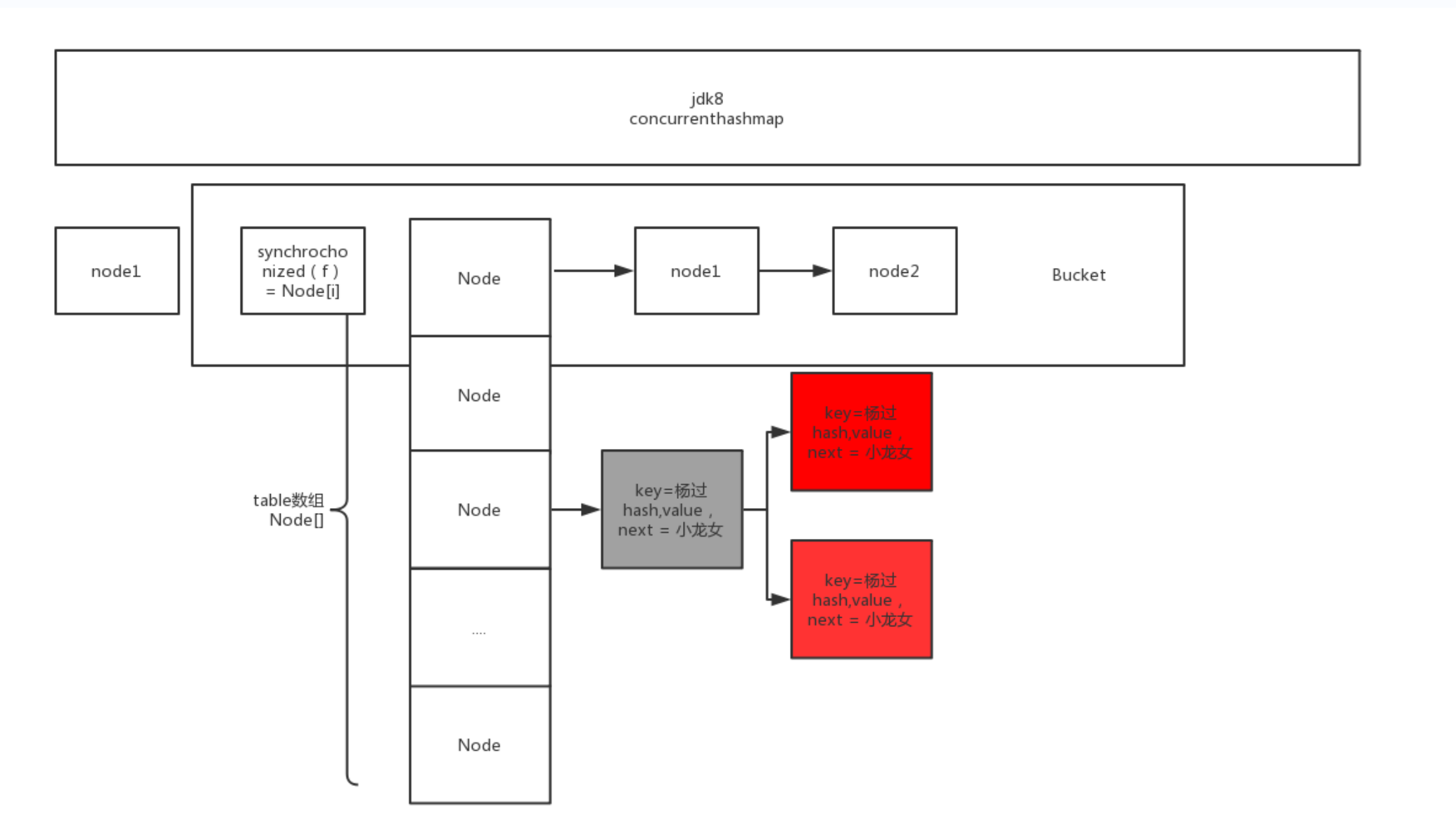
1.8桶锁
ConcurrentHashMap 1.8 = Node数组 + 链表/红黑树,区别在于每次插入,都synchronized第一个节点,相当于锁一条链表,锁的粒度变小。
1、当当前下标table[i] = null 时,通过CAS设置头结点(无锁,自由并发争抢)。
2、table[i] != null时,synchronized 该节点,锁这个链表的,其他链表不影响。