JVM内存模型介绍
JDK体系结构
JDK
JDK(Java SE Development Kit):Java开发标准包,它提供了编译、运行Java程序所需的各种工具和资源,包括Java编译器、Java运行时环境,以及常用的Java类库等。

JRE
JRE(Java Runtime Environment):Java运行环境,用于解释执行Java的字节码文件。普通用户而只需要安装 JRE来运行 Java 程序。而程序开发者必须安装JDK来编译、调试程序。
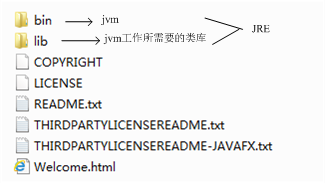
JVM
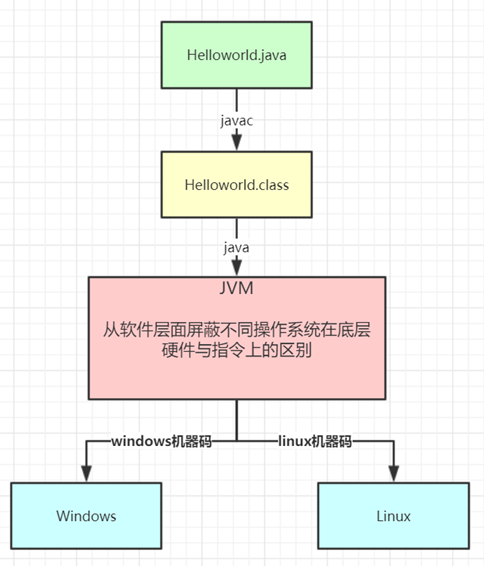
JVM(Java Virtual Machine ):Java虚拟机,是JRE的一部分。它是整个java实现跨平台的最核心的部分(一次编译,到处运行),负责解释执行字节码文件,是可运行java字节码文件的虚拟计算机。