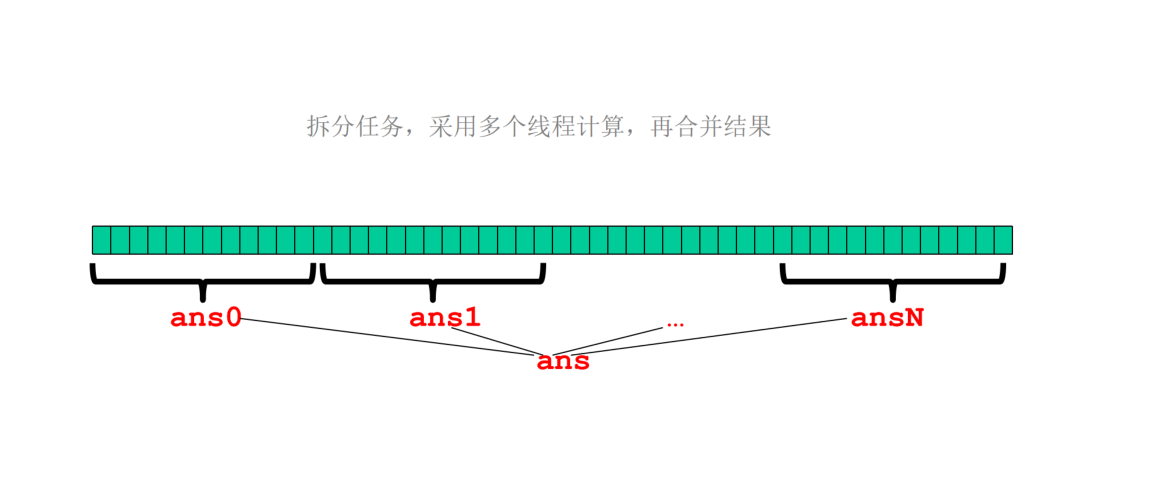
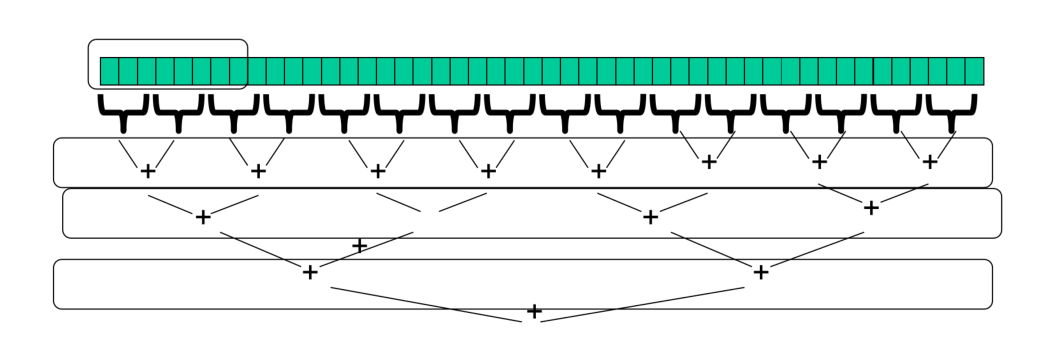
long begin = System.currentTimeMillis(); long result = sum(arr);
long end = System.currentTimeMillis(); System.out.printf("The result is: %d\n", result); System.out.println("单线程:"+ (end - begin)); } } The array length is: 200000 The result is: 9905876 单线程:5
publicclassSumRecursiveMT{ publicstaticclassRecursiveSumTaskimplementsCallable<Long> { publicstaticfinalint SEQUENTIAL_CUTOFF = 1; int lo; int hi; int[] arr; // arguments ExecutorService executorService;
RecursiveSumTask( ExecutorService executorService, int[] a, int l, int h) { this.executorService = executorService; this.arr = a; this.lo = l; this.hi = h; }
public Long call()throws Exception { // override System.out.format("%s range [%d-%d] begin to compute %n", Thread.currentThread().getName(), lo, hi); long result = 0; if (hi - lo <= SEQUENTIAL_CUTOFF) { for (int i = lo; i < hi; i++) result += arr[i];
System.out.format("%s range [%d-%d] begin to finished %n", Thread.currentThread().getName(), lo, hi); } else { RecursiveSumTask left = new RecursiveSumTask(executorService, arr, lo, (hi + lo) / 2); RecursiveSumTask right = new RecursiveSumTask(executorService, arr, (hi + lo) / 2, hi); Future<Long> lr = executorService.submit(left); Future<Long> rr = executorService.submit(right);
