Maven学习
activiti整合Spring
Activiti整合Spring
activiti进阶
Activiti进阶
一、流程实例
什么是流程实例
流程实例(ProcessInstance)代表流程定义的执行实例。
一个流程实例包括了所有的运行节点。我们可以利用这个对象来了解当前流程实例的进度等信息。
例如:用户或程序按照流程定义内容发起一个流程,这就是一个流程实例。
流程定义和流程实例的图解:
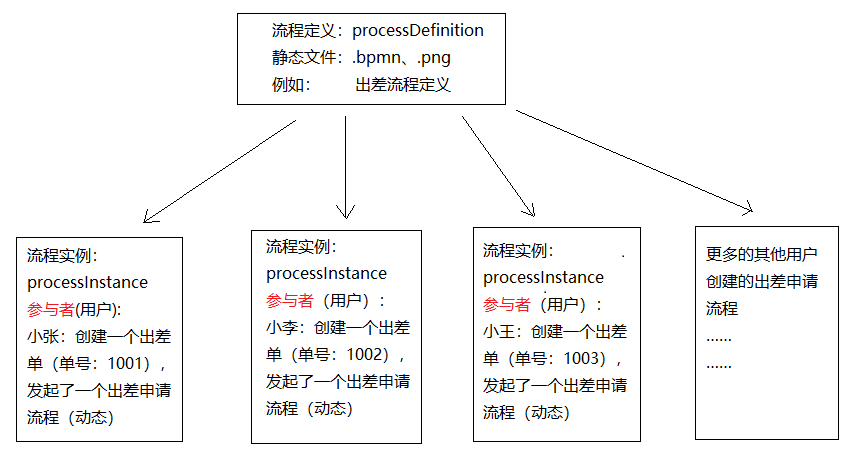
启动流程实例 并添加Businesskey(业务标识)
流程定义部署在activiti后,就可以在系统中通过activiti去管理该流程的执行,执行流程表示流程的一次执行。
比如部署系统出差流程后,如果某用户要申请出差这时就需要执行这个流程,如果另外一个用户也要申请出差则也需要执行该流程,每个执行互不影响,每个执行是单独的流程实例。
启动流程实例时,指定的businesskey,就会在act_ru_execution #流程实例的执行表中存储businesskey。
Businesskey:业务标识,通常为业务表的主键,业务标识和流程实例一一对应。业务标识来源于业务系统。存储业务标识就是根据业务标识来关联查询业务系统的数据。
比如:出差流程启动一个流程实例,就可以将出差单的id作为业务标识存储到activiti中,将来查询activiti的流程实例信息就可以获取出差单的id从而关联查询业务系统数据库得到出差单信息。
1 | |
Activiti的act_ru_execution中存储业务标识:

操作数据库表
启动流程实例,操作如下数据库表:
SELECT * FROM act_ru_execution #流程实例执行表,记录当前流程实例的执行情况

说明:
流程实例执行,如果当前只有一个分支时,一个流程实例只有一条记录且执行表的主键id和流程实例id相同,如果当前有多个分支正在运行则该执行表中有多条记录,存在执行表的主键和流程实例id不相同的记录。不论当前有几个分支总会有一条记录的执行表的主键和流程实例id相同
一个流程实例运行完成,此表中与流程实例相关的记录删除。
SELECT * FROM act_ru_task #任务执行表,记录当前执行的任务

说明:启动流程实例,流程当前执行到第一个任务结点,此表会插入一条记录表示当前任务的执行情况,如果任务完成则记录删除。
SELECT * FROM act_ru_identitylink #任务参与者,记录当前参与任务的用户或组

SELECT * FROM act_hi_procinst #流程实例历史表

流程实例启动,会在此表插入一条记录,流程实例运行完成记录也不会删除。
SELECT * FROM act_hi_taskinst #任务历史表,记录所有任务

开始一个任务,不仅在act_ru_task表插入记录,也会在历史任务表插入一条记录,任务历史表的主键就是任务id,任务完成此表记录不删除。
SELECT * FROM act_hi_actinst #活动历史表,记录所有活动

活动包括任务,所以此表中不仅记录了任务,还记录了流程执行过程的其它活动,比如开始事件、结束事件。
查询流程实例
流程在运行过程中可以查询流程实例的状态,当前运行结点等信息。
1 | |
关联BusinessKey
需求:
在activiti实际应用时,查询流程实例列表时可能要显示出业务系统的一些相关信息,比如:查询当前运行的出差流程列表需要将出差单名称、出差天数等信息显示出来,出差天数等信息在业务系统中存在,而并没有在activiti数据库中存在,所以是无法通过activiti的api查询到出差天数等信息。
实现:
在查询流程实例时,通过businessKey(业务标识 )关联查询业务系统的出差单表,查询出出差天数等信息。
通过下面的代码就可以获取activiti中所对应实例保存的业务Key。而这个业务Key一般都会保存相关联的业务操作表的主键,再通过主键ID去查询业务信息,比如通过出差单的ID,去查询更多的请假信息(出差人,出差时间,出差天数,出差目的地等)
String businessKey = processInstance.getBusinessKey();
在activiti的act_ru_execution表,字段BUSINESS_KEY就是存放业务KEY的。

挂起、激活流程实例
某些情况可能由于流程变更需要将当前运行的流程暂停而不是直接删除,流程暂停后将不会继续执行。
全部流程实例挂起
操作流程定义为挂起状态,该流程定义下边所有的流程实例全部暂停:
流程定义为挂起状态该流程定义将不允许启动新的流程实例,同时该流程定义下所有的流程实例将全部挂起暂停执行。
1 | |
单个流程实例挂起
操作流程实例对象,针对单个流程执行挂起操作,某个流程实例挂起则此流程不再继续执行,完成该流程实例的当前任务将报异常。
1 | |
二、个人任务
2.1、分配任务负责人
2.1.1、固定分配
在进行业务流程建模时指定固定的任务负责人, 如图:
并在 properties 视图中,填写 Assignee 项为任务负责人。
2.1.2、表达式分配
由于固定分配方式,任务只管一步一步执行任务,执行到每一个任务将按照 bpmn 的配置去分配任
务负责人。
2.1.2.1、UEL 表达式
Activiti 使用 UEL 表达式, UEL 是 java EE6 规范的一部分, UEL(Unified Expression Language)即 统一表达式语言, activiti 支持两个 UEL 表达式: UEL-value 和 UEL-method。
1)UEL-value 定义
如图:
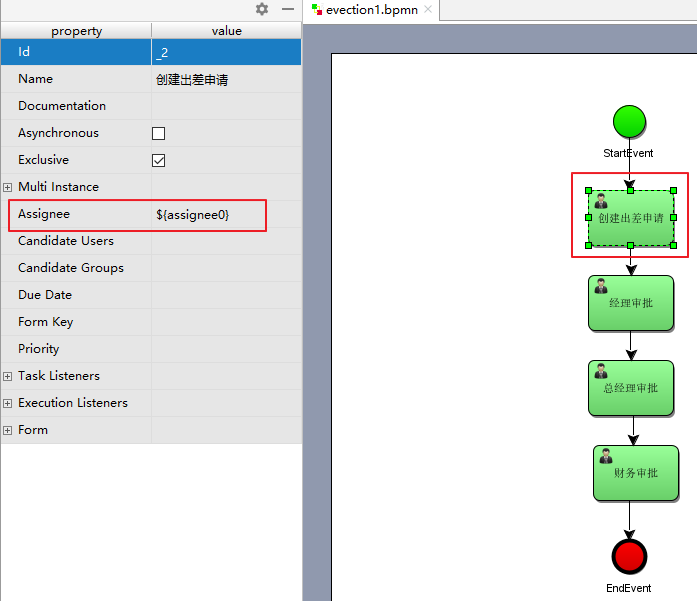
assignee 这个变量是 activiti 的一个流程变量,
或者使用这种方式定义:
如图:
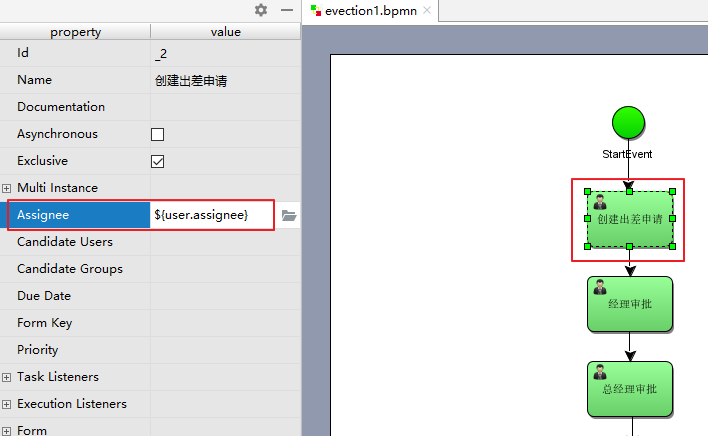
user 也是 activiti 的一个流程变量, user.assignee 表示通过调用 user 的 getter 方法获取值。
2)UEL-method 方式
如图:
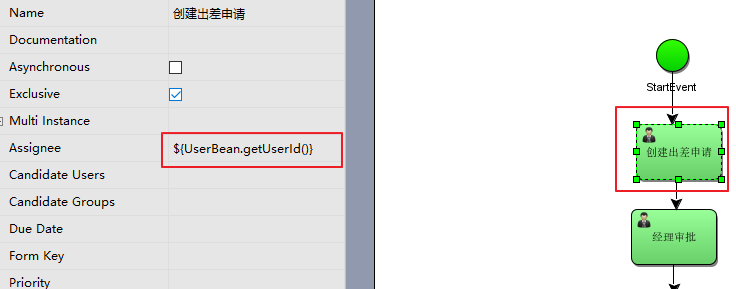
userBean 是 spring 容器中的一个 bean,表示调用该 bean 的 getUserId()方法。
3)UEL-method 与 UEL-value 结合
再比如:
${ldapService.findManagerForEmployee(emp)}
ldapService 是 spring 容器的一个 bean,findManagerForEmployee 是该 bean 的一个方法,emp 是 activiti
流程变量, emp 作为参数传到 ldapService.findManagerForEmployee 方法中。
4)其它
表达式支持解析基础类型、 bean、 list、 array 和 map,也可作为条件判断。
如下:
${order.price > 100 && order.price < 250}
2.1.2.2、编写代码配置负责人
1)定义任务分配流程变量
如图:
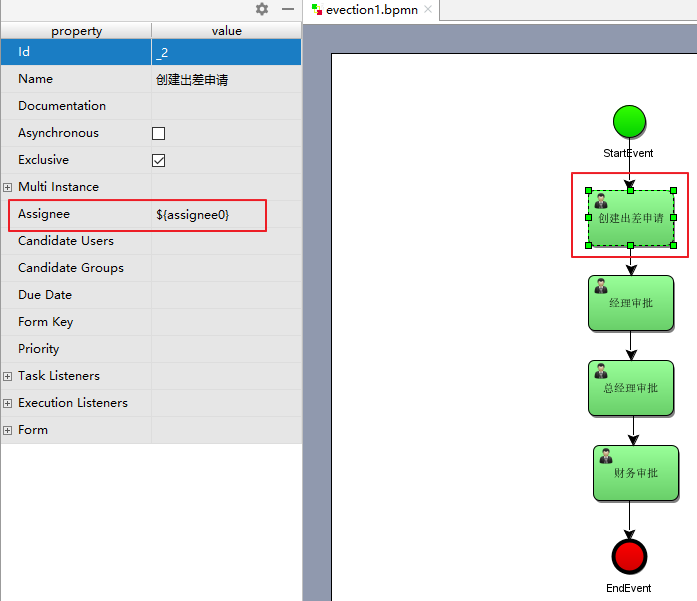
2)设置流程变量
在启动流程实例时设置流程变量,如下:
1 | |
执行成功后,可以在act_ru_variable表中看到刚才map中的数据

2.1.2.3、注意事项
由于使用了表达式分配,必须保证在任务执行过程表达式执行成功,比如:
某个任务使用了表达式${order.price > 100 && order.price < 250},当执行该任务时必须保证 order 在
流程变量中存在,否则 activiti 异常。
2.1.3、监听器分配
可以使用监听器来完成很多Activiti流程的业务。
在本章我们使用监听器的方式来指定负责人,那么在流程设计时就不需要指定assignee。
任务监听器是发生对应的任务相关事件时执行自定义 java 逻辑 或表达式。
任务相当事件包括:
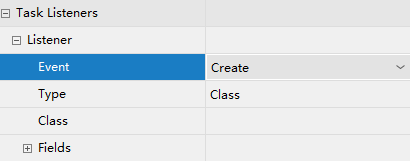
Event的选项包含:
1 | |
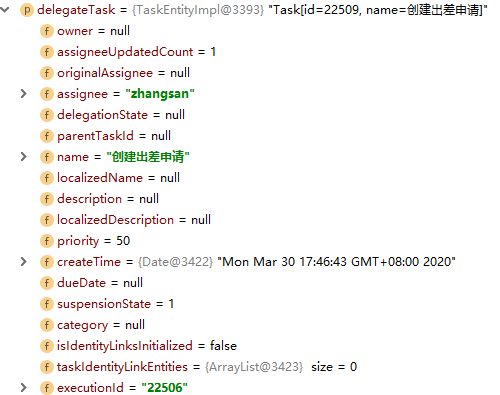
定义任务监听类,且类必须实现 org.activiti.engine.delegate.TaskListener 接口
1 | |
DelegateTask对象的内容如下:
2.1.3.1、注意事项
使用监听器分配方式,按照监听事件去执行监听类的 notify 方法,方法如果不能正常执行也会影响
任务的执行。
2.2、查询任务
查询任务负责人的待办任务
代码如下:
1 | |
关联 businessKey
需求:
在 activiti 实际应用时,查询待办任务可能要显示出业务系统的一些相关信息。
比如:查询待审批出差任务列表需要将出差单的日期、 出差天数等信息显示出来。
出差天数等信息在业务系统中存在,而并没有在 activiti 数据库中存在,所以是无法通过 activiti 的 api 查询到出差天数等信息。
实现:
在查询待办任务时,通过 businessKey(业务标识 )关联查询业务系统的出差单表,查询出出差天数等信息。
1 | |
2.3、办理任务
注意:在实际应用中,完成任务前需要校验任务的负责人是否具有该任务的办理权限 。
1 | |
三、流程变量
3.1、什么是流程变量
流程变量在 activiti 中是一个非常重要的角色,流程运转有时需要靠流程变量,业务系统和 activiti
结合时少不了流程变量,流程变量就是 activiti 在管理工作流时根据管理需要而设置的变量。
比如:在出差申请流程流转时如果出差天数大于 3 天则由总经理审核,否则由人事直接审核, 出差天
数就可以设置为流程变量,在流程流转时使用。
注意:虽然流程变量中可以存储业务数据可以通过activiti的api查询流程变量从而实现 查询业务数据,但是不建议这样使用,因为业务数据查询由业务系统负责,activiti设置流程变量是为了流程执行需要而创建。
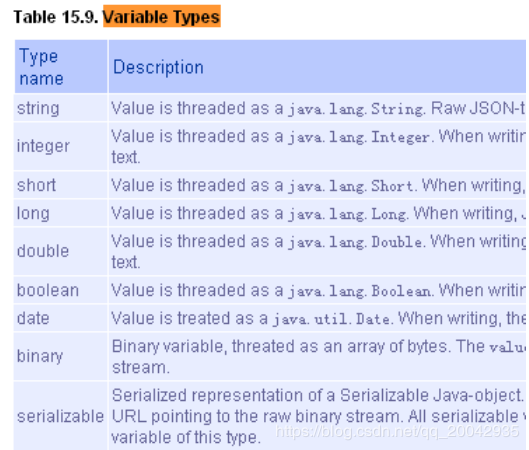
3.2、流程变量类型
如果将 pojo 存储到流程变量中,必须实现序列化接口 serializable,为了防止由于新增字段无
法反序列化,需要生成 serialVersionUID。
3.3、流程变量作用域
流程变量的作用域可以是一个流程实例(processInstance),或一个任务(task),或一个执行实例
(execution)
3.3.1、globa变量
流程变量的默认作用域是流程实例。当一个流程变量的作用域为流程实例时,可以称为 global 变量
注意:
如: Global变量:userId(变量名)、zhangsan(变量值)
global 变量中变量名不允许重复,设置相同名称的变量,后设置的值会覆盖前设置的变量值。
3.3.2、local变量
任务和执行实例仅仅是针对一个任务和一个执行实例范围,范围没有流程实例大, 称为 local 变量。
Local 变量由于在不同的任务或不同的执行实例中,作用域互不影响,变量名可以相同没有影响。Local 变量名也可以和 global 变量名相同,没有影响。
3.4、流程变量的使用方法
3.4.1、在属性上使用UEL表达式
可以在 assignee 处设置 UEL 表达式,表达式的值为任务的负责人,比如: ${assignee}, assignee 就是一个流程变量名称。
Activiti获取UEL表达式的值,即流程变量assignee的值 ,将assignee的值作为任务的负责人进行任务分配
3.4.2、在连线上使用UEL表达式
可以在连线上设置UEL表达式,决定流程走向。
比如:${price<10000} 。price就是一个流程变量名称,uel表达式结果类型为布尔类型。
如果UEL表达式是true,要决定 流程执行走向。
3.5、使用Global变量控制流程
3.5.1、需求
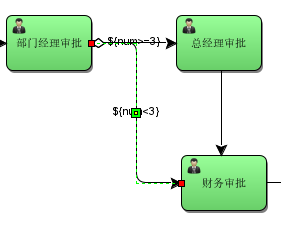
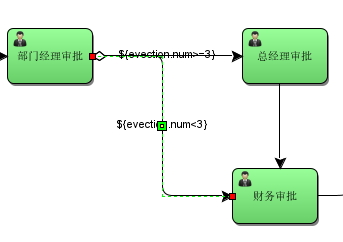
员工创建出差申请单,由部门经理审核,部门经理审核通过后出差3天及以下由人财务直接审批,3天以上先由总经理审核,总经理审核通过再由财务审批。
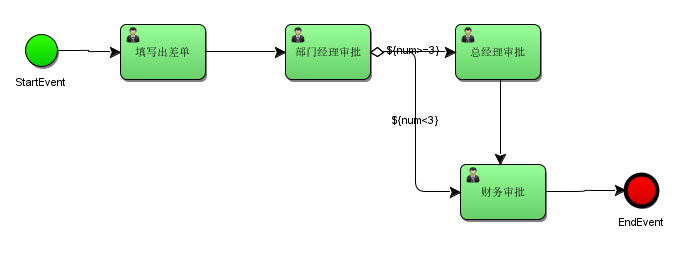
3.5.2、流程定义
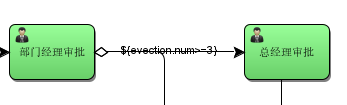
1)、出差天数大于等于3连线条件
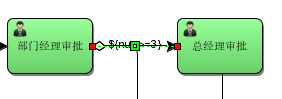