所有平台的上的JVM向编译器提供相同的接口,而编译器只需要面向虚拟机,生成虚拟机能识别的代码,然后由虚拟机来解释执行。
区别与联系
- JDK 用于开发,JRE 用于运行java程序 ;如果只是运行Java程序,可以只安装JRE,无序安装JDK。
- JDk包含JRE,JDK 和 JRE 中都包含 JVM。
- JVM 是 java 编程语言的核心并且具有平台独立性。
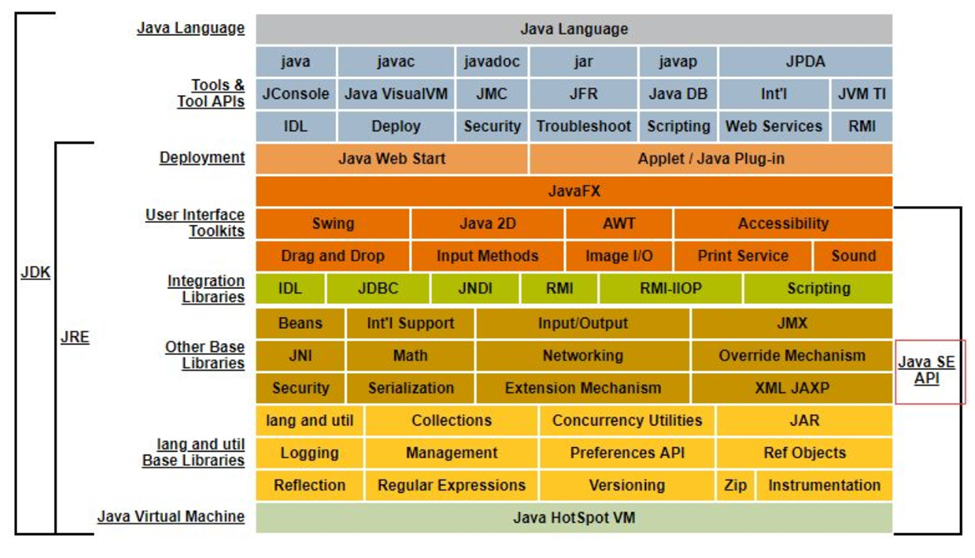
Java语言的跨平台特性
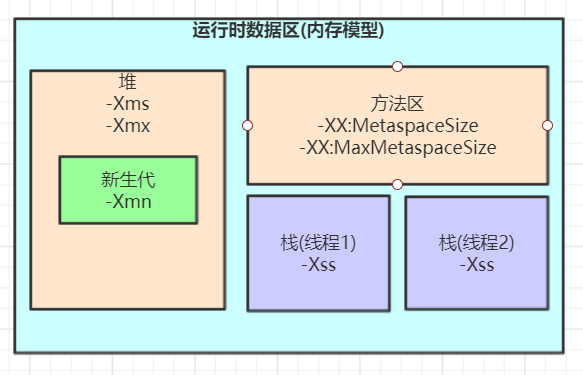
JVM内存模型(运行时数据区)
内存模型结构
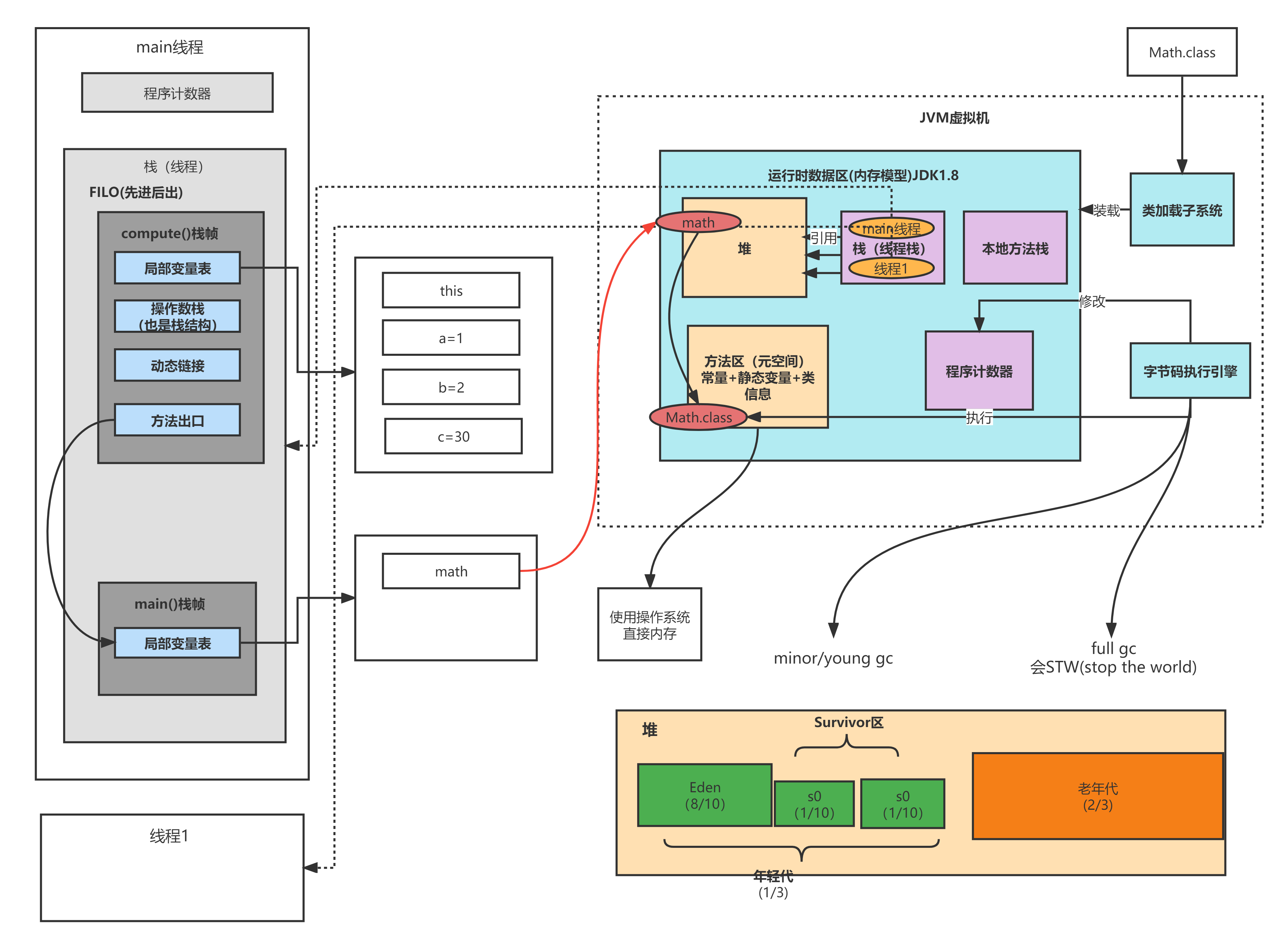
在minor gc过程中对象挪动后,引用如何修改?