result = lr.get() + rr.get(); System.out.format("%s range [%d-%d] finished to compute %n", Thread.currentThread().getName(), lo, hi); }
} } //无法正常运行 4个线程无法完成递归 The array length is: 200000 pool-1-thread-1 range [0-200000] begin to compute pool-1-thread-2 range [0-100000] begin to compute pool-1-thread-3 range [100000-200000] begin to compute pool-1-thread-4 range [0-50000] begin to compute
publicclassSumMultiThreads{ publicfinalstaticint NUM = 1000; publicstaticlongsum(int[] arr, ExecutorService executor)throws Exception { long result = 0; int numThreads = arr.length / NUM > 0 ? arr.length / NUM : 1;
SumTask[] tasks = new SumTask[numThreads]; Future<Long>[] sums = new Future[numThreads]; for (int i = 0; i < numThreads; i++) { tasks[i] = new SumTask(arr, (i * NUM), ((i + 1) * NUM)); sums[i] = executor.submit(tasks[i]); }
for (int i = 0; i < numThreads; i++) { result += sums[i].get(); }
int numThreads = arr.length / NUM > 0 ? arr.length / NUM : 1; long begin = System.currentTimeMillis();
System.out.printf("The array length is: %d\n", arr.length); ExecutorService executor = Executors.newFixedThreadPool(numThreads);
long result = sum(arr, executor);
long end = System.currentTimeMillis(); System.out.printf("The result is: %d\n", result); System.out.println("多线程:"+ (end - begin)); } } The array length is: 200000 The result is: 9904260 多线程:177