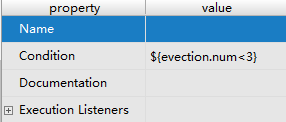
也可以使用对象参数命名,如evection.num:

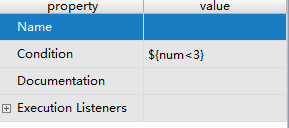
2)、出差天数小于3连线条件
也可以使用对象参数命名,如:
3.5.3、设置global流程变量
在部门经理审核前设置流程变量,变量值为出差单信息(包括出差天数),部门经理审核后可以根据流程变量的值决定流程走向。
在设置流程变量时,可以在启动流程时设置,也可以在任务办理时设置
3.5.3.1、创建POJO对象
创建出差申请pojo对象
1 | |
3.5.3.2、启动流程时设置变量
在启动流程时设置流程变量,变量的作用域是整个流程实例。
通过Map<key,value>设置流程变量,map中可以设置多个变量,这个key就是流程变量的名字。
1 | |
说明:
startProcessInstanceByKey(processDefinitionKey, variables)
流程变量作用域是一个流程实例,流程变量使用Map存储,同一个流程实例设置变量map中key相同,后者覆盖前者。
3.5.3.2、任务办理时设置变量
在完成任务时设置流程变量,该流程变量只有在该任务完成后其它结点才可使用该变量,它的作用域是整个流程实例,如果设置的流程变量的key在流程实例中已存在相同的名字则后设置的变量替换前边设置的变量。
这里需要在创建出差单任务完成时设置流程变量
1 | |
说明:
通过当前任务设置流程变量,需要指定当前任务id,如果当前执行的任务id不存在则抛出异常。
任务办理时也是通过map<key,value>设置流程变量,一次可以设置多个变量。
3.5.3.3、通过当前流程实例设置
通过流程实例id设置全局变量,该流程实例必须未执行完成。
1 | |
注意:
executionId必须当前未结束 流程实例的执行id,通常此id设置流程实例 的id。也可以通runtimeService.getVariable()获取流程变量。
3.5.3.4、通过当前任务设置
1 | |
注意:
任务id必须是当前待办任务id,act_ru_task中存在。如果该任务已结束,会报错
也可以通过taskService.getVariable()获取流程变量。
3.5.4、测试
正常测试:
设置流程变量的值大于等于3天
设计流程变量的值小于3天
异常测试:
流程变量不存在
流程变量的值为空NULL,price属性为空
UEL表达式都不符合条件
不设置连线的条件
3.5.5、注意事项
1、 如果UEL表达式中流程变量名不存在则报错。
2、 如果UEL表达式中流程变量值为空NULL,流程不按UEL表达式去执行,而流程结束 。
3、 如果UEL表达式都不符合条件,流程结束
4、 ==如果连线不设置条件,会走flow序号小的那条线==
3.5.6、操作数据库表
设置流程变量会在当前执行流程变量表插入记录,同时也会在历史流程变量表也插入记录。
1 | |
记录当前运行流程实例可使用的流程变量,包括 global和local变量
Id_:主键
Type_:变量类型
Name_:变量名称
Execution_id_:所属流程实例执行id,global和local变量都存储
Proc_inst_id_:所属流程实例id,global和local变量都存储
Task_id_:所属任务id,local变量存储
Bytearray_:serializable类型变量存储对应act_ge_bytearray表的id
Double_:double类型变量值
Long_:long类型变量值
Text_:text类型变量值
1 | |
记录所有已创建的流程变量,包括 global和local变量
字段意义参考当前流程变量表。
3.6、设置local流程变量
3.6.1、任务办理时设置
任务办理时设置local流程变量,当前运行的流程实例只能在该任务结束前使用,任务结束该变量无法在当前流程实例使用,可以通过查询历史任务查询。
1 | |
说明:
设置作用域为任务的local变量,每个任务可以设置同名的变量,互不影响。
3.6.2、通过当前任务设置
1 | |
注意:
任务id必须是当前待办任务id,act_ru_task中存在。
3.6.3、 Local变量测试1
如果上边例子中设置global变量改为设置local变量是否可行?为什么?
Local变量在任务结束后无法在当前流程实例执行中使用,如果后续的流程执行需要用到此变量则会报错。
3.6.4、 Local变量测试2
在部门经理审核、总经理审核、财务审核时设置local变量,可通过historyService查询每个历史任务时将流程变量的值也查询出来。
代码如下:
1 | |
注意:查询历史流程变量,特别是查询pojo变量需要经过反序列化,不推荐使用。
四、组任务
4.1、需求
在流程定义中在任务结点的 assignee 固定设置任务负责人,在流程定义时将参与者固定设置在.bpmn 文件中,如果临时任务负责人变更则需要修改流程定义,系统可扩展性差。
针对这种情况可以给任务设置多个候选人,可以从候选人中选择参与者来完成任务。
4.2、设置任务候选人
在流程图中任务节点的配置中设置 candidate-users(候选人),多个候选人之间用逗号分开。
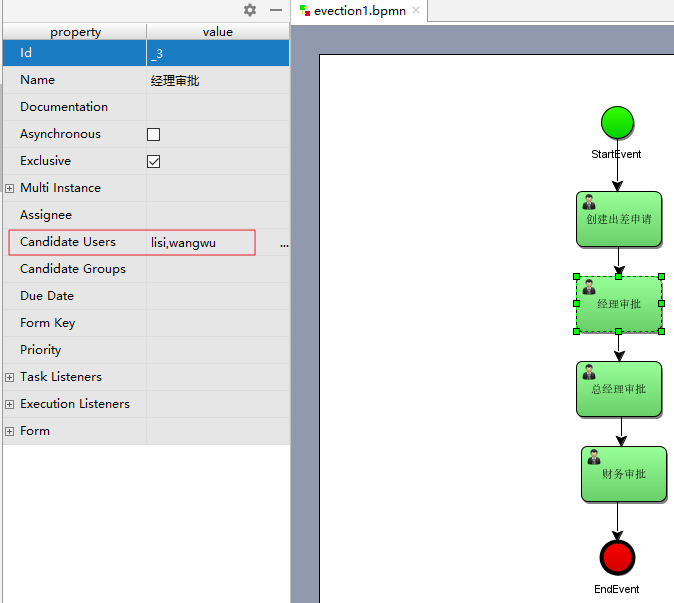
查看bpmn文件
1 | |
我们可以看到部门经理的审核人已经设置为 lisi,wangwu 这样的一组候选人,可以使用
activiti:candiateUsers=”用户 1,用户 2,用户 3”的这种方式来实现设置一组候选人
4.3、组任务
4.3.1、组任务办理流程
a、查询组任务
指定候选人,查询该候选人当前的待办任务。
候选人不能立即办理任务。
b、拾取(claim)任务
该组任务的所有候选人都能拾取。
将候选人的组任务,变成个人任务。原来候选人就变成了该任务的负责人。
如果拾取后不想办理该任务?
需要将已经拾取的个人任务归还到组里边,将个人任务变成了组任务。
c、查询个人任务
查询方式同个人任务部分,根据assignee查询用户负责的个人任务。
d、办理个人任务
4.3.2、 查询组任务
根据候选人查询组任务
1 | |
4.3.3 、 拾取组任务
候选人员拾取组任务后该任务变为自己的个人任务。
1 | |
说明:即使该用户不是候选人也能拾取,建议拾取时校验是否有资格
组任务拾取后,该任务已有负责人,通过候选人将查询不到该任务
4.3.4、 查询个人待办任务
查询方式同个人任务查询
1 | |
4.3.5、 办理个人任务
同个人任务办理
1 | |
说明:建议完成任务前校验该用户是否是该任务的负责人。
4.3.6、 归还组任务
如果个人不想办理该组任务,可以归还组任务,归还后该用户不再是该任务的负责人
1 | |
说明:建议归还任务前校验该用户是否是该任务的负责人
也可以通过setAssignee方法将任务委托给其它用户负责,注意被委托的用户可以不是候选人(建议不要这样使用)
4.3.7、 任务交接
任务交接,任务负责人将任务交给其它候选人办理该任务
1 | |
4.3.8、 数据库表操作
查询当前任务执行表
1 | |
任务执行表,记录当前执行的任务,由于该任务当前是组任务,所有assignee为空,当拾取任务后该字段就是拾取用户的id
查询任务参与者
1 | |
任务参与者,记录当前参考任务用户或组,当前任务如果设置了候选人,会向该表插入候选人记录,有几个候选就插入几个
与act_ru_identitylink对应的还有一张历史表act_hi_identitylink,向act_ru_identitylink插入记录的同时也会向历史表插入记录。任务完成
五、网关
网关用来控制流程的流向
5.1 排他网关ExclusiveGateway
5.1.1 什么是排他网关:
排他网关,用来在流程中实现决策。 当流程执行到这个网关,所有分支都会判断条件是否为true,如果为true则执行该分支,
注意:**==排他网关只会选择一个为true的分支执行。如果有两个分支条件都为true,排他网关会选择id值较小的一条分支去执行,如果条件都为false,则抛出异常==**。
为什么要用排他网关?
不用排他网关也可以实现分支,如:在连线的condition条件上设置分支条件。
在连线设置condition条件的缺点:如果条件都不满足,流程就结束了(是异常结束)。
如果 使用排他网关决定分支的走向,如下:
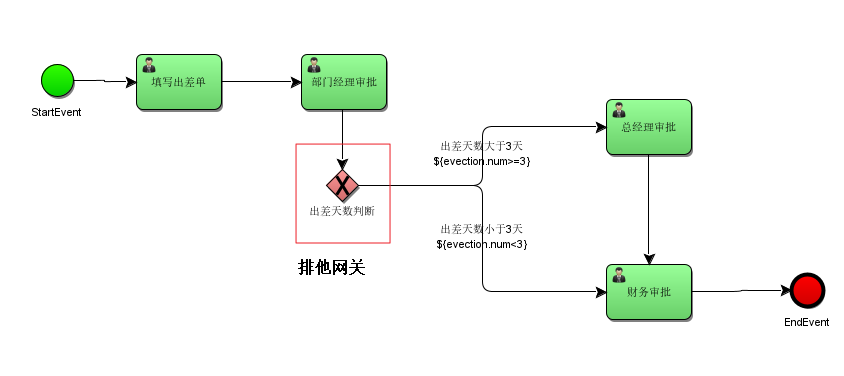
如果从网关出去的线所有条件都不满足则系统抛出异常。
1 | |
5.1.2 流程定义
排他网关图标,红框内:

5.1.3 测试
在部门经理审核后,走排他网关,从排他网关出来的分支有两条,一条是判断出差天数是否大于3天,另一条是判断出差天数是否小于等于3天。
设置分支条件时,如果所有分支条件都不是true,报错:
1 | |
5.2 并行网关ParallelGateway
5.2.1 什么是并行网关
并行网关允许将流程分成多条分支,也可以把多条分支汇聚到一起,并行网关的功能是基于进入和外出顺序流的:
l fork分支:
并行后的所有外出顺序流,为每个顺序流都创建一个并发分支。
l join汇聚:
所有到达并行网关,在此等待的进入分支, 直到所有进入顺序流的分支都到达以后, 流程就会通过汇聚网关。
注意,如果同一个并行网关有多个进入和多个外出顺序流, 它就同时具有分支和汇聚功能。 这时,网关会先汇聚所有进入的顺序流,然后再切分成多个并行分支。
与其他网关的主要区别是,并行网关不会解析条件。 即使顺序流中定义了条件,也会被忽略。
例子:
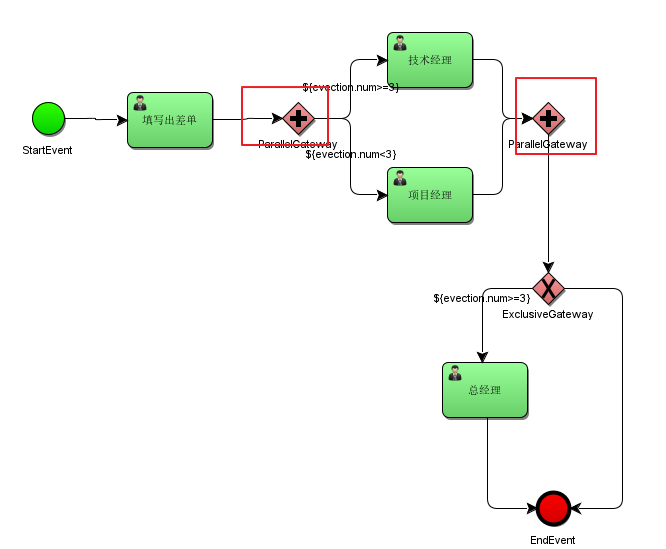
说明:
技术经理和项目经理是两个execution分支,在act_ru_execution表有两条记录分别是技术经理和项目经理,act_ru_execution还有一条记录表示该流程实例。
待技术经理和项目经理任务全部完成,在汇聚点汇聚,通过parallelGateway并行网关。
并行网关在业务应用中常用于会签任务,会签任务即多个参与者共同办理的任务。
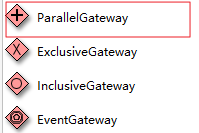
5.2.2 流程定义
并行网关图标,红框内:
5.2.3 测试
当执行到并行网关数据库跟踪如下:
当前任务表:SELECT * FROM act_ru_task

上图中:有两个任务当前执行。
查询流程实例执行表:SELECT * FROM act_ru_execution

上图中,说明当前流程实例有多个分支(两个)在运行。
对并行任务的执行:
并行任务执行不分前后,由任务的负责人去执行即可。
执行技术经理任务后,查询当前任务表 SELECT * FROM act_ru_task

已完成的技术经理任务在当前任务表act_ru_task_已被删除。
在流程实例执行表:SELECT * FROM act_ru_execution有中多个分支存在且有并行网关的汇聚结点。

有并行网关的汇聚结点:说明有一个分支已经到汇聚,等待其它的分支到达。
当所有分支任务都完成,都到达汇聚结点后:
流程实例执行表:SELECT * FROM act_ru_execution,执行流程实例已经变为总经理审批,说明流程执行已经通过并行网关

总结:所有分支到达汇聚结点,并行网关执行完成。
5.3 包含网关InclusiveGateway
5.3.1 什么是包含网关
包含网关可以看做是排他网关和并行网关的结合体。
和排他网关一样,你可以在外出顺序流上定义条件,包含网关会解析它们。 但是主要的区别是包含网关可以选择多于一条顺序流,这和并行网关一样。
包含网关的功能是基于进入和外出顺序流的:
l 分支:
所有外出顺序流的条件都会被解析,结果为true的顺序流会以并行方式继续执行, 会为每个顺序流创建一个分支。
l 汇聚:
所有并行分支到达包含网关,会进入等待状态, 直到每个包含流程token的进入顺序流的分支都到达。 这是与并行网关的最大不同。换句话说,包含网关只会等待被选中执行了的进入顺序流。 在汇聚之后,流程会穿过包含网关继续执行。
5.3.2 流程定义:
出差申请大于等于3天需要由项目经理审批,小于3天由技术经理审批,出差申请必须经过人事经理审批。
包含网关图标,红框内:

定义流程:
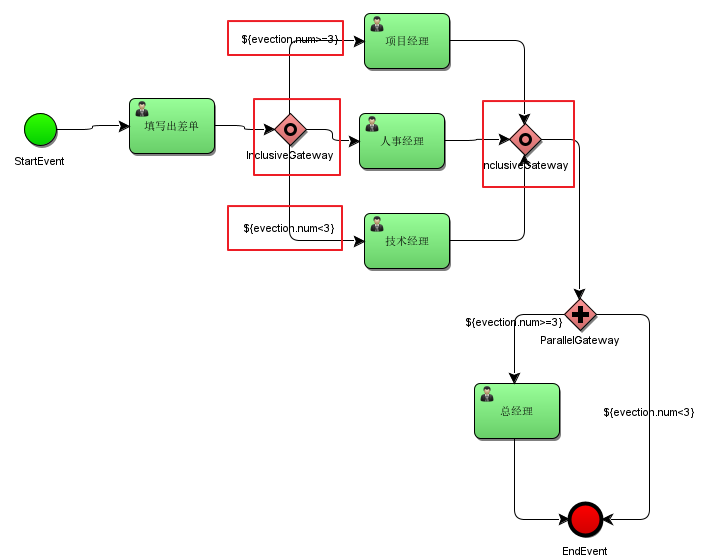
注意:通过包含网关的每个分支的连线上设置condition条件。
5.3.3 测试
如果包含网关设置的条件中,流程变量不存在,报错;
1 | |
需要在流程启动时设置流程变量evection.num。
1)、当流程执行到第一个包含网关后,会根据条件判断,当前要走哪几个分支:
流程实例执行表:SELECT * FROM act_ru_execution