对象在堆内部挪动的过程其实是复制,原有区域对象还在,一般不直接清理,JVM内部清理过程只是将对象分配指针移动到区域的头位置即可,比如扫描s0区域,扫到gcroot引用的非垃圾对象是将这些对象复制到s1或老年代,最后扫描完了将s0区域的对象分配指针移动到区域的起始位置即可,s0区域之前对象并不直接清理,当有新对象分配了,原有区域里的对象也就被清除了。
minor gc在根扫描过程中会记录所有被扫描到的对象引用(在年轻代这些引用很少,因为大部分都是垃圾对象不会扫描到),如果引用的对象被复制到新地址了,最后会一并更新引用指向新地址。
这里面内部算法比较复杂,感兴趣可以参考R大的这篇文章:
https://www.zhihu.com/question/42181722/answer/145085437
https://hllvm-group.iteye.com/group/topic/39376#post-257329
JVM内存参数设置
Spring Boot程序的JVM参数设置格式(Tomcat启动直接加在bin目录下catalina.sh文件里):
1 | |
1、-Xms(memory size-内存大小):堆初始化可用大小,默认物理内存的1/64
2、-Xmx(memory max-内存最大):堆最大可用大小,默认物理内存的1/64
3、-Xmn(memory new-新生代内存):新生代大小
4、-Xss(stack size-栈大小):每个线程栈的大小(一般而言,每个线程栈大小与支持的并发线程数成反比)
5、-XX:MetaspaceSize:元空间触发full gc的初始阈值
6、-XX:MaxMetaspaceSize:,达到该值就会触发full gc进行类型卸载, 同时收集器会对该值进行调整: 如果释放了大量的空间, 就适当降低该值; 如果释放了很少的空间, 那么在不超过-XX:MaxMetaspaceSize(如果设置了的话) 的情况下, 适当提高该值。
7、-XX:NewRatio:默认2表示新生代占年老代的1/2,占整个堆内存的1/3。
8、-XX:SurvivorRatio:默认8表示一个survivor区占用1/8的Eden内存,即1/10的新生代内存。
StackOverflowError示例:
1 | |
结论:
-Xss设置越小count值越小,说明一个线程栈里能分配的栈帧就越少,但是对JVM整体来说能开启的线程数会更多
JVM内存参数大小设置举例
JVM参数大小设置并没有固定标准,需要根据实际项目情况分析,给大家举个例子