publicclassSumRecursiveMT{ publicstaticclassRecursiveSumTaskimplementsCallable<Long> { publicstaticfinalint SEQUENTIAL_CUTOFF = 1000; int lo; int hi; int[] arr; // arguments ExecutorService executorService;
RecursiveSumTask( ExecutorService executorService, int[] a, int l, int h) { this.executorService = executorService; this.arr = a; this.lo = l; this.hi = h; }
public Long call()throws Exception { // override System.out.format("%s range [%d-%d] begin to compute %n", Thread.currentThread().getName(), lo, hi); long result = 0; if (hi - lo <= SEQUENTIAL_CUTOFF) { for (int i = lo; i < hi; i++) result += arr[i];
System.out.format("%s range [%d-%d] begin to finished %n", Thread.currentThread().getName(), lo, hi); } else { RecursiveSumTask left = new RecursiveSumTask(executorService, arr, lo, (hi + lo) / 2); RecursiveSumTask right = new RecursiveSumTask(executorService, arr, (hi + lo) / 2, hi); Future<Long> lr = executorService.submit(left); Future<Long> rr = executorService.submit(right);
result = lr.get() + rr.get(); System.out.format("%s range [%d-%d] finished to compute %n", Thread.currentThread().getName(), lo, hi); }
RecursiveSumTask task = new RecursiveSumTask(executorService, arr, 0, arr.length); long result = executorService.submit(task).get(); return result; }