第一条记录:包含网关分支。
后两条记录代表两个要执行的分支:
ACT_ID = “_13” 代表 项目经理神品
ACT_ID = “_5” 代表 人事经理审批
当前任务表:ACT_RU_TASK

上图中,项目经理审批、人事经理审批 都是当前的任务,在并行执行。
如果有一个分支执行先走到汇聚结点的分支,要等待其它执行分支走到汇聚。
2)、先执行项目经理审批,然后查询当前任务表:ACT_RU_TASK

当前任务还有人事经理审批需要处理。
流程实例执行表:SELECT * FROM act_ru_execution

发现人事经理的分支还存在,而项目经理分支已经走到ACT_ID = _18的节点。而ACT_ID=__18就是第二个包含网关
这时,因为有2个分支要执行,包含网关会等所有分支走到汇聚才能执行完成。
3)、执行人事经理审批
然后查询当前任务表:ACT_RU_TASK

当前任务表已经不是人事经理审批了,说明人事经理审批已经完成。
流程实例执行表:SELECT * FROM act_ru_execution

包含网关执行完成,分支和汇聚就从act_ru_execution删除。
小结:在分支时,需要判断条件,符合条件的分支,将会执行,符合条件的分支最终才进行汇聚。
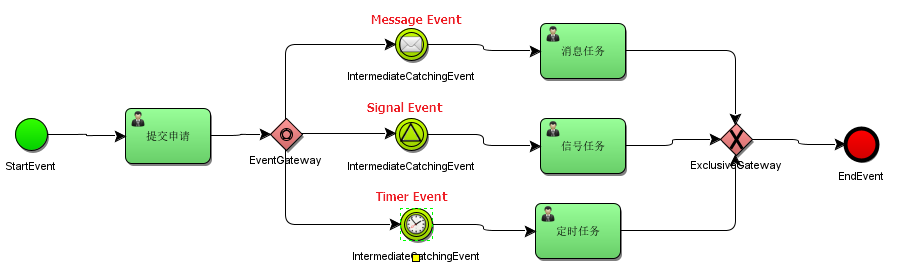
5.4 事件网关EventGateway
事件网关允许根据事件判断流向。网关的每个外出顺序流都要连接到一个中间捕获事件。 当流程到达一个基于事件网关,网关会进入等待状态:会暂停执行。与此同时,会为每个外出顺序流创建相对的事件订阅。
事件网关的外出顺序流和普通顺序流不同,这些顺序流不会真的”执行”, 相反它们让流程引擎去决定执行到事件网关的流程需要订阅哪些事件。 要考虑以下条件:
- 事件网关必须有两条或以上外出顺序流;
- 事件网关后,只能使用intermediateCatchEvent类型(activiti不支持基于事件网关后连接ReceiveTask)
- 连接到事件网关的中间捕获事件必须只有一个入口顺序流。
5.4.1流程定义
事件网关图标,红框内

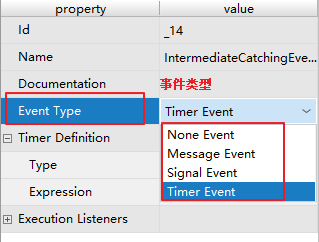
intermediateCatchEvent:
intermediateCatchEvent支持的事件类型:
Message Event: 消息事件
Singal Event: 信号事件
Timer Event: 定时事件
使用事件网关定义流程:
5.5 排他、并行、包含网关的区别
5.5.1 排他网关:
只有一个分支为true能执行,如果都为true,则执行flowid娇小的那个分支,如果都为false,则报错异常结束
5.5.2 并行网关:
允许有多个fork分支进入(此时在连线上无论true,flase都会执行,即连线判断无效),等待所有分支join汇聚后才尽心下一步操作。
5.5.3 包含网关:
允许有多个fork分支进入(此时在连线上判断条件是true或者无设置条件的都会执行),等待所有分支join汇聚后才尽心下一步操作。
activiti基础
Activiti7
一、工作流介绍
1.1 概念
工作流(Workflow),就是通过计算机对业务流程自动化执行管理。它主要解决的是“使在多个参与者之间按照某种预定义的规则自动进行传递文档、信息或任务的过程,从而实现某个预期的业务目标,或者促使此目标的实现”。
1.2 工作流系统
一个软件系统中具有工作流的功能,我们把它称为工作流系统,一个系统中工作流的功能是什么?就是对系统的业务流程进行自动化管理,所以工作流是建立在业务流程的基础上,所以一个软件的系统核心根本上还是系统的业务流程,工作流只是协助进行业务流程管理。即使没有工作流业务系统也可以开发运行,只不过有了工作流可以更好的管理业务流程,提高系统的可扩展性。
1.3 适用行业
消费品行业,制造业,电信服务业,银证险等金融服务业,物流服务业,物业服务业,物业管理,大中型进出口贸易公司,政府事业机构,研究院所及教育服务业等,特别是大的跨国企业和集团公司。
1.4 具体应用
1、关键业务流程:订单、报价处理、合同审核、客户电话处理、供应链管理等
2、行政管理类:出差申请、加班申请、请假申请、用车申请、各种办公用品申请、购买申请、日报周报等凡是原来手工流转处理的行政表单。
3、人事管理类:员工培训安排、绩效考评、职位变动处理、员工档案信息管理等。
4、财务相关类:付款请求、应收款处理、日常报销处理、出差报销、预算和计划申请等。
5、客户服务类:客户信息管理、客户投诉、请求处理、售后服务管理等。
6、特殊服务类:ISO系列对应流程、质量管理对应流程、产品数据信息管理、贸易公司报关处理、物流公司货物跟踪处理等各种通过表单逐步手工流转完成的任务均可应用工作流软件自动规范地实施。
1.5 实现方式
在没有专门的工作流引擎之前,我们之前为了实现流程控制,通常的做法就是采用状态字段的值来跟踪流程的变化情况。这样不用角色的用户,通过状态字段的取值来决定记录是否显示。
针对有权限可以查看的记录,当前用户根据自己的角色来决定审批是否合格的操作。如果合格将状态字段设置一个值,来代表合格;当然如果不合格也需要设置一个值来代表不合格的情况。
这是一种最为原始的方式。通过状态字段虽然做到了流程控制,但是当我们的流程发生变更的时候,这种方式所编写的代码也要进行调整。
那么有没有专业的方式来实现工作流的管理呢?并且可以做到业务流程变化之后,我们的程序可以不用改变,如果可以实现这样的效果,那么我们的业务系统的适应能力就得到了极大提升。
二、Activiti7概述
2.1 介绍
Alfresco软件在2010年5月17日宣布Activiti业务流程管理(BPM)开源项目的正式启动,其首席架构师由业务流程管理BPM的专家 Tom Baeyens担任,Tom Baeyens就是原来jbpm的架构师,而jbpm是一个非常有名的工作流引擎,当然activiti也是一个工作流引擎。
Activiti是一个工作流引擎, activiti可以将业务系统中复杂的业务流程抽取出来,使用专门的建模语言BPMN2.0进行定义,业务流程按照预先定义的流程进行执行,实现了系统的流程由activiti进行管理,减少业务系统由于流程变更进行系统升级改造的工作量,从而提高系统的健壮性,同时也减少了系统开发维护成本。
官方网站:https://www.activiti.org/

经历的版本:
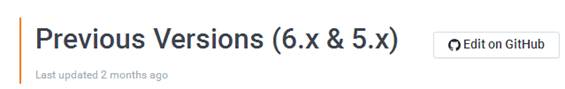
目前最新版本:Activiti7.0.0.Beta
2.1.1 BPM
BPM(Business Process Management),即业务流程管理,是一种规范化的构造端到端的业务流程,以持续的提高组织业务效率。常见商业管理教育如EMBA、MBA等均将BPM包含在内。
2.1.2 BPM软件
BPM软件就是根据企业中业务环境的变化,推进人与人之间、人与系统之间以及系统与系统之间的整合及调整的经营方法与解决方案的IT工具。
通过BPM软件对企业内部及外部的业务流程的整个生命周期进行建模、自动化、管理监控和优化,使企业成本降低,利润得以大幅提升。
BPM软件在企业中应用领域广泛,凡是有业务流程的地方都可以BPM软件进行管理,比如企业人事办公管理、采购流程管理、公文审批流程管理、财务管理等。
2.1.3 BPMN
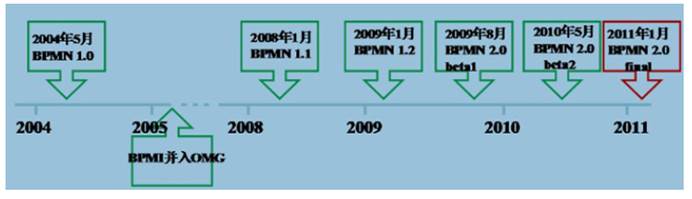
BPMN(Business Process Model AndNotation)- 业务流程模型和符号 是由BPMI(BusinessProcess Management Initiative)开发的一套标准的业务流程建模符号,使用BPMN提供的符号可以创建业务流程。
2004年5月发布了BPMN1.0规范.BPMI于2005年9月并入OMG(The Object Management Group对象管理组织)组织。OMG于2011年1月发布BPMN2.0的最终版本。
具体发展历史如下:
BPMN 是目前被各 BPM 厂商广泛接受的 BPM 标准。Activiti 就是使用 BPMN 2.0 进行流程建模、流程执行管理,它包括很多的建模符号,比如:
Event
用一个圆圈表示,它是流程中运行过程中发生的事情。