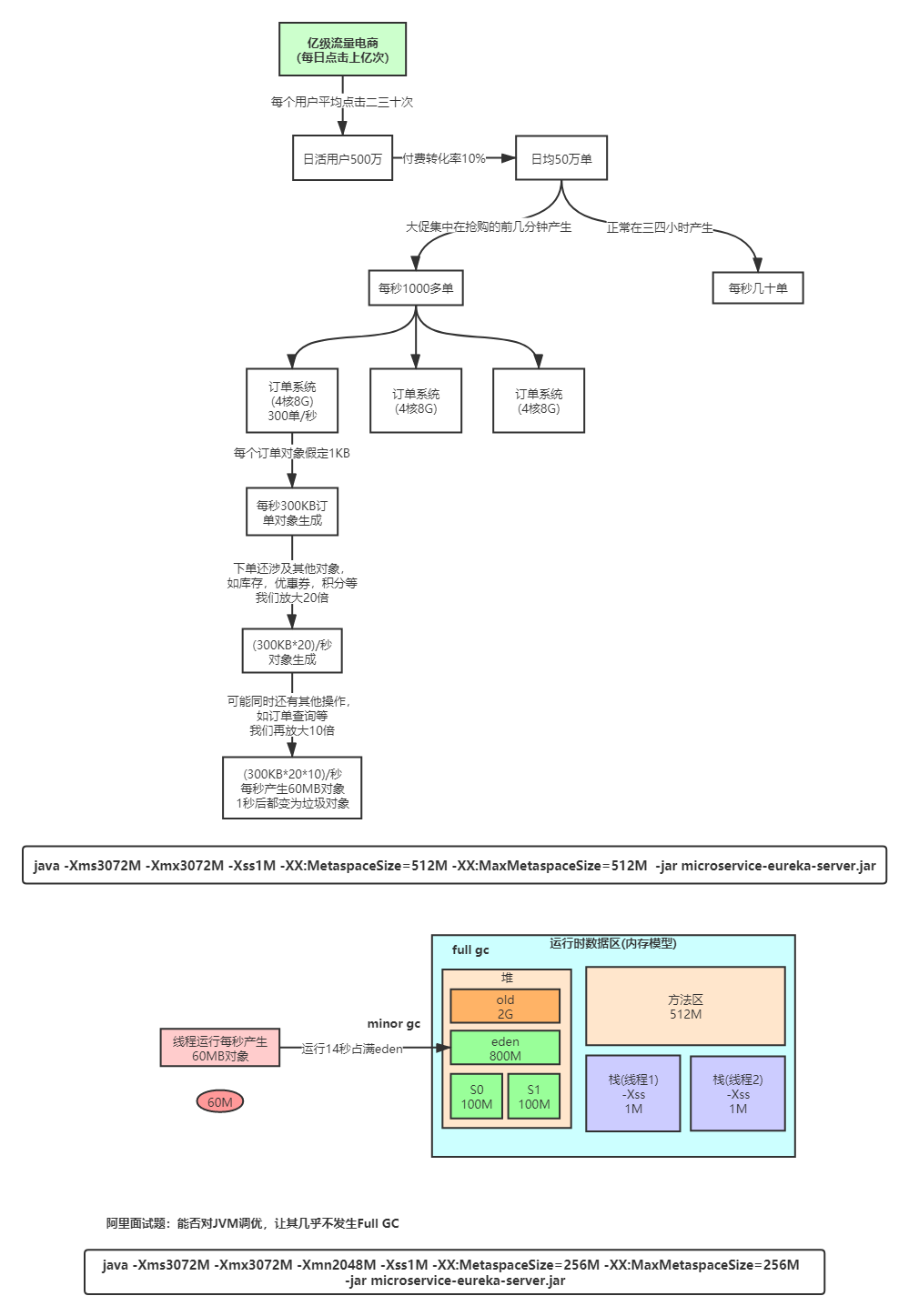
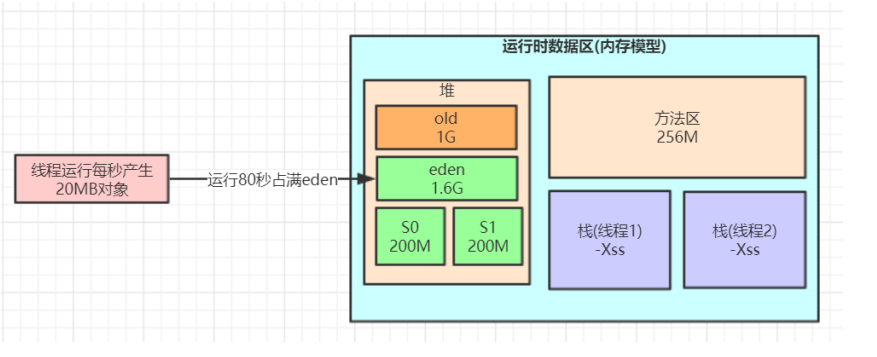
其实调优后最大的区别是设置年轻代的大小为2G,老年代变为1G,eden有1600M,S1,S2 = 200M,这样需要 1600 / 60 约定于27秒才能把Eden放满,这样即便是高峰期,也很少有对象存活15次后进到老年代亦或者存货区放不下直接移动到老年代。
逃逸分析
JVM的运行模式有三种:
1、解释器模式:只使用解释器,执行一行jvm字节码就解释一行为机器码
2、编译模式:只使用编译模式,先将所有jvm字节码一次性编译为机器码,然后一次性执行所有机器码
3、混合模式:混合模式,依然使用解释器模式执行代码,但是对于一些“热点”代码采用编译模式执行,JVM默认采用混合模式执行代码
解释模式启动快,对于只需要执行部分代码,并且大多数代码只会执行一次的情况比较适合;
编译模式启动慢,但是后期执行速度快,而且比较占用内存,因为机器码的数量至少是JVM字节码的十倍以上,这种模式适合代码可能会被反复执行的场景;
混合模式是JVM默认采用的执行代码方式,一开始还是解释执行,但是对于少部分 “热点 ”代码会采用编译模式执行,这些热点代码对应的机器码会被缓存起来,下次再执行无需再编译,这就是我们常见的JIT(Just In Time Compiler)即时编译技术。
1 | |
对象逃逸分析:就是分析对象动态作用域,当一个对象在方法中被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他地方中。
很显然test1方法中的user对象被返回了,这个对象的作用域范围不确定,test2方法中的user对象我们可以确定当方法结束这个对象就可以认为是无效对象了.
对于这样的对象我们其实可以将其分配在栈内存里,让其在方法结束时跟随栈内存一起被回收掉,如果这时候栈内存不足,则再分配到堆上。
此外,线程逃逸分析通常是在 JVM 的编译阶段进行的。在编译阶段,JVM 会对代码进行分析和优化,包括对象的分配和内存管理
1 | |
结论:栈上分配依赖于逃逸分析和标量替换,逃逸分析和标量替换在JDK8默认开启
Server模式和Client模式
JVM 有两种运行模式:Client 模式和 Server 模式。
- Client 模式:
- 特点:启动速度较快,占用内存较少,适用于桌面应用程序等对启动时间要求较高的场景。