publicstaticvoidmain(String[] args)throws Exception { int[] arr = Utils.buildRandomIntArray(200000); System.out.printf("The array length is: %d\n", arr.length); long begin = System.currentTimeMillis(); long result = sum(arr); long end = System.currentTimeMillis(); System.out.printf("The result is: %d\n", result); System.out.println("递归:"+ (end - begin));
staticfinalint SEQUENTIAL_THRESHOLD = 1000; staticfinallong NPS = (1000L * 1000 * 1000); staticfinalboolean extraWork = true; // change to add more than just a sum
int low; int high; int[] array;
LongSum(int[] arr, int lo, int hi) { array = arr; low = lo; high = hi; }
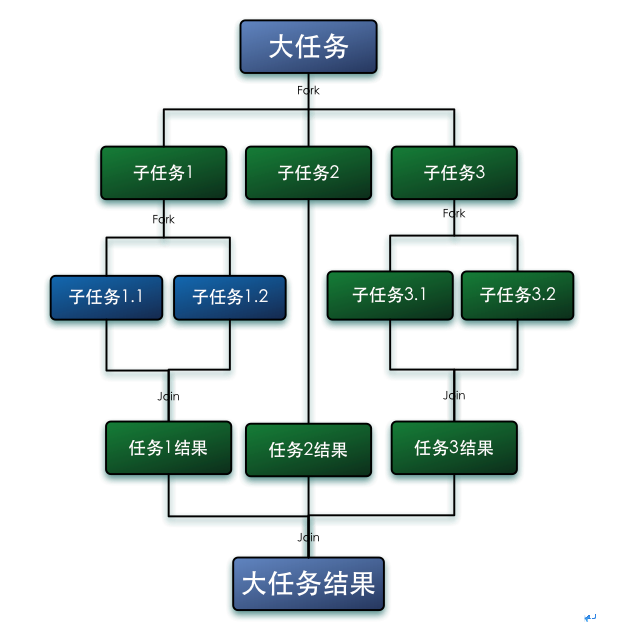
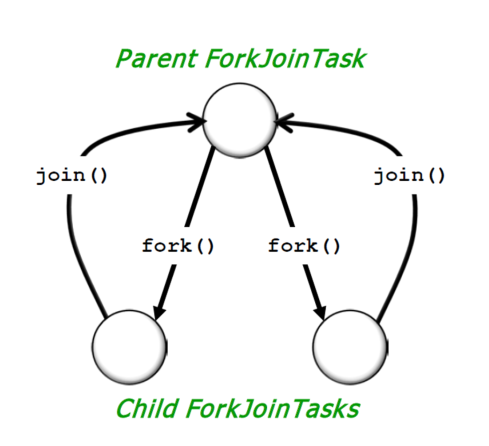
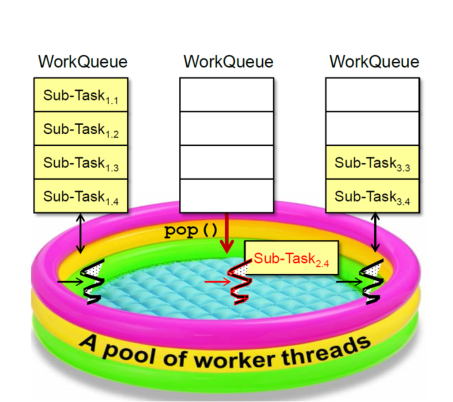
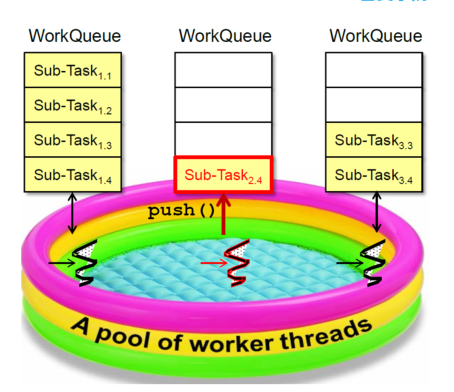
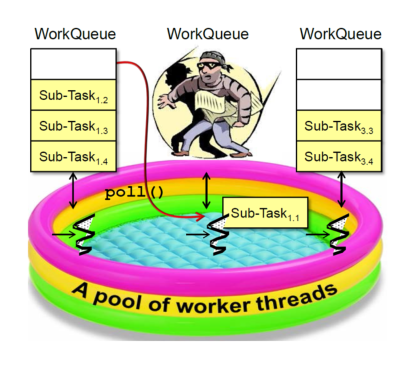
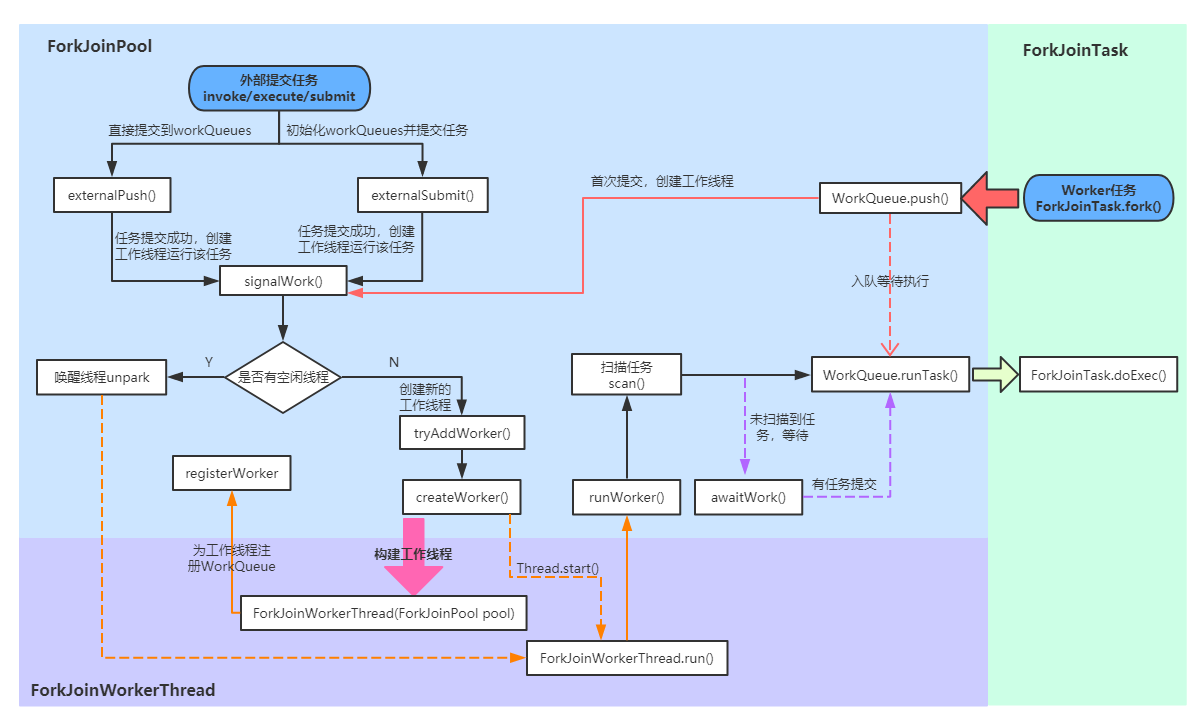
/** * fork()方法:将任务放入队列并安排异步执行,一个任务应该只调用一次fork()函数,除非已经执行完毕并重新初始化。 * tryUnfork()方法:尝试把任务从队列中拿出单独处理,但不一定成功。 * join()方法:等待计算完成并返回计算结果。 * isCompletedAbnormally()方法:用于判断任务计算是否发生异常。 */ protected Long compute(){ if (high - low <= SEQUENTIAL_THRESHOLD) { long sum = 0; for (int i = low; i < high; ++i) { sum += array[i]; } return sum; } else { int mid = low + (high - low) / 2; LongSum left = new LongSum(array, low, mid); LongSum right = new LongSum(array, mid, high); left.fork(); right.fork(); long rightAns = right.join(); long leftAns = left.join(); return leftAns + rightAns; } } }