活动用圆角矩形表示,一个流程由一个活动或多个活动组成
Bpmn图形其实是通过xml表示业务流程,上边的.bpmn文件使用文本编辑器打开:
1 | |
2.2 使用步骤
部署activiti
Activiti是一个工作流引擎(其实就是一堆jar包API),业务系统访问(操作)activiti的接口,就可以方便的操作流程相关数据,这样就可以把工作流环境与业务系统的环境集成在一起。
流程定义
使用activiti流程建模工具(activity-designer)定义业务流程(.bpmn文件) 。
.bpmn文件就是业务流程定义文件,通过xml定义业务流程。
流程定义部署
activiti部署业务流程定义(.bpmn文件)。
使用activiti提供的api把流程定义内容存储起来,在Activiti执行过程中可以查询定义的内容
Activiti执行把流程定义内容存储在数据库中
启动一个流程实例
流程实例也叫:ProcessInstance
启动一个流程实例表示开始一次业务流程的运行。
在员工请假流程定义部署完成后,如果张三要请假就可以启动一个流程实例,如果李四要请假也启动一个流程实例,两个流程的执行互相不影响。
用户查询待办任务(Task)
因为现在系统的业务流程已经交给activiti管理,通过activiti就可以查询当前流程执行到哪了,当前用户需要办理什么任务了,这些activiti帮我们管理了,而不需要开发人员自己编写在sql语句查询。
用户办理任务
用户查询待办任务后,就可以办理某个任务,如果这个任务办理完成还需要其它用户办理,比如采购单创建后由部门经理审核,这个过程也是由activiti帮我们完成了。
流程结束
当任务办理完成没有下一个任务结点了,这个流程实例就完成了。
三、Activiti环境
3.1 开发环境
Jdk1.8或以上版本
Mysql 5及以上的版本
Tomcat8.5
IDEA
注意:activiti的流程定义工具插件可以安装在IDEA下,也可以安装在Eclipse工具下
3.2 Activiti环境
我们使用:Activiti7.0.0.Beta1 默认支持spring5
3.2.1 下载activiti7
Activiti下载地址:http://activiti.org/download.html ,Maven的依赖如下:
1 | |
1) Database:
activiti运行需要有数据库的支持,支持的数据库有:h2, mysql, oracle, postgres, mssql, db2。
3.2.2 流程设计器IDEA下安装
在IDEA的File菜单中找到子菜单”Settings”,后面我们再选择左侧的“plugins”菜单,如下图所示:
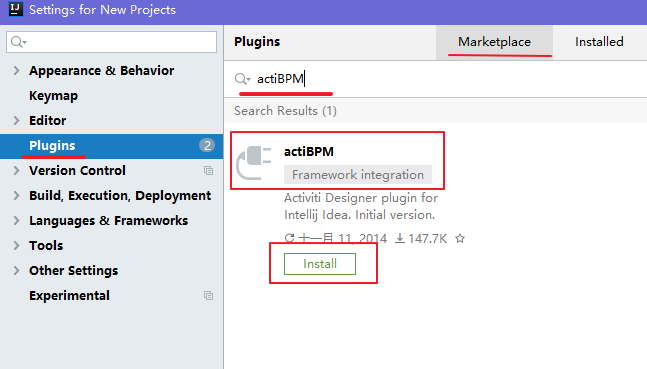
此时我们就可以搜索到actiBPM插件,它就是Activiti Designer的IDEA版本,我们点击Install安装。
安装好后,页面如下:
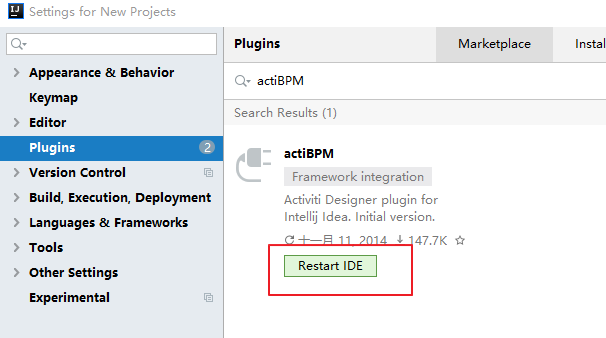
提示需要重启idea,点击重启。
重启完成后,再次打开Settings 下的 Plugins(插件列表),点击右侧的Installed(已安装的插件),在列表中看到actiBPM,就说明已经安装成功了,如下图所示:
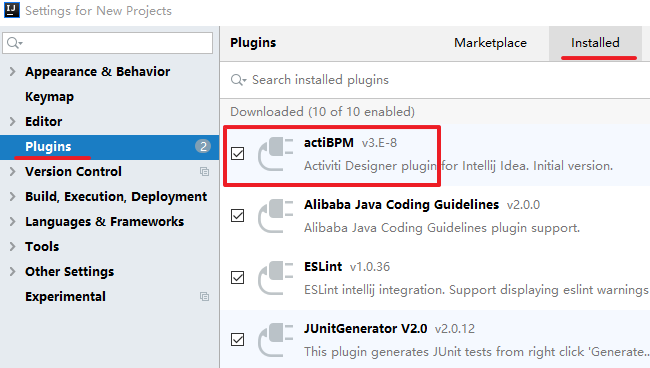
后面的课程里,我们会使用这个流程设计器进行Activiti的流程设计。
3.2.3 Eclipse activiti-designer插件
3.3 Activiti的数据库支持
Activiti 在运行时需要数据库的支持,使用25张表,把流程定义节点内容读取到数据库表中,以供后续使用。
3.3.1 Activiti 支持的数据库
activiti 支持的数据库和版本如下:
| 数据库类型 | 版本 | JDBC连接示例 | 说明 |
|---|---|---|---|
| h2 | 1.3.168 | jdbc:h2:tcp://localhost/activiti | 默认配置的数据库 |
| mysql | 5.1.21 | jdbc:mysql://localhost:3306/activiti?autoReconnect=true | 使用 mysql-connector-java 驱动测试 |
| oracle | 11.2.0.1.0 | jdbc:oracle:thin:@localhost:1521:xe | |
| postgres | 8.1 | jdbc:postgresql://localhost:5432/activiti | |
| db2 | DB2 10.1 using db2jcc4 | jdbc:db2://localhost:50000/activiti | |
| mssql | 2008 using sqljdbc4 | jdbc:sqlserver://localhost:1433/activiti |
3.3.2 在MySQL生成表
3.3.2.1 创建数据库
创建 mysql 数据库 activiti (名字任意):
CREATE DATABASE activiti DEFAULT CHARACTER SET utf8;
3.3.2.2 使用java代码生成表
1) 创建 java 工程
使用idea 创建 java 的maven工程,取名:activiti01。
2) 加入 maven 依赖的坐标(jar 包)
首先需要在 java 工程中加入 ProcessEngine 所需要的 jar 包,包括:
activiti-engine-7.0.0.beta1.jar
activiti 依赖的 jar 包: mybatis、 alf4j、 log4j 等
activiti 依赖的 spring 包
mysql数据库驱动
第三方数据连接池 dbcp
单元测试 Junit-4.12.jar
我们使用 maven 来实现项目的构建,所以应当导入这些 jar 所对应的坐标到 pom.xml 文件中。
完整的依赖内容如下:
1 | |
3) 添加log4j日志配置
我们使用log4j日志包,可以对日志进行配置
在resources 下创建log4j.properties
1 | |
4) 添加activiti配置文件
我们使用activiti提供的默认方式来创建mysql的表。
默认方式的要求是在 resources 下创建 activiti.cfg.xml 文件,注意:默认方式目录和文件名不能修改,因为activiti的源码中已经设置,到固定的目录读取固定文件名的文件。
1 | |
5) 在 activiti.cfg.xml 中进行配置
默认方式要在在activiti.cfg.xml中bean的名字叫processEngineConfiguration,名字不可修改
在这里有2中配置方式:一种是单独配置数据源,一种是不单独配置数据源
1、直接配置processEngineConfiguration
processEngineConfiguration 用来创建 ProcessEngine,在创建 ProcessEngine 时会执行数据库的操作。
1 | |
2、配置数据源后,在processEngineConfiguration 引用
首先配置数据源
1 | |
6) java类编写程序生成表
创建一个测试类,调用activiti的工具类,生成acitivti需要的数据库表。
直接使用activiti提供的工具类ProcessEngines,会默认读取classpath下的activiti.cfg.xml文件,读取其中的数据库配置,创建 ProcessEngine,在创建ProcessEngine 时会自动创建表。
代码如下:
1 | |
说明:
1、运行以上程序段即可完成 activiti 表创建,通过改变 activiti.cfg.xml 中databaseSchemaUpdate 参数的值执行不同的数据表处理策略。
2 、 上 边 的 方法 getDefaultProcessEngine方法在执行时,从activiti.cfg.xml 中找固定的名称 processEngineConfiguration 。
在测试程序执行过程中,idea的控制台会输出日志,说明程序正在创建数据表,类似如下,注意红线内容:
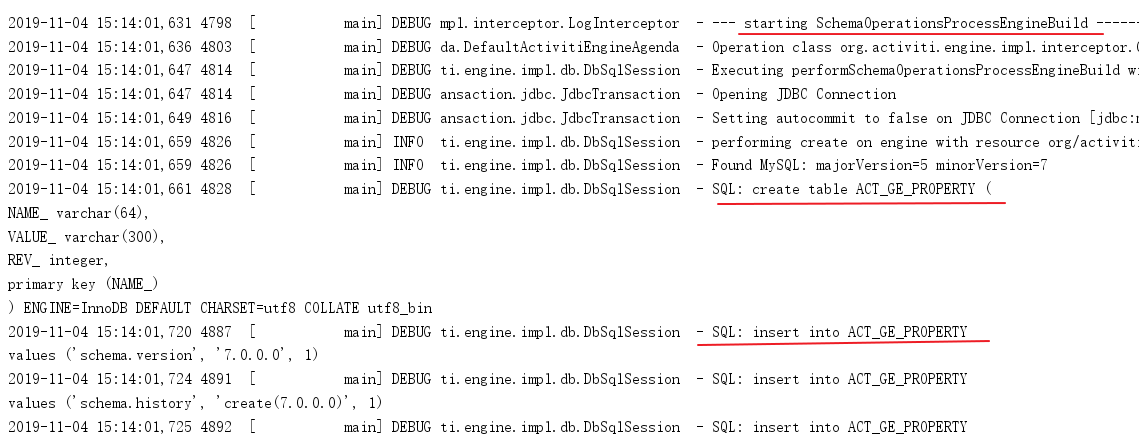
执行完成后我们查看数据库, 创建了 25 张表,结果如下:
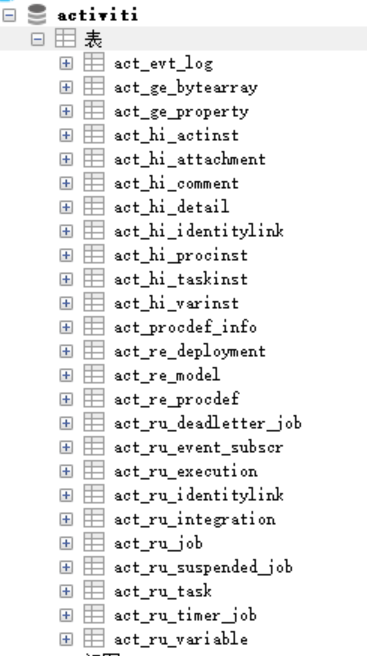
到这,我们就完成activiti运行需要的数据库和表的创建。
3.4 表结构介绍
3.4.1 表的命名规则和作用
看到刚才创建的表,我们发现Activiti 的表都以 ACT_ 开头。
第二部分是表示表的用途的两个字母标识。 用途也和服务的 API 对应。
ACT_RE :’RE’表示 repository。 这个前缀的表包含了流程定义和流程静态资源 (图片,规则,等等)。
ACT_RU:’RU’表示 runtime。 这些运行时的表,包含流程实例,任务,变量,异步任务,等运行中的数据。 Activiti 只在流程实例执行过程中保存这些数据, 在流程结束时就会删除这些记录。 这样运行时表可以一直很小速度很快。
ACT_HI:’HI’表示 history。 这些表包含历史数据,比如历史流程实例, 变量,任务等等。
ACT_GE : GE 表示 general。 通用数据, 用于不同场景下
3.4.2 Activiti数据表介绍
| 表分类 | 表名 | 解释 |
|---|---|---|
| 一般数据 | ||
| [ACT_GE_BYTEARRAY] | 通用的流程定义和流程资源 | |
| [ACT_GE_PROPERTY] | 系统相关属性 | |
| 流程历史记录 | ||
| [ACT_HI_ACTINST] | 历史的流程实例 | |
| [ACT_HI_ATTACHMENT] | 历史的流程附件 | |
| [ACT_HI_COMMENT] | 历史的说明性信息 | |
| [ACT_HI_DETAIL] | 历史的流程运行中的细节信息 | |
| [ACT_HI_IDENTITYLINK] | 历史的流程运行过程中用户关系 | |
| [ACT_HI_PROCINST] | 历史的流程实例 | |
| [ACT_HI_TASKINST] | 历史的任务实例 | |
| [ACT_HI_VARINST] | 历史的流程运行中的变量信息 | |
| 流程定义表 | ||
| [ACT_RE_DEPLOYMENT] | 部署单元信息 | |
| [ACT_RE_MODEL] | 模型信息 | |
| [ACT_RE_PROCDEF] | 已部署的流程定义 | |
| 运行实例表 | ||
| [ACT_RU_EVENT_SUBSCR] | 运行时事件 | |
| [ACT_RU_EXECUTION] | 运行时流程执行实例 | |
| [ACT_RU_IDENTITYLINK] | 运行时用户关系信息,存储任务节点与参与者的相关信息 | |
| [ACT_RU_JOB] | 运行时作业 | |
| [ACT_RU_TASK] | 运行时任务 | |
| [ACT_RU_VARIABLE] | 运行时变量表 |
四、Activiti类关系图
上面我们完成了Activiti数据库表的生成,java代码中我们调用Activiti的工具类,下面来了解Activiti的类关系
4.1 类关系图
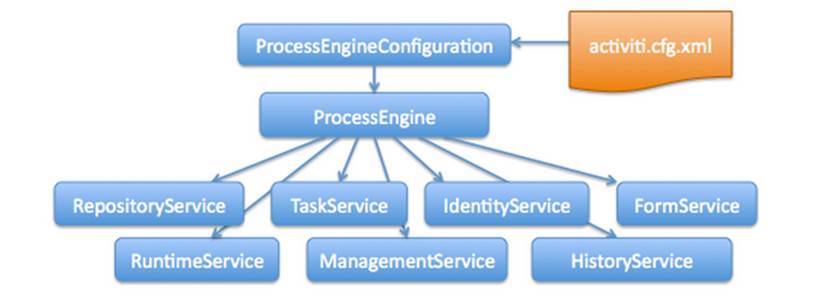
在新版本中,我们通过实验可以发现IdentityService,FormService两个Serivce都已经删除了。
所以后面我们对于这两个Service也不讲解了,但老版本中还是有这两个Service,同学们需要了解一下
4.2 activiti.cfg.xml
activiti的引擎配置文件,包括:ProcessEngineConfiguration的定义、数据源定义、事务管理器等,此文件其实就是一个spring配置文件。
4.3 流程引擎配置类
流程引擎的配置类(ProcessEngineConfiguration),通过ProcessEngineConfiguration可以创建工作流引擎ProceccEngine,常用的两种方法如下:
4.3.1 StandaloneProcessEngineConfiguration
使用StandaloneProcessEngineConfigurationActiviti可以单独运行,来创建ProcessEngine,Activiti会自己处理事务。
配置文件方式:
通常在activiti.cfg.xml配置文件中定义一个id为 processEngineConfiguration 的bean.
方法如下:
1 | |
还可以加入连接池:
1 | |
4.3.2 SpringProcessEngineConfiguration
通过org.activiti.spring.SpringProcessEngineConfiguration 与==Spring整合==。
创建spring与activiti的整合配置文件:
activity-spring.cfg.xml(名称可修改)
1 | |
创建processEngineConfiguration
1 | |
上边的代码要求activiti.cfg.xml中必须有一个processEngineConfiguration的bean
也可以使用下边的方法,更改bean 的名字:
1 | |
4.4 工作流引擎创建
工作流引擎(ProcessEngine),相当于一个门面接口,通过ProcessEngineConfiguration创建processEngine,通过ProcessEngine创建各个service接口。
4.4.1 默认创建方式
将activiti.cfg.xml文件名及路径固定,且activiti.cfg.xml文件中有 processEngineConfiguration的配置, 可以使用如下代码创建processEngine:
1 | |
4.4.2 一般创建方式
1 | |
4.5 Servcie服务接口
Service是工作流引擎提供用于进行工作流部署、执行、管理的服务接口,我们使用这些接口可以就是操作服务对应的数据表
4.5.1 Service创建方式
通过ProcessEngine创建Service
方式如下:
1 | |
4.5.2 Service总览
| service名称 | service作用 |
|---|---|
| RepositoryService | activiti的资源管理类 |
| RuntimeService | activiti的流程运行管理类 |
| TaskService | activiti的任务管理类 |
| HistoryService | activiti的历史管理类 |
| ManagerService | activiti的引擎管理类 |
简单介绍:
RepositoryService
是activiti的资源管理类,提供了管理和控制流程发布包和流程定义的操作。使用工作流建模工具设计的业务流程图需要使用此service将流程定义文件的内容部署到计算机。
除了部署流程定义以外还可以:查询引擎中的发布包和流程定义。
暂停或激活发布包,对应全部和特定流程定义。 暂停意味着它们不能再执行任何操作了,激活是对应的反向操作。获得多种资源,像是包含在发布包里的文件, 或引擎自动生成的流程图。
获得流程定义的pojo版本, 可以用来通过java解析流程,而不必通过xml。
RuntimeService
Activiti的流程运行管理类。可以从这个服务类中获取很多关于流程执行相关的信息
TaskService
Activiti的任务管理类。可以从这个类中获取任务的信息。
HistoryService
Activiti的历史管理类,可以查询历史信息,执行流程时,引擎会保存很多数据(根据配置),比如流程实例启动时间,任务的参与者, 完成任务的时间,每个流程实例的执行路径,等等。 这个服务主要通过查询功能来获得这些数据。
ManagementService
Activiti的引擎管理类,提供了对 Activiti 流程引擎的管理和维护功能,这些功能不在工作流驱动的应用程序中使用,主要用于 Activiti 系统的日常维护。
五、Activiti入门
在本章内容中,我们来创建一个Activiti工作流,并启动这个流程。
创建Activiti工作流主要包含以下几步:
1、定义流程,按照BPMN的规范,使用流程定义工具,用流程符号把整个流程描述出来
2、部署流程,把画好的流程定义文件,加载到数据库中,生成表的数据
3、启动流程,使用java代码来操作数据库表中的内容
5.1 流程符号
BPMN 2.0是业务流程建模符号2.0的缩写。
它由Business Process Management Initiative这个非营利协会创建并不断发展。作为一种标识,BPMN 2.0是使用一些符号来明确业务流程设计流程图的一整套符号规范,它能增进业务建模时的沟通效率。
目前BPMN2.0是最新的版本,它用于在BPM上下文中进行布局和可视化的沟通。
接下来我们先来了解在流程设计中常见的 符号。
BPMN2.0的基本符合主要包含:
事件 Event

活动 Activity
活动是工作或任务的一个通用术语。一个活动可以是一个任务,还可以是一个当前流程的子处理流程; 其次,你还可以为活动指定不同的类型。常见活动如下:

网关 GateWay
网关用来处理决策,有几种常用网关需要了解:

排他网关 (x)
——只有一条路径会被选择。流程执行到该网关时,按照输出流的顺序逐个计算,当条件的计算结果为true时,继续执行当前网关的输出流;
如果多条线路计算结果都是 true,则会执行第一个值为 true 的线路。如果所有网关计算结果没有true,则引擎会抛出异常。
排他网关需要和条件顺序流结合使用,default 属性指定默认顺序流,当所有的条件不满足时会执行默认顺序流。
并行网关 (+)
——所有路径会被同时选择
拆分 —— 并行执行所有输出顺序流,为每一条顺序流创建一个并行执行线路。
合并 —— 所有从并行网关拆分并执行完成的线路均在此等候,直到所有的线路都执行完成才继续向下执行。
包容网关 (+)
—— 可以同时执行多条线路,也可以在网关上设置条件
拆分 —— 计算每条线路上的表达式,当表达式计算结果为true时,创建一个并行线路并继续执行
合并 —— 所有从并行网关拆分并执行完成的线路均在此等候,直到所有的线路都执行完成才继续向下执行。
事件网关 (+)
—— 专门为中间捕获事件设置的,允许设置多个输出流指向多个不同的中间捕获事件。当流程执行到事件网关后,流程处于等待状态,需要等待抛出事件才能将等待状态转换为活动状态。
流向 Flow
流是连接两个流程节点的连线。常见的流向包含以下几种:

5.2 流程设计器使用
Activiti-Designer使用
Palette(画板)
在idea中安装插件即可使用,画板中包括以下结点:
Connection—连接
Event—事件
Task—任务
Gateway—网关
Container—容器
Boundary event—边界事件
Intermediate event- -中间事件
流程图设计完毕保存生成.bpmn文件
新建流程(IDEA工具)
首先选中存放图形的目录(选择resources下的bpmn目录),点击菜单:New -> BpmnFile,如图:
弹出如下图所示框,输入evection 表示 出差审批流程:
起完名字evection后(默认扩展名为bpmn),就可以看到流程设计页面,如图所示:
左侧区域是绘图区,右侧区域是palette画板区域
鼠标先点击画板的元素即可在左侧绘图
绘制流程
使用滑板来绘制流程,通过从右侧把图标拖拽到左侧的画板,最终效果如下:
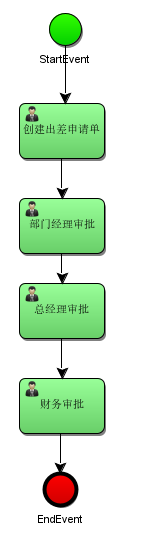
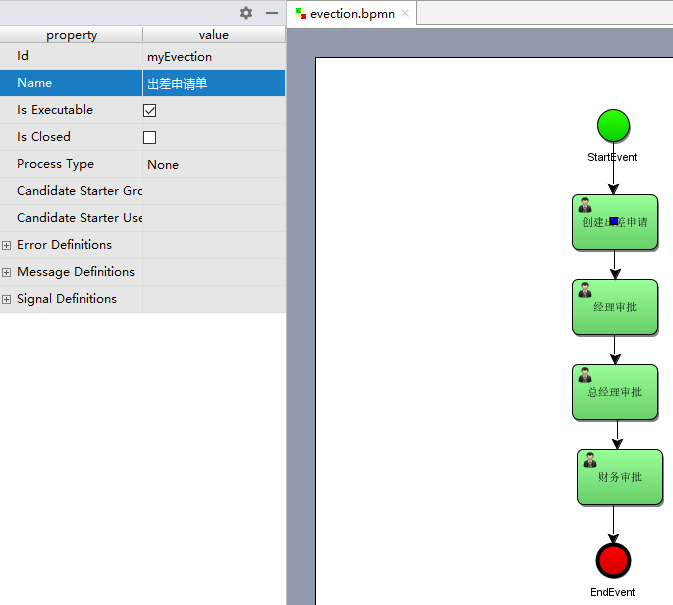
指定流程定义Key
流程定义key即流程定义的标识,通过properties视图查看流程的key
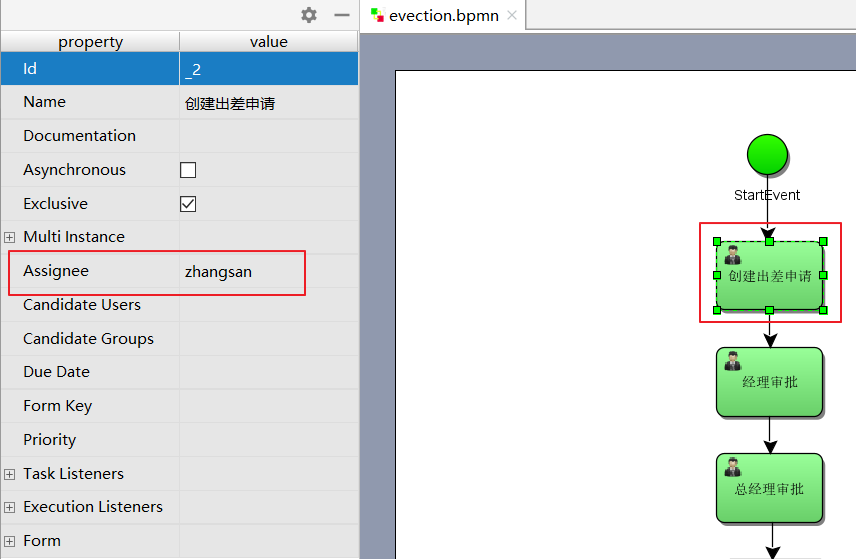
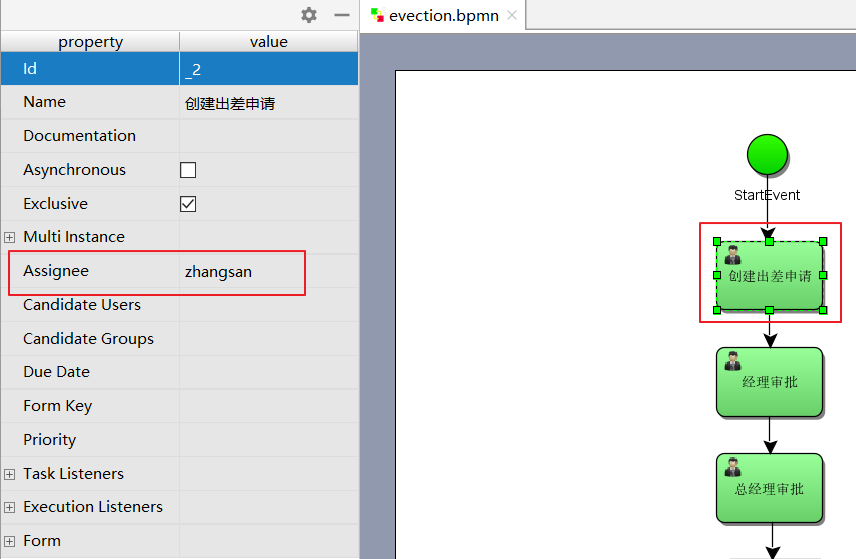
指定任务负责人
在properties视图指定每个任务结点的负责人,如:填写出差申请的负责人为 zhangsan
经理审批负责人为 jerry
总经理审批负责人为 jack
财务审批负责人为 rose
六、流程操作
6.1 流程定义
概述
流程定义是线下按照bpmn2.0标准去描述 业务流程,通常使用idea中的插件对业务流程进行建模。
使用idea下的designer设计器绘制流程,并会生成两个文件:.bpmn和.png
.bpmn文件
使用activiti-desinger设计业务流程,会生成.bpmn文件,上面我们已经创建好了bpmn文件
BPMN 2.0根节点是definitions节点。 这个元素中,可以定义多个流程定义(不过我们建议每个文件只包含一个流程定义, 可以简化开发过程中的维护难度)。 注意,definitions元素 最少也要包含xmlns 和 targetNamespace的声明。 targetNamespace可以是任意值,它用来对流程实例进行分类。
流程定义部分:定义了流程每个结点的描述及结点之间的流程流转。
流程布局定义:定义流程每个结点在流程图上的位置坐标等信息。
生成.png图片文件
IDEA工具中的操作方式
1、修改文件后缀为xml
首先将evection.bpmn文件改名为evection.xml,如下图:
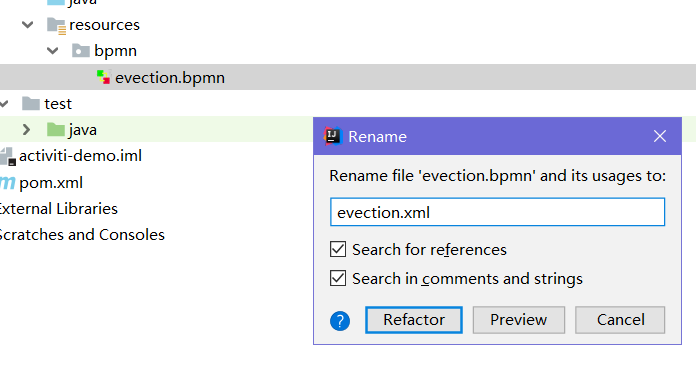
evection.xml修改前的bpmn文件,效果如下:
2、使用designer设计器打开.xml文件
在evection.xml文件上面,点右键并选择Diagrams菜单,再选择Show BPMN2.0 Designer…
3、查看打开的文件
打开后,却出现乱码,如图:
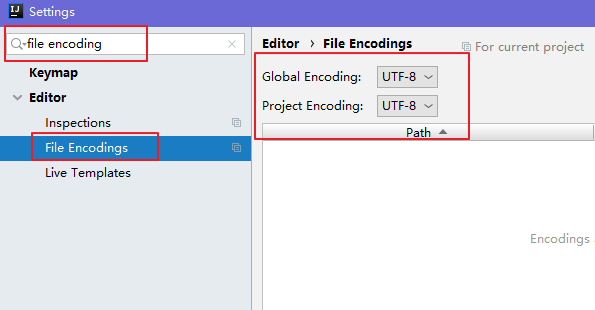
4、解决中文乱码
1、打开Settings,找到File Encodings,把encoding的选项都选择UTF-8
2、打开IDEA安装路径,找到如下的安装目录
根据自己所安装的版本来决定,我使用的是64位的idea,所以在idea64.exe.vmoptions文件的最后一行追加一条命令: -Dfile.encoding=UTF-8
如下所示:
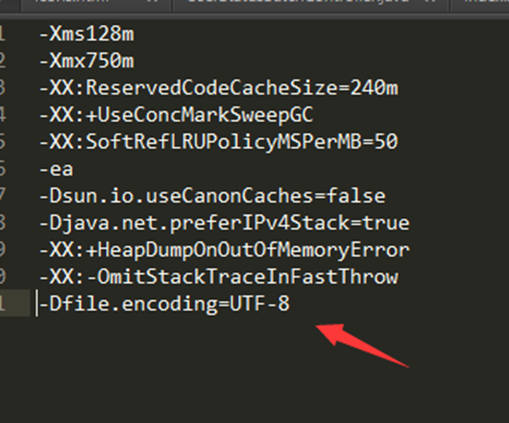
一定注意,不要有空格,否则重启IDEA时会打不开,然后 重启IDEA。
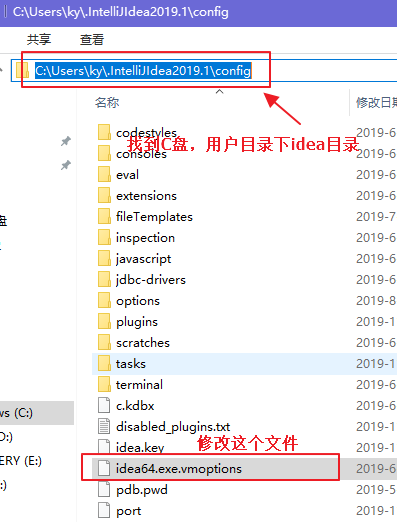
如果以上方法已经做完,还出现乱码,就再修改一个文件,并在文件的末尾添加: -Dfile.encoding=UTF-8,然后重启idea,如图:
最后重新在evection.xml文件上面,点右键并选择Diagrams菜单,再选择Show BPMN2.0 Designer…,看到生成图片,如图:
到此,解决乱码问题
5、导出为图片文件
点击Export To File的小图标,打开如下窗口,注意填写文件名及扩展名,选择好保存图片的位置:
然后,我们把png文件拷贝到resources下的bpmn目录,并且把evection.xml改名为evection.bpmn。
6.2 流程定义部署
概述
将上面在设计器中定义的流程部署到activiti数据库中,就是流程定义部署。
通过调用activiti的api将流程定义的bpmn和png两个文件一个一个添加部署到activiti中,也可以将两个文件打成zip包进行部署。
单个文件部署方式
分别将bpmn文件和png图片文件部署。
1 | |
执行此操作后activiti会将上边代码中指定的bpm文件和图片文件保存在activiti数据库。
压缩包部署方式
将evection.bpmn和evection.png压缩成zip包。
1 | |
执行此操作后activiti会将上边代码中指定的bpm文件和图片文件保存在activiti数据库。
操作数据表
流程定义部署后操作activiti的3张表如下:
act_re_deployment 流程定义部署表,每部署一次增加一条记录
act_re_procdef 流程定义表,部署每个新的流程定义都会在这张表中增加一条记录
act_ge_bytearray 流程资源表
接下来我们来看看,写入了什么数据:
1 | |
结果:

1 | |
结果:
注意,KEY 这个字段是用来唯一识别不同流程的关键字

1 | |
结果:

注意:
act_re_deployment和act_re_procdef一对多关系,一次部署在流程部署表生成一条记录,但一次部署可以部署多个流程定义,每个流程定义在流程定义表生成一条记录。每一个流程定义在act_ge_bytearray会存在两个资源记录,bpmn和png。
建议:一次部署一个流程,这样部署表和流程定义表是一对一有关系,方便读取流程部署及流程定义信息。
6.3 启动流程实例
流程定义部署在activiti后就可以通过工作流管理业务流程了,也就是说上边部署的出差申请流程可以使用了。
针对该流程,启动一个流程表示发起一个新的出差申请单,这就相当于java类与java对象的关系,类定义好后需要new创建一个对象使用,当然可以new多个对象。对于请出差申请流程,张三发起一个出差申请单需要启动一个流程实例,出差申请单发起一个出差单也需要启动一个流程实例。
代码如下:
1 | |
输出内容如下:

操作数据表
act_hi_actinst 流程实例执行历史
act_hi_identitylink 流程的参与用户历史信息
act_hi_procinst 流程实例历史信息
act_hi_taskinst 流程任务历史信息
act_ru_execution 流程执行信息
act_ru_identitylink 流程的参与用户信息
act_ru_task 任务信息
6.4 任务查询
流程启动后,任务的负责人就可以查询自己当前需要处理的任务,查询出来的任务都是该用户的待办任务。
1 | |
输出结果如下:
1 | |
6.5 流程任务处理
任务负责人查询待办任务,选择任务进行处理,完成任务。
1 | |
6.6 流程定义信息查询
查询流程相关信息,包含流程定义,流程部署,流程定义版本
1 | |
输出结果:
1 | |
6.7 流程删除
1 | |
说明:
使用repositoryService删除流程定义,历史表信息不会被删除如果该流程定义下没有正在运行的流程,则可以用普通删除。
如果该流程定义下存在已经运行的流程,使用普通删除报错,可用级联删除方法将流程及相关记录全部删除。
先删除没有完成流程节点,最后就可以完全删除流程定义信息
项目开发中级联删除操作一般只开放给超级管理员使用.
6.8 流程资源下载
现在我们的流程资源文件已经上传到数据库了,如果其他用户想要查看这些资源文件,可以从数据库中把资源文件下载到本地。
解决方案有:
1、jdbc对blob类型,clob类型数据读取出来,保存到文件目录
2、使用activiti的api来实现
使用commons-io.jar 解决IO的操作
引入commons-io依赖包
1 | |
通过流程定义对象获取流程定义资源,获取bpmn和png
1 | |
说明:
deploymentId为流程部署IDresource_name为act_ge_bytearray表中NAME_列的值使用repositoryService的getDeploymentResourceNames方法可以获取指定部署下得所有文件的名称使用repositoryService的getResourceAsStream方法传入部署ID和资源图片名称可以获取部署下指定名称文件的输入流
最后的将输入流中的图片资源进行输出。
6.9 流程历史信息的查看
即使流程定义已经删除了,流程执行的历史信息通过前面的分析,依然保存在activiti的act_hi_*相关的表中。所以我们还是可以查询流程执行的历史信息,可以通过HistoryService来查看相关的历史记录。
1 | |
单元测试-junit5
07、单元测试
1、JUnit5 的变化
Spring Boot 2.2.0 版本开始引入 JUnit 5 作为单元测试默认库
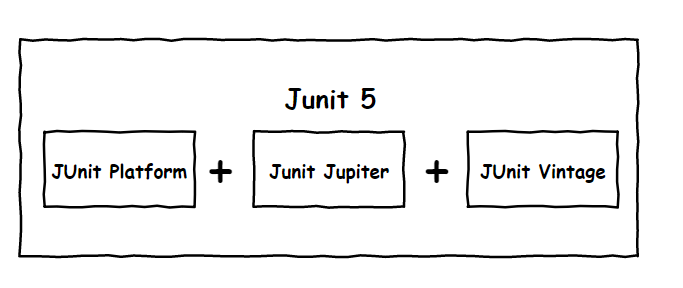
作为最新版本的JUnit框架,JUnit5与之前版本的Junit框架有很大的不同。由三个不同子项目的几个不同模块组成。
JUnit 5 = JUnit Platform + JUnit Jupiter + JUnit Vintage
JUnit Platform: Junit Platform是在JVM上启动测试框架的基础,不仅支持Junit自制的测试引擎,其他测试引擎也都可以接入。
JUnit Jupiter: JUnit Jupiter提供了JUnit5的新的编程模型,是JUnit5新特性的核心。内部 包含了一个测试引擎,用于在Junit Platform上运行。
JUnit Vintage: 由于JUint已经发展多年,为了照顾老的项目,JUnit Vintage提供了兼容JUnit4.x,Junit3.x的测试引擎。
注意:
SpringBoot 2.4 以上版本移除了默认对 Vintage 的依赖。如果需要兼容junit4需要自行引入(不能使用junit4的功能 @Test)
JUnit 5’s Vintage Engine Removed from spring-boot-starter-test,如果需要继续兼容junit4需要自行引入vintage
1 | |
1 | |
现在版本:
1 | |
以前:
@SpringBootTest + @RunWith(SpringTest.class)
SpringBoot整合Junit以后。
- 编写测试方法:@Test标注(注意需要使用junit5版本的注解)
- Junit类具有Spring的功能,@Autowired、比如 @Transactional 标注测试方法,测试完成后自动回滚
2、JUnit5常用注解
JUnit5的注解与JUnit4的注解有所变化
https://junit.org/junit5/docs/current/user-guide/#writing-tests-annotations
- **@Test **:表示方法是测试方法。但是与JUnit4的@Test不同,他的职责非常单一不能声明任何属性,拓展的测试将会由Jupiter提供额外测试
- **@ParameterizedTest **:表示方法是参数化测试,下方会有详细介绍
- **@RepeatedTest **:表示方法可重复执行,下方会有详细介绍
- **@DisplayName **:为测试类或者测试方法设置展示名称
- @BeforeEach :表示在每个单元测试之前执行
- **@AfterEach **:表示在每个单元测试之后执行
- **@BeforeAll :**表示在所有单元测试之前执行
- **@AfterAll :**表示在所有单元测试之后执行
- **@Tag :**表示单元测试类别,类似于JUnit4中的@Categories
- **@Disabled :**表示测试类或测试方法不执行,类似于JUnit4中的@Ignore
- **@Timeout :**表示测试方法运行如果超过了指定时间将会返回错误
- **@ExtendWith :**为测试类或测试方法提供扩展类引用
1 | |
3、断言(assertions)
断言(assertions)是测试方法中的核心部分,用来对测试需要满足的条件进行验证。这些断言方法都是 org.junit.jupiter.api.Assertions 的静态方法。JUnit 5 内置的断言可以分成如下几个类别:
检查业务逻辑返回的数据是否合理。
所有的测试运行结束以后,会有一个详细的测试报告;
1、简单断言
用来对单个值进行简单的验证。如:
| 方法 | 说明 |
|---|---|
| assertEquals | 判断两个对象或两个原始类型是否相等 |
| assertNotEquals | 判断两个对象或两个原始类型是否不相等 |
| assertSame | 判断两个对象引用是否指向同一个对象 |
| assertNotSame | 判断两个对象引用是否指向不同的对象 |
| assertTrue | 判断给定的布尔值是否为 true |
| assertFalse | 判断给定的布尔值是否为 false |
| assertNull | 判断给定的对象引用是否为 null |
| assertNotNull | 判断给定的对象引用是否不为 null |
1 | |
2、数组断言
通过 assertArrayEquals 方法来判断两个对象或原始类型的数组是否相等
1 | |
3、组合断言
assertAll 方法接受多个 org.junit.jupiter.api.Executable 函数式接口的实例作为要验证的断言,可以通过 lambda 表达式很容易的提供这些断言
1 | |
4、异常断言
在JUnit4时期,想要测试方法的异常情况时,需要用**@Rule注解的ExpectedException变量还是比较麻烦的。而JUnit5提供了一种新的断言方式Assertions.assertThrows()** ,配合函数式编程就可以进行使用。
1 | |
5、超时断言
Junit5还提供了Assertions.assertTimeout() 为测试方法设置了超时时间
1 | |
6、快速失败
通过 fail 方法直接使得测试失败
1 | |
4、前置条件(assumptions)
JUnit 5 中的前置条件(assumptions【假设】)类似于断言,不同之处在于不满足的断言会使得测试方法失败,而不满足的前置条件只会使得测试方法的执行终止。前置条件可以看成是测试方法执行的前提,当该前提不满足时,就没有继续执行的必要。
1 | |
assumeTrue 和 assumFalse 确保给定的条件为 true 或 false,不满足条件会使得测试执行终止。assumingThat 的参数是表示条件的布尔值和对应的 Executable 接口的实现对象。只有条件满足时,Executable 对象才会被执行;当条件不满足时,测试执行并不会终止。
5、嵌套测试
JUnit 5 可以通过 Java 中的内部类和@Nested 注解实现嵌套测试,从而可以更好的把相关的测试方法组织在一起。在内部类中可以使用@BeforeEach 和@AfterEach 注解,而且嵌套的层次没有限制。
1 | |
6、参数化测试
参数化测试是JUnit5很重要的一个新特性,它使得用不同的参数多次运行测试成为了可能,也为我们的单元测试带来许多便利。
利用**@ValueSource**等注解,指定入参,我们将可以使用不同的参数进行多次单元测试,而不需要每新增一个参数就新增一个单元测试,省去了很多冗余代码。
**
**
@ValueSource: 为参数化测试指定入参来源,支持八大基础类以及String类型,Class类型
@NullSource: 表示为参数化测试提供一个null的入参
@EnumSource: 表示为参数化测试提供一个枚举入参
@CsvFileSource:表示读取指定CSV文件内容作为参数化测试入参
@MethodSource:表示读取指定方法的返回值作为参数化测试入参(注意方法返回需要是一个流)
当然如果参数化测试仅仅只能做到指定普通的入参还达不到让我觉得惊艳的地步。让我真正感到他的强大之处的地方在于他可以支持外部的各类入参。如:CSV,YML,JSON 文件甚至方法的返回值也可以作为入参。只需要去实现ArgumentsProvider接口,任何外部文件都可以作为它的入参。
1 | |
7、迁移指南
在进行迁移的时候需要注意如下的变化:
- 注解在 org.junit.jupiter.api 包中,断言在 org.junit.jupiter.api.Assertions 类中,前置条件在 org.junit.jupiter.api.Assumptions 类中。
- 把@Before 和@After 替换成@BeforeEach 和@AfterEach。
- 把@BeforeClass 和@AfterClass 替换成@BeforeAll 和@AfterAll。
- 把@Ignore 替换成@Disabled。
- 把@Category 替换成@Tag。
- 把@RunWith、@Rule 和@ClassRule 替换成@ExtendWith。
8、参考来源:
hexo 入门简介
学习笔记!2020年2月5日13点13分
— #安装Nodejs
node -v #查看node版本
npm -v #查看npm版本
npm install -g cnpm –registry=http://registry.npm.taobao.org #安装淘宝的cnpm 管理器
cnpm -v #查看cnpm版本
cnpm install -g hexo-cli #安装hexo框架
hexo -v #查看hexo版本
mkdir blog #创建blog目录
cd blog #进入blog目录
sudo hexo init #生成博客 初始化博客
hexo s #启动本地博客服务
http://localhost:4000/ #本地访问地址
hexo n “我的第一篇文章” #创建新的文章
#返回blog目录
hexo clean #清理
hexo g #生成
#Github创建一个新的仓库 YourGithubName.github.io
cnpm install –save hexo-deployer-git #在blog目录下安装git部署插件
-—
#配置_config.yml
-—-
# Deployment
## Docs: https://hexo.io/docs/deployment.html
deploy:
type: git
repo: https://github.com/YourGithubName/YourGithubName.github.io.git
branch: master
-—-
hexo d #部署到Github仓库里
https://YourGithubName.github.io/ #访问这个地址可以查看博客
git clone https://github.com/litten/hexo-theme-yilia.git themes/yilia #下载yilia主题到本地
#修改hexo根目录下的 _config.yml 文件 : theme: yilia
hexo c #清理一下
hexo g #生成
hexo d #部署到远程Github仓库
https://YourGithubName.github.io/ #查看博客
设计模式-day04
5,结构型模式
5.6 组合模式
5.6.1 概述
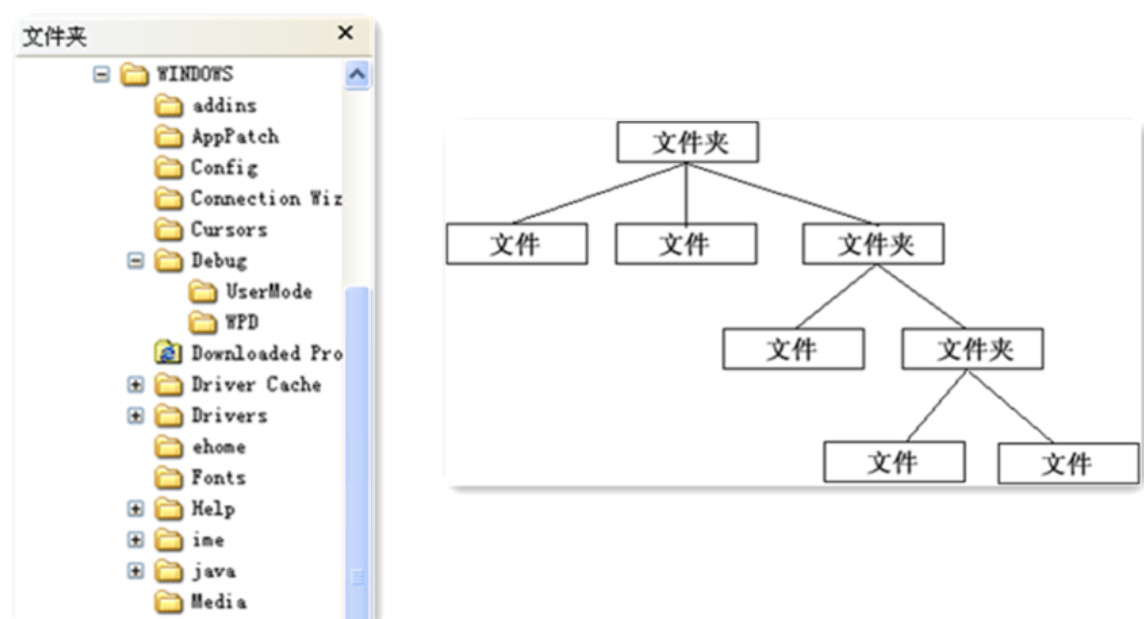
对于这个图片肯定会非常熟悉,上图我们可以看做是一个文件系统,对于这样的结构我们称之为树形结构。在树形结构中可以通过调用某个方法来遍历整个树,当我们找到某个叶子节点后,就可以对叶子节点进行相关的操作。可以将这颗树理解成一个大的容器,容器里面包含很多的成员对象,这些成员对象即可是容器对象也可以是叶子对象。但是由于容器对象和叶子对象在功能上面的区别,使得我们在使用的过程中必须要区分容器对象和叶子对象,但是这样就会给客户带来不必要的麻烦,作为客户而已,它始终希望能够一致的对待容器对象和叶子对象。
定义:
又名部分整体模式,是用于把一组相似的对象当作一个单一的对象。组合模式依据树形结构来组合对象,用来表示部分以及整体层次。这种类型的设计模式属于结构型模式,它创建了对象组的树形结构。
5.6.2 结构
组合模式主要包含三种角色:
- 抽象根节点(Component):定义系统各层次对象的共有方法和属性,可以预先定义一些默认行为和属性。
- 树枝节点(Composite):定义树枝节点的行为,存储子节点,组合树枝节点和叶子节点形成一个树形结构。
- 叶子节点(Leaf):叶子节点对象,其下再无分支,是系统层次遍历的最小单位。
5.6.3 案例实现
【例】软件菜单
如下图,我们在访问别的一些管理系统时,经常可以看到类似的菜单。一个菜单可以包含菜单项(菜单项是指不再包含其他内容的菜单条目),也可以包含带有其他菜单项的菜单,因此使用组合模式描述菜单就很恰当,我们的需求是针对一个菜单,打印出其包含的所有菜单以及菜单项的名称。