- 编译器:使用 C1 编译器,进行简单和快速的优化。
- 应用场景:通常用于普通的桌面应用,如小型的 Java 应用程序。
- Server 模式:
- 特点:启动速度较慢,但运行时性能更好,适用于长时间运行的服务器端应用。
- 编译器:采用更复杂和强大的 C2 编译器,进行更深入和耗时的优化。
- 应用场景:常用于服务器端应用,如 Web 服务器、应用服务器等,能够处理高并发和大量的数据处理任务。
C1 和 C2 编译器
- C1 编译器:也称为客户端编译器(Client Compiler)。它的优化策略相对简单和快速,主要关注代码的快速生成和较短的编译时间。适用于对启动速度要求较高的场景。
- 例子:对于一些简单的循环和方法调用,C1 编译器可能会进行基本的常量折叠、消除一些冗余的计算等简单优化。
- C2 编译器:也称为服务器端编译器(Server Compiler)。它执行更深入和耗时的优化,以生成更高效的机器码。
- 例子:C2 编译器可能会进行更复杂的循环优化、内联函数、更精细的寄存器分配等,以提高代码的长期运行性能。
服务端 JVM 通常采用 Server 模式启动,主要有以下好处:
- 更优的性能优化:Server 模式下的 JVM 采用了更复杂和强大的优化策略,能够生成更高效的机器码,从而提高程序的长期运行性能。
- 更好的内存管理:有助于更有效地管理大量的内存,处理高并发和大规模的数据处理任务。
- 高级的垃圾回收算法:例如更适合服务器端应用的垃圾回收算法,减少垃圾回收带来的暂停时间,提高系统的整体响应性。
在 Server 模式启动后,同一段代码第一次运行时通常是解释执行,而不是立即编译成机器码。JVM 会通过热点探测来确定哪些代码是频繁执行的热点代码。只有被判定为热点的代码,才会在后续被编译成机器码。这样可以避免过早地对不常执行的代码进行编译,节省编译时间和资源。
例如,一个复杂的计算函数在服务端应用中被频繁调用,经过一定次数的执行后,JVM 会将其识别为热点代码并编译成机器码,从而在后续的调用中直接执行机器码,提高执行效率。但如果是一个很少被调用的辅助函数,可能始终都是解释执行。
内存泄漏
1、什么是内存泄露
存在一些对象他们是可到达的GC无法回收,但是程序之后又不会用到这些对象,对于存在这种占用内存却不会被使用的现象就叫内存泄漏
2、内存泄露的场景
1、静态集合类:如HashMap、LinkedList等静态容器,通常做缓存用,生命周期与程序一致,如果没有及时按策略清除容器中引用的对象,则会导致容器越积越大,白白占用大量内存空间(使用redis,ehcache等带LRU策略的缓存框架)
2、各种连接如数据库连接、网络连接、IO连接等等使用结束后没有及时关闭,导致连接对象无法回收
3、TreadLocal、内部类实例被引用导致外部类实例无法释放等等
4、定义太多无效类、枚举、静态常量、变量等,导致元空间占用。
OOM的原因
- 堆内存溢出(Heap Space OOM):java.lang.OutOfMemoryError: Java heap space
- 大量对象创建且未被及时回收:例如在程序中创建了大量的对象,尤其是大对象,而垃圾回收机制未能及时清理这些不再使用的对象,导致堆内存被耗尽。
- 内存泄漏:某些对象一直被引用,无法被垃圾回收,导致内存逐渐被占用完。
- 不合理的缓存:比如创建了一个过大的缓存,且缓存中的元素没有有效的过期策略。
- 元空间(方法区)溢出(Metaspace OOM):java.lang.OutOfMemoryError: Metaspace
- 加载了过多的类:在动态加载类的应用中,可能会加载大量的类,导致方法区空间不足(过多无效类,枚举)。
- 常量池过大:字符串常量过多或者其他常量占用了大量空间。
- 直接内存溢出(Direct Buffer Memory OOM):java.lang.OutOfMemoryError: Direct buffer memory
- 直接使用
ByteBuffer分配了过大的本地内存,且没有合理的释放。 - 可以通过
-XX:MaxDirectMemorySize来指定最大的直接内存大小。当直接内存的使用达到了阈值的时候,JVM 会尝试调用System.gc()来触发一次 FULL GC,从而完成可控的堆外内存回收
- 直接使用
- 线程创建过多:java.lang.OutOfMemoryError: unable to create new native thread
- 栈总内存超出系统限制
- 无限创建线程,耗尽系统内存
- 线程池使用不当,无限制创建线程
- GC 开销超限 java.lang.OutOfMemoryError: GC overhead limit exceeded 了解即可
- 数组大小超限 java.lang.OutOfMemoryError: Requested array size exceeds VM limit 了解即可
非OOM
StackOverflow 栈调用溢出
- 方法调用太深,超出jvm限制
- 代码死循环,代码终止条件异常