要实现该案例,我们先画出类图:
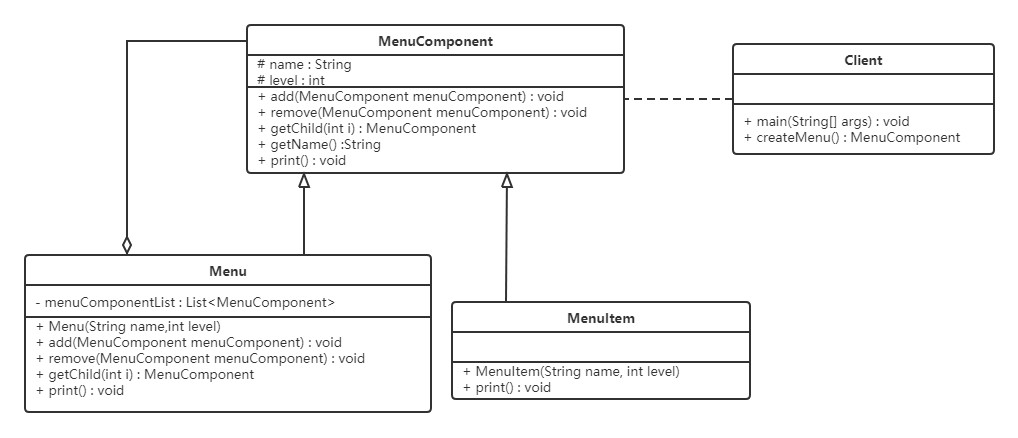
代码实现:
不管是菜单还是菜单项,都应该继承自统一的接口,这里姑且将这个统一的接口称为菜单组件。
1 | |
这里的MenuComponent定义为抽象类,因为有一些共有的属性和行为要在该类中实现,Menu和MenuItem类就可以只覆盖自己感兴趣的方法,而不用搭理不需要或者不感兴趣的方法,举例来说,Menu类可以包含子菜单,因此需要覆盖add()、remove()、getChild()方法,但是MenuItem就不应该有这些方法。这里给出的默认实现是抛出异常,你也可以根据自己的需要改写默认实现。
1 | |
Menu类已经实现了除了getName方法的其他所有方法,因为Menu类具有添加菜单,移除菜单和获取子菜单的功能。
1 | |
MenuItem是菜单项,不能再有子菜单,所以添加菜单,移除菜单和获取子菜单的功能并不能实现。
5.6.4 组合模式的分类
在使用组合模式时,根据抽象构件类的定义形式,我们可将组合模式分为透明组合模式和安全组合模式两种形式。
透明组合模式
透明组合模式中,抽象根节点角色中声明了所有用于管理成员对象的方法,比如在示例中
MenuComponent声明了add、remove、getChild方法,这样做的好处是确保所有的构件类都有相同的接口。透明组合模式也是组合模式的标准形式。透明组合模式的缺点是不够安全,因为叶子对象和容器对象在本质上是有区别的,叶子对象不可能有下一个层次的对象,即不可能包含成员对象,因此为其提供 add()、remove() 等方法是没有意义的,这在编译阶段不会出错,但在运行阶段如果调用这些方法可能会出错(如果没有提供相应的错误处理代码)
安全组合模式
在安全组合模式中,在抽象构件角色中没有声明任何用于管理成员对象的方法,而是在树枝节点
Menu类中声明并实现这些方法。安全组合模式的缺点是不够透明,因为叶子构件和容器构件具有不同的方法,且容器构件中那些用于管理成员对象的方法没有在抽象构件类中定义,因此客户端不能完全针对抽象编程,必须有区别地对待叶子构件和容器构件。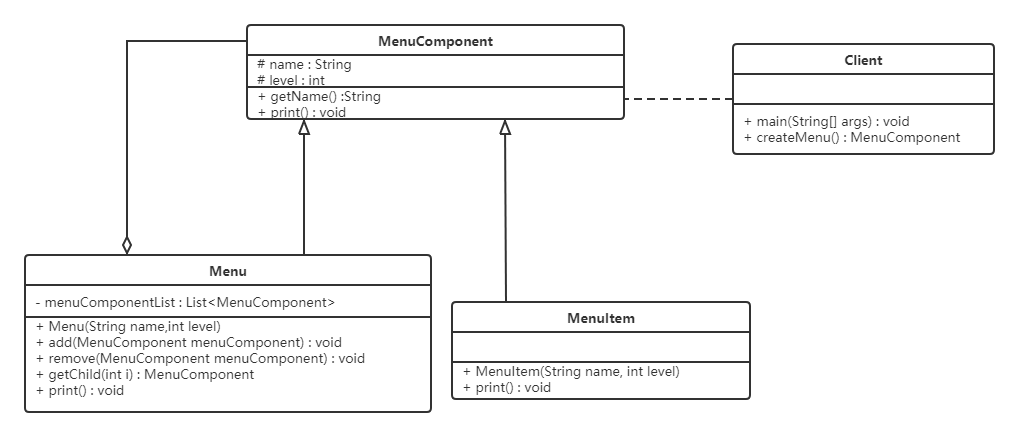
5.6.5 优点
- 组合模式可以清楚地定义分层次的复杂对象,表示对象的全部或部分层次,它让客户端忽略了层次的差异,方便对整个层次结构进行控制。
- 客户端可以一致地使用一个组合结构或其中单个对象,不必关心处理的是单个对象还是整个组合结构,简化了客户端代码。
- 在组合模式中增加新的树枝节点和叶子节点都很方便,无须对现有类库进行任何修改,符合“开闭原则”。
- 组合模式为树形结构的面向对象实现提供了一种灵活的解决方案,通过叶子节点和树枝节点的递归组合,可以形成复杂的树形结构,但对树形结构的控制却非常简单。
5.6.6 使用场景
组合模式正是应树形结构而生,所以组合模式的使用场景就是出现树形结构的地方。比如:文件目录显示,多级目录呈现等树形结构数据的操作。
5.7 享元模式
5.7.1 概述
定义:
**==运用共享技术来有效地支持大量细粒度对象的复用==**。它通过共享已经存在的对象来大幅度减少需要创建的对象数量、避免大量相似对象的开销,从而提高系统资源的利用率。
5.7.2 结构
享元(Flyweight )模式中存在以下两种状态:
- 内部状态,即不会随着环境的改变而改变的可共享部分。
- 外部状态,指随环境改变而改变的不可以共享的部分。享元模式的实现要领就是区分应用中的这两种状态,并将外部状态外部化。
享元模式的主要有以下角色:
- 抽象享元角色(Flyweight):通常是一个接口或抽象类,在抽象享元类中声明了具体享元类公共的方法,这些方法可以向外界提供享元对象的内部数据(内部状态),同时也可以通过这些方法来设置外部数据(外部状态)。
- 具体享元(Concrete Flyweight)角色 :它实现了抽象享元类,称为享元对象;在具体享元类中为内部状态提供了存储空间。通常我们可以结合单例模式来设计具体享元类,为每一个具体享元类提供唯一的享元对象。
- 非享元(Unsharable Flyweight)角色 :并不是所有的抽象享元类的子类都需要被共享,不能被共享的子类可设计为非共享具体享元类;当需要一个非共享具体享元类的对象时可以直接通过实例化创建。
- 享元工厂(Flyweight Factory)角色 :负责创建和管理享元角色。当客户对象请求一个享元对象时,享元工厂检査系统中是否存在符合要求的享元对象,如果存在则提供给客户;如果不存在的话,则创建一个新的享元对象。
5.7.3 案例实现
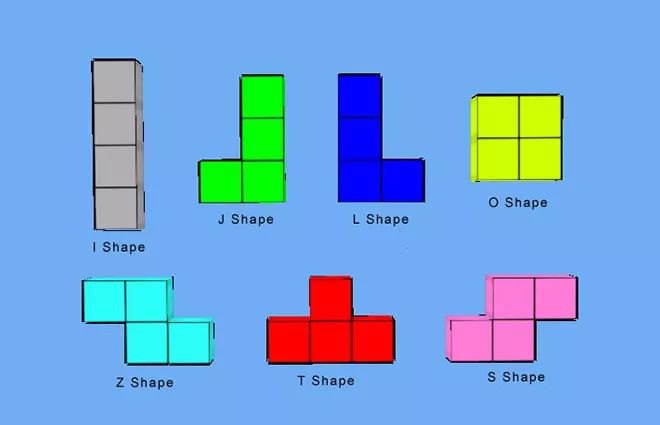
【例】俄罗斯方块
下面的图片是众所周知的俄罗斯方块中的一个个方块,如果在俄罗斯方块这个游戏中,每个不同的方块都是一个实例对象,这些对象就要占用很多的内存空间,下面利用享元模式进行实现。
先来看类图:
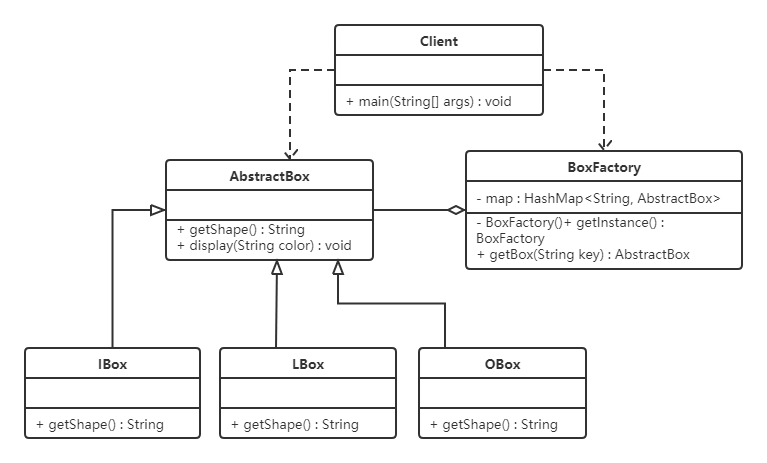
代码如下:
俄罗斯方块有不同的形状,我们可以对这些形状向上抽取出AbstractBox,用来定义共性的属性和行为。
1 | |
接下来就是定义不同的形状了,IBox类、LBox类、OBox类等。
1 | |
提供了一个工厂类(BoxFactory),用来管理享元对象(也就是AbstractBox子类对象),该工厂类对象只需要一个,所以可以使用单例模式。并给工厂类提供一个获取形状的方法。
1 | |
5.7.5 优缺点和使用场景
1,优点
- 极大减少内存中相似或相同对象数量,节约系统资源,提供系统性能
- 享元模式中的外部状态相对独立,且不影响内部状态
2,缺点:
为了使对象可以共享,需要将享元对象的部分状态外部化,分离内部状态和外部状态,使程序逻辑复杂
3,使用场景:
- 一个系统有大量相同或者相似的对象,造成内存的大量耗费。
- 对象的大部分状态都可以外部化,可以将这些外部状态传入对象中。
- 在使用享元模式时需要维护一个存储享元对象的享元池,而这需要耗费一定的系统资源,因此,应当在需要多次重复使用享元对象时才值得使用享元模式。
5.7.6 JDK源码解析
Integer类使用了享元模式。我们先看下面的例子:
1 | |
运行上面代码,结果如下:

为什么第一个输出语句输出的是true,第二个输出语句输出的是false?通过反编译软件进行反编译,代码如下:
1 | |
上面代码可以看到,直接给Integer类型的变量赋值基本数据类型数据的操作底层使用的是 valueOf() ,所以只需要看该方法即可
1 | |
可以看到 Integer 默认先创建并缓存 -128 ~ 127 之间数的 Integer 对象,当调用 valueOf 时如果参数在 -128 ~ 127 之间则计算下标并从缓存中返回,否则创建一个新的 Integer 对象。
6,行为型模式
行为型模式用于描述程序在运行时复杂的流程控制,即描述多个类或对象之间怎样相互协作共同完成单个对象都无法单独完成的任务,它涉及算法与对象间职责的分配。
行为型模式分为类行为模式和对象行为模式,前者采用继承机制来在类间分派行为,后者采用组合或聚合在对象间分配行为。由于组合关系或聚合关系比继承关系耦合度低,满足“合成复用原则”,所以对象行为模式比类行为模式具有更大的灵活性。
行为型模式分为:
- 模板方法模式
- 策略模式
- 命令模式
- 职责链模式
- 状态模式
- 观察者模式
- 中介者模式
- 迭代器模式
- 访问者模式
- 备忘录模式
- 解释器模式
以上 11 种行为型模式,除了模板方法模式和解释器模式是类行为型模式,其他的全部属于对象行为型模式。
6.1 模板方法模式
6.1.1 概述
在面向对象程序设计过程中,程序员常常会遇到这种情况:设计一个系统时知道了算法所需的关键步骤,而且确定了这些步骤的执行顺序,但某些步骤的具体实现还未知,或者说某些步骤的实现与具体的环境相关。
例如,去银行办理业务一般要经过以下4个流程:取号、排队、办理具体业务、对银行工作人员进行评分等,其中取号、排队和对银行工作人员进行评分的业务对每个客户是一样的,可以在父类中实现,但是办理具体业务却因人而异,它可能是存款、取款或者转账等,可以延迟到子类中实现。
定义:
定义一个操作中的算法骨架,而将算法的一些步骤延迟到子类中,使得子类可以不改变该算法结构的情况下重定义该算法的某些特定步骤。
6.1.2 结构
模板方法(Template Method)模式包含以下主要角色:
抽象类(Abstract Class):负责给出一个算法的轮廓和骨架。它由一个模板方法和若干个基本方法构成。
模板方法:定义了算法的骨架,按某种顺序调用其包含的基本方法。
基本方法:是实现算法各个步骤的方法,是模板方法的组成部分。基本方法又可以分为三种:
抽象方法(Abstract Method) :一个抽象方法由抽象类声明、由其具体子类实现。
具体方法(Concrete Method) :一个具体方法由一个抽象类或具体类声明并实现,其子类可以进行覆盖也可以直接继承。
钩子方法(Hook Method) :在抽象类中已经实现,包括用于判断的逻辑方法和需要子类重写的空方法两种。
一般钩子方法是用于判断的逻辑方法,这类方法名一般为isXxx,返回值类型为boolean类型。
具体子类(Concrete Class):实现抽象类中所定义的抽象方法和钩子方法,它们是一个顶级逻辑的组成步骤。
6.1.3 案例实现
【例】炒菜
炒菜的步骤是固定的,分为倒油、热油、倒蔬菜、倒调料品、翻炒等步骤。现通过模板方法模式来用代码模拟。类图如下:
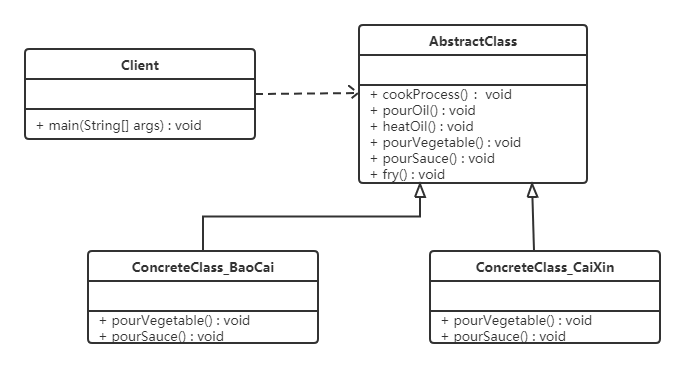
代码如下:
1 | |
注意:为防止恶意操作,一般模板方法都加上 final 关键词。
6.1.3 优缺点
优点:
提高代码复用性
将相同部分的代码放在抽象的父类中,而将不同的代码放入不同的子类中。
实现了反向控制
通过一个父类调用其子类的操作,通过对子类的具体实现扩展不同的行为,实现了反向控制 ,并符合“开闭原则”。
缺点:
- 对每个不同的实现都需要定义一个子类,这会导致类的个数增加,系统更加庞大,设计也更加抽象。
- 父类中的抽象方法由子类实现,子类执行的结果会影响父类的结果,这导致一种反向的控制结构,它提高了代码阅读的难度。
6.1.4 适用场景
- 算法的整体步骤很固定,但其中个别部分易变时,这时候可以使用模板方法模式,将容易变的部分抽象出来,供子类实现。
- 需要通过子类来决定父类算法中某个步骤是否执行,实现子类对父类的反向控制。
6.1.5 JDK源码解析
InputStream类就使用了模板方法模式。在InputStream类中定义了多个 read() 方法,如下:
1 | |
从上面代码可以看到,无参的 read() 方法是抽象方法,要求子类必须实现。而 read(byte b[]) 方法调用了 read(byte b[], int off, int len) 方法,所以在此处重点看的方法是带三个参数的方法。
在该方法中第18行、27行,可以看到调用了无参的抽象的 read() 方法。
总结如下: 在InputStream父类中已经定义好了读取一个字节数组数据的方法是每次读取一个字节,并将其存储到数组的第一个索引位置,读取len个字节数据。具体如何读取一个字节数据呢?由子类实现。
6.2 策略模式
6.2.1 概述
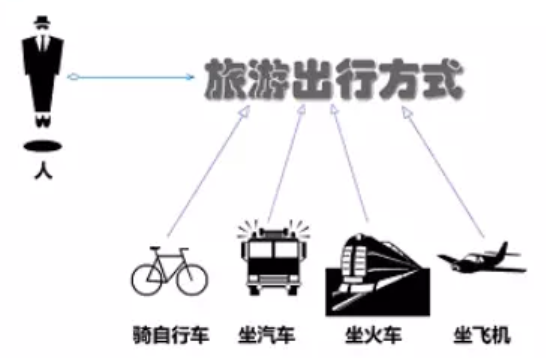
先看下面的图片,我们去旅游选择出行模式有很多种,可以骑自行车、可以坐汽车、可以坐火车、可以坐飞机。
作为一个程序猿,开发需要选择一款开发工具,当然可以进行代码开发的工具有很多,可以选择Idea进行开发,也可以使用eclipse进行开发,也可以使用其他的一些开发工具。
定义:
该模式定义了一系列算法,并将每个算法封装起来,使它们可以相互替换,且算法的变化不会影响使用算法的客户。策略模式属于对象行为模式,它通过对算法进行封装,把使用算法的责任和算法的实现分割开来,并委派给不同的对象对这些算法进行管理。
6.2.2 结构
策略模式的主要角色如下:
- 抽象策略(Strategy)类:这是一个抽象角色,通常由一个接口或抽象类实现。此角色给出所有的具体策略类所需的接口。
- 具体策略(Concrete Strategy)类:实现了抽象策略定义的接口,提供具体的算法实现或行为。
- 环境(Context)类:持有一个策略类的引用,最终给客户端调用。
6.2.3 案例实现
【例】促销活动
一家百货公司在定年度的促销活动。针对不同的节日(春节、中秋节、圣诞节)推出不同的促销活动,由促销员将促销活动展示给客户。类图如下:
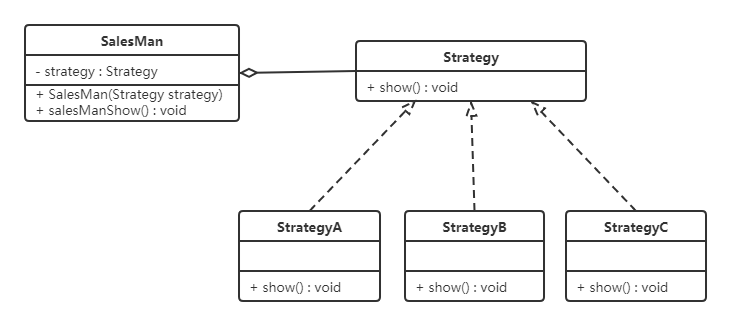
代码如下:
定义百货公司所有促销活动的共同接口
1 | |
定义具体策略角色(Concrete Strategy):每个节日具体的促销活动
1 | |
定义环境角色(Context):用于连接上下文,即把促销活动推销给客户,这里可以理解为销售员
1 | |
6.2.4 优缺点
1,优点:
策略类之间可以自由切换
由于策略类都实现同一个接口,所以使它们之间可以自由切换。
易于扩展
增加一个新的策略只需要添加一个具体的策略类即可,基本不需要改变原有的代码,符合“开闭原则“
避免使用多重条件选择语句(if else),充分体现面向对象设计思想。
2,缺点:
- 客户端必须知道所有的策略类,并自行决定使用哪一个策略类。
- 策略模式将造成产生很多策略类,可以通过使用享元模式在一定程度上减少对象的数量。
6.2.5 使用场景
- 一个系统需要动态地在几种算法中选择一种时,可将每个算法封装到策略类中。
- 一个类定义了多种行为,并且这些行为在这个类的操作中以多个条件语句的形式出现,可将每个条件分支移入它们各自的策略类中以代替这些条件语句。
- 系统中各算法彼此完全独立,且要求对客户隐藏具体算法的实现细节时。
- 系统要求使用算法的客户不应该知道其操作的数据时,可使用策略模式来隐藏与算法相关的数据结构。
- 多个类只区别在表现行为不同,可以使用策略模式,在运行时动态选择具体要执行的行为。
6.2.6 JDK源码解析
Comparator 中的策略模式。在Arrays类中有一个 sort() 方法,如下:
1 | |
Arrays就是一个环境角色类,这个sort方法可以传一个新策略让Arrays根据这个策略来进行排序。就比如下面的测试类。
1 | |
这里我们在调用Arrays的sort方法时,第二个参数传递的是Comparator接口的子实现类对象。所以Comparator充当的是抽象策略角色,而具体的子实现类充当的是具体策略角色。环境角色类(Arrays)应该持有抽象策略的引用来调用。那么,Arrays类的sort方法到底有没有使用Comparator子实现类中的 compare() 方法吗?让我们继续查看TimSort类的 sort() 方法,代码如下:
1 | |
上面的代码中最终会跑到 countRunAndMakeAscending() 这个方法中。我们可以看见,只用了compare方法,所以在调用Arrays.sort方法只传具体compare重写方法的类对象就行,这也是Comparator接口中必须要子类实现的一个方法。
6.2.7 策略模式的实战使用
==https://blog.csdn.net/m0_37602117/article/details/101756303==
6.3 命令模式
6.3.1 概述
日常生活中,我们出去吃饭都会遇到下面的场景。
定义:
将一个请求封装为一个对象,使发出请求的责任和执行请求的责任分割开。这样两者之间通过命令对象进行沟通,这样方便将命令对象进行存储、传递、调用、增加与管理。
6.3.2 结构
命令模式包含以下主要角色:
- 抽象命令类(Command)角色: 定义命令的接口,声明执行的方法。
- 具体命令(Concrete Command)角色:具体的命令,实现命令接口;通常会持有接收者,并调用接收者的功能来完成命令要执行的操作。
- 实现者/接收者(Receiver)角色: 接收者,真正执行命令的对象。任何类都可能成为一个接收者,只要它能够实现命令要求实现的相应功能。
- 调用者/请求者(Invoker)角色: 要求命令对象执行请求,通常会持有命令对象,可以持有很多的命令对象。这个是客户端真正触发命令并要求命令执行相应操作的地方,也就是说相当于使用命令对象的入口。
6.3.3 案例实现
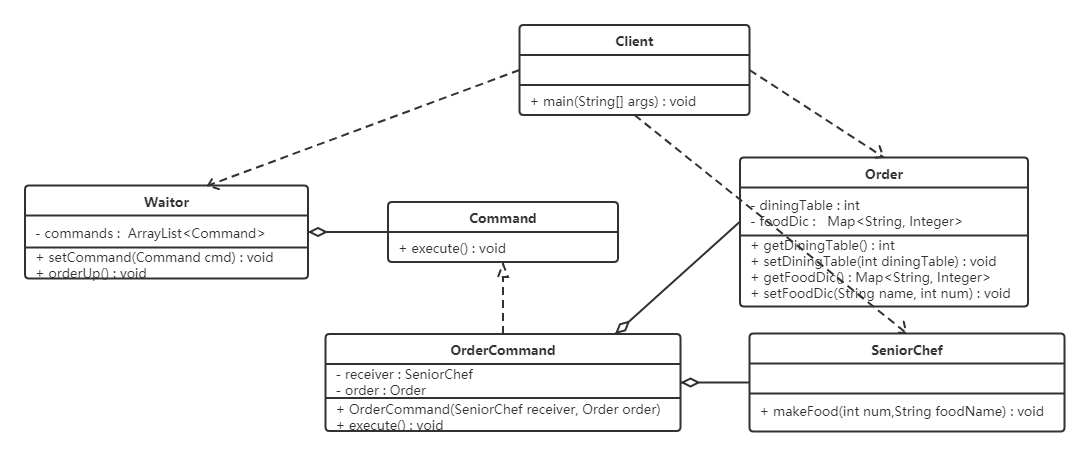
将上面的案例用代码实现,那我们就需要分析命令模式的角色在该案例中由谁来充当。
服务员: 就是调用者角色,由她来发起命令。
资深大厨: 就是接收者角色,真正命令执行的对象。
订单: 命令中包含订单。
类图如下:
代码如下:
1 | |
6.3.4 优缺点
1,优点:
- 降低系统的耦合度。命令模式能将调用操作的对象与实现该操作的对象解耦。
- 增加或删除命令非常方便。采用命令模式增加与删除命令不会影响其他类,它满足“开闭原则”,对扩展比较灵活。
- 可以实现宏命令。命令模式可以与组合模式结合,将多个命令装配成一个组合命令,即宏命令。
- 方便实现 Undo 和 Redo 操作。命令模式可以与后面介绍的备忘录模式结合,实现命令的撤销与恢复。
2,缺点:
- 使用命令模式可能会导致某些系统有过多的具体命令类。
- 系统结构更加复杂。
6.3.5 使用场景
- 系统需要将请求调用者和请求接收者解耦,使得调用者和接收者不直接交互。
- 系统需要在不同的时间指定请求、将请求排队和执行请求。
- 系统需要支持命令的撤销(Undo)操作和恢复(Redo)操作。
6.3.6 JDK源码解析
Runable是一个典型命令模式,Runnable担当命令的角色,Thread充当的是调用者,start方法就是其执行方法
1 | |
会调用一个native方法start0(),调用系统方法,开启一个线程。而接收者是对程序员开放的,可以自己定义接收者。
1 | |
1 | |
6.4 责任链模式
6.4.1 概述
在现实生活中,常常会出现这样的事例:一个请求有多个对象可以处理,但每个对象的处理条件或权限不同。例如,公司员工请假,可批假的领导有部门负责人、副总经理、总经理等,但每个领导能批准的天数不同,员工必须根据自己要请假的天数去找不同的领导签名,也就是说员工必须记住每个领导的姓名、电话和地址等信息,这增加了难度。这样的例子还有很多,如找领导出差报销、生活中的“击鼓传花”游戏等。
定义:
又名职责链模式,为了避免请求发送者与多个请求处理者耦合在一起,将所有请求的处理者通过前一对象记住其下一个对象的引用而连成一条链;当有请求发生时,可将请求沿着这条链传递,直到有对象处理它为止。
6.4.2 结构
职责链模式主要包含以下角色:
- 抽象处理者(Handler)角色:定义一个处理请求的接口,包含抽象处理方法和一个后继连接。
- 具体处理者(Concrete Handler)角色:实现抽象处理者的处理方法,判断能否处理本次请求,如果可以处理请求则处理,否则将该请求转给它的后继者。
- 客户类(Client)角色:创建处理链,并向链头的具体处理者对象提交请求,它不关心处理细节和请求的传递过程。
6.4.3 案例实现
现需要开发一个请假流程控制系统。请假一天以下的假只需要小组长同意即可;请假1天到3天的假还需要部门经理同意;请求3天到7天还需要总经理同意才行。
类图如下:
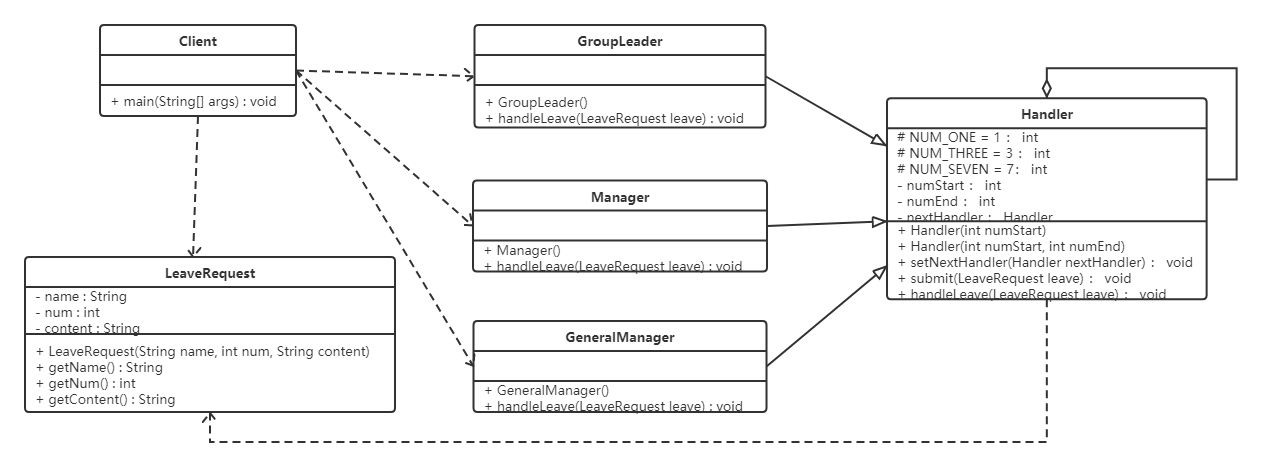
代码如下:
1 | |
6.4.4 优缺点
1,优点:
降低了对象之间的耦合度
该模式降低了请求发送者和接收者的耦合度。
增强了系统的可扩展性
可以根据需要增加新的请求处理类,满足开闭原则。
增强了给对象指派职责的灵活性
当工作流程发生变化,可以动态地改变链内的成员或者修改它们的次序,也可动态地新增或者删除责任。
==责任链简化了对象之间的连接==
一个对象只需保持一个指向其后继者的引用,不需保持其他所有处理者的引用,这避免了使用众多的 if 或者 if···else 语句。
责任分担
每个类只需要处理自己该处理的工作,不能处理的传递给下一个对象完成,明确各类的责任范围,符合类的单一职责原则。
2,缺点:
- 不能保证每个请求一定被处理。由于一个请求没有明确的接收者,所以不能保证它一定会被处理,该请求可能一直传到链的末端都得不到处理。
- 对比较长的职责链,请求的处理可能涉及多个处理对象,系统性能将受到一定影响。
- 职责链建立的合理性要靠客户端来保证,增加了客户端的复杂性,可能会由于职责链的错误设置而导致系统出错,如可能会造成循环调用。
6.4.5 源码解析
在javaWeb应用开发中,FilterChain是职责链(过滤器)模式的典型应用,以下是Filter的模拟实现分析:
模拟web请求Request以及web响应Response
1
2
3
4
5
6
7public interface Request{
}
public interface Response{
}模拟web过滤器Filter
1
2
3public interface Filter {
public void doFilter(Request req,Response res,FilterChain c);
}模拟实现具体过滤器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25public class FirstFilter implements Filter {
@Override
public void doFilter(Request request, Response response, FilterChain chain) {
System.out.println("过滤器1 前置处理");
// 先执行所有request再倒序执行所有response
chain.doFilter(request, response);
System.out.println("过滤器1 后置处理");
}
}
public class SecondFilter implements Filter {
@Override
public void doFilter(Request request, Response response, FilterChain chain) {
System.out.println("过滤器2 前置处理");
// 先执行所有request再倒序执行所有response
chain.doFilter(request, response);
System.out.println("过滤器2 后置处理");
}
}模拟实现过滤器链FilterChain
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public class FilterChain {
private List<Filter> filters = new ArrayList<Filter>();
private int index = 0;
// 链式调用
public FilterChain addFilter(Filter filter) {
this.filters.add(filter);
return this;
}
public void doFilter(Request request, Response response) {
if (index == filters.size()) {
return;
}
Filter filter = filters.get(index);
index++;
filter.doFilter(request, response, this);
}
}测试类
1
2
3
4
5
6
7
8
9
10public class Client {
public static void main(String[] args) {
Request req = null;
Response res = null ;
FilterChain filterChain = new FilterChain();
filterChain.addFilter(new FirstFilter()).addFilter(new SecondFilter());
filterChain.doFilter(req,res);
}
}
设计模式-day06
6 , 行为型模式
6.11 解释器模式
6.11.1 概述
如上图,设计一个软件用来进行加减计算。我们第一想法就是使用工具类,提供对应的加法和减法的工具方法。
1 | |
上面的形式比较单一、有限,如果形式变化非常多,这就不符合要求,因为加法和减法运算,两个运算符与数值可以有无限种组合方式。比如 1+2+3+4+5、1+2+3-4等等。
显然,现在需要一种翻译识别机器,能够解析由数字以及 + - 符号构成的合法的运算序列。如果把运算符和数字都看作节点的话,能够逐个节点的进行读取解析运算,这就是解释器模式的思维。
定义:
给定一个语言,定义它的文法表示,并定义一个解释器,这个解释器使用该标识来解释语言中的句子。
在解释器模式中,我们需要将待解决的问题,提取出规则,抽象为一种“语言”。比如加减法运算,规则为:由数值和+-符号组成的合法序列,“1+3-2” 就是这种语言的句子。
解释器就是要解析出来语句的含义。但是如何描述规则呢?
文法(语法)规则:
文法是用于描述语言的语法结构的形式规则。
1 | |
注意: 这里的符号“::=”表示“定义为”的意思,竖线 | 表示或,左右的其中一个,引号内为字符本身,引号外为语法。
上面规则描述为 :
表达式可以是一个值,也可以是plus或者minus运算,而plus和minus又是由表达式结合运算符构成,值的类型为整型数。
抽象语法树:
在计算机科学中,抽象语法树(AbstractSyntaxTree,AST),或简称语法树(Syntax tree),是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。
用树形来表示符合文法规则的句子。
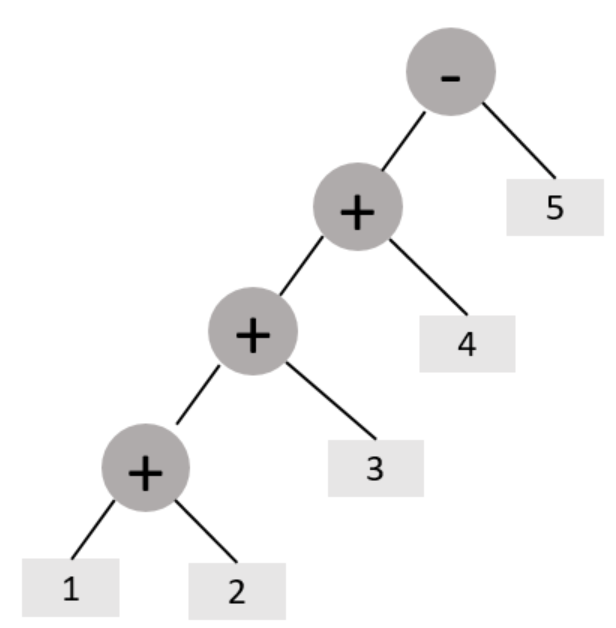
6.11.2 结构
解释器模式包含以下主要角色。
抽象表达式(Abstract Expression)角色:定义解释器的接口,约定解释器的解释操作,主要包含解释方法 interpret()。
终结符表达式(Terminal Expression)角色:是抽象表达式的子类,用来实现文法中与终结符相关的操作,文法中的每一个终结符都有一个具体终结表达式与之相对应。
非终结符表达式(Nonterminal Expression)角色:也是抽象表达式的子类,用来实现文法中与非终结符相关的操作,文法中的每条规则都对应于一个非终结符表达式。
环境(Context)角色:通常包含各个解释器需要的数据或是公共的功能,一般用来传递被所有解释器共享的数据,后面的解释器可以从这里获取这些值。
客户端(Client):主要任务是将需要分析的句子或表达式转换成使用解释器对象描述的抽象语法树,然后调用解释器的解释方法,当然也可以通过环境角色间接访问解释器的解释方法。
6.11.3 案例实现
【例】设计实现加减法的软件
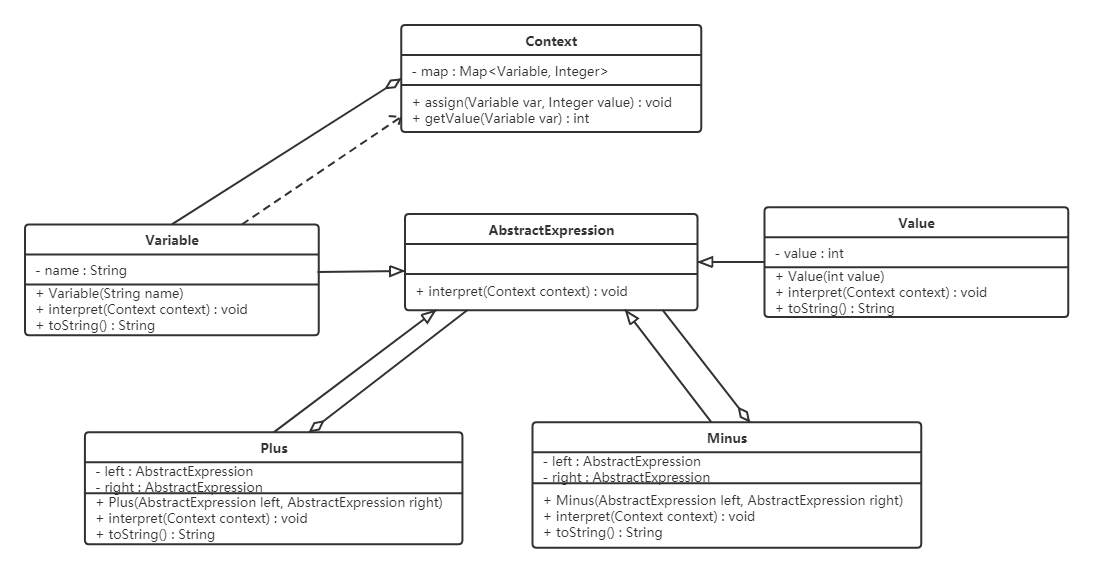
代码如下:
1 | |
6.11.4 优缺点
1,优点:
易于改变和扩展文法。
由于在解释器模式中使用类来表示语言的文法规则,因此可以通过继承等机制来改变或扩展文法。每一条文法规则都可以表示为一个类,因此可以方便地实现一个简单的语言。
实现文法较为容易。
在抽象语法树中每一个表达式节点类的实现方式都是相似的,这些类的代码编写都不会特别复杂。
增加新的解释表达式较为方便。
如果用户需要增加新的解释表达式只需要对应增加一个新的终结符表达式或非终结符表达式类,原有表达式类代码无须修改,符合 “开闭原则”。
2,缺点:
对于复杂文法难以维护。
在解释器模式中,每一条规则至少需要定义一个类,因此如果一个语言包含太多文法规则,类的个数将会急剧增加,导致系统难以管理和维护。
执行效率较低。
由于在解释器模式中使用了大量的循环和递归调用,因此在解释较为复杂的句子时其速度很慢,而且代码的调试过程也比较麻烦。
6.11.5 使用场景
当语言的文法较为简单,且执行效率不是关键问题时。
当问题重复出现,且可以用一种简单的语言来进行表达时。
当一个语言需要解释执行,并且语言中的句子可以表示为一个抽象语法树的时候。
7,自定义Spring框架
7.1 spring使用回顾
自定义spring框架前,先回顾一下spring框架的使用,从而分析spring的核心,并对核心功能进行模拟。
数据访问层。定义UserDao接口及其子实现类
1
2
3
4
5
6
7
8
9
10public interface UserDao {
public void add();
}
public class UserDaoImpl implements UserDao {
public void add() {
System.out.println("userDaoImpl ....");
}
}业务逻辑层。定义UserService接口及其子实现类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public interface UserService {
public void add();
}
public class UserServiceImpl implements UserService {
private UserDao userDao;
public void setUserDao(UserDao userDao) {
this.userDao = userDao;
}
public void add() {
System.out.println("userServiceImpl ...");
userDao.add();
}
}定义UserController类,使用main方法模拟controller层
1
2
3
4
5
6
7
8
9
10public class UserController {
public static void main(String[] args) {
//创建spring容器对象
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("applicationContext.xml");
//从IOC容器中获取UserService对象
UserService userService = applicationContext.getBean("userService", UserService.class);
//调用UserService对象的add方法
userService.add();
}
}编写配置文件。在类路径下编写一个名为ApplicationContext.xml的配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.springframework.org/schema/beans"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="userService" class="com.itheima.service.impl.UserServiceImpl">
<property name="userDao" ref="userDao"></property>
</bean>
<bean id="userDao" class="com.itheima.dao.impl.UserDaoImpl"></bean>
</beans>代码运行结果如下:
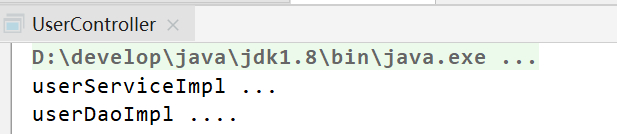
通过上面代码及结果可以看出:
- userService对象是从applicationContext容器对象获取到的,也就是userService对象交由spring进行管理。
- 上面结果可以看到调用了UserDao对象中的add方法,也就是说UserDao子实现类对象也交由spring管理了。
- UserService中的userDao变量我们并没有进行赋值,但是可以正常使用,说明spring已经将UserDao对象赋值给了userDao变量。
上面三点体现了Spring框架的IOC(Inversion of Control)和DI(Dependency Injection, DI)
7.2 spring核心功能结构
Spring大约有20个模块,由1300多个不同的文件构成。这些模块可以分为:
核心容器、AOP和设备支持、数据访问与集成、Web组件、通信报文和集成测试等,下面是 Spring 框架的总体架构图:
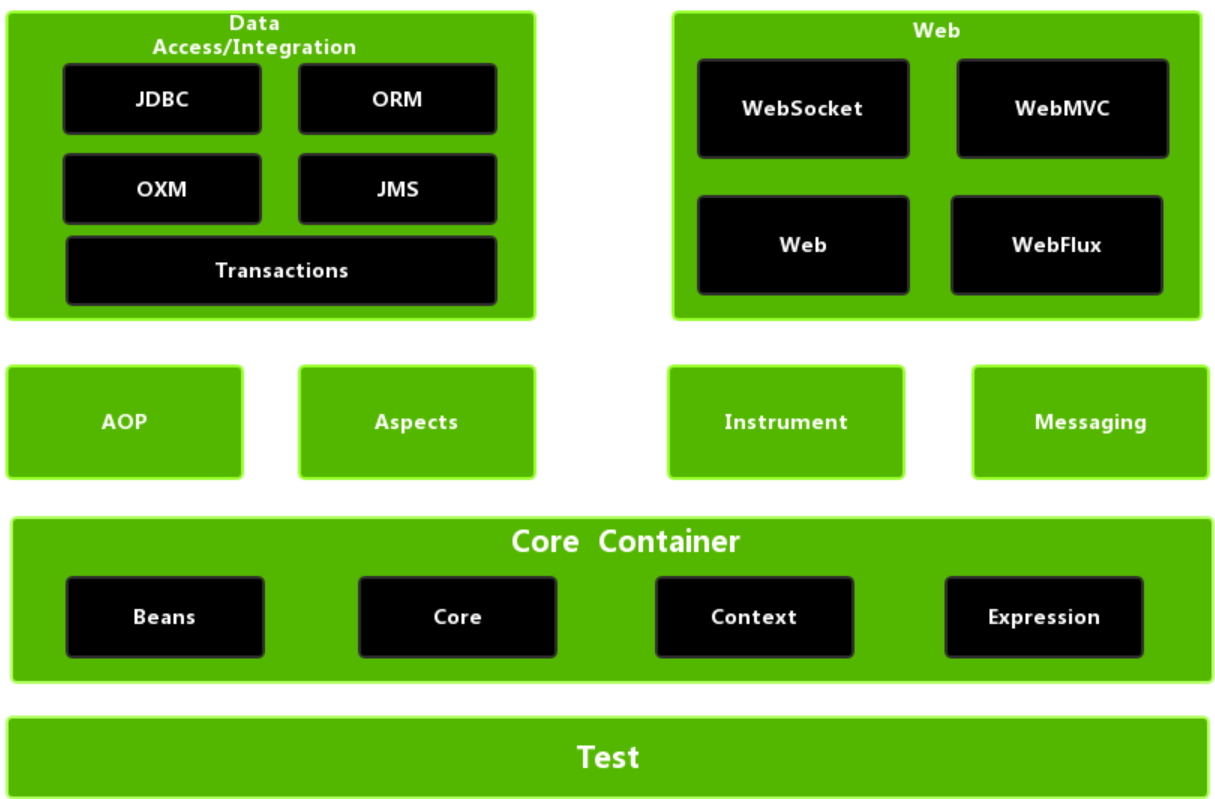
核心容器由 beans、core、context 和 expression(Spring Expression Language,SpEL)4个模块组成。
- spring-beans和spring-core模块是Spring框架的核心模块,包含了控制反转(Inversion of Control,IOC)和依赖注入(Dependency Injection,DI)。BeanFactory使用控制反转对应用程序的配置和依赖性规范与实际的应用程序代码进行了分离。BeanFactory属于延时加载,也就是说在实例化容器对象后并不会自动实例化Bean,只有当Bean被使用时,BeanFactory才会对该 Bean 进行实例化与依赖关系的装配。
- spring-context模块构架于核心模块之上,扩展了BeanFactory,为它添加了Bean生命周期控制、框架事件体系及资源加载透明化等功能。此外,该模块还提供了许多企业级支持,如邮件访问、远程访问、任务调度等,ApplicationContext 是该模块的核心接口,它的超类是 BeanFactory。与BeanFactory不同,ApplicationContext实例化后会自动对所有的单实例Bean进行实例化与依赖关系的装配,使之处于待用状态。
- spring-context-support模块是对Spring IoC容器及IoC子容器的扩展支持。
- spring-context-indexer模块是Spring的类管理组件和Classpath扫描组件。
- spring-expression 模块是统一表达式语言(EL)的扩展模块,可以查询、管理运行中的对象,同时也可以方便地调用对象方法,以及操作数组、集合等。它的语法类似于传统EL,但提供了额外的功能,最出色的要数函数调用和简单字符串的模板函数。EL的特性是基于Spring产品的需求而设计的,可以非常方便地同Spring IoC进行交互。
7.1.1 bean概述
Spring 就是面向 Bean 的编程(BOP,Bean Oriented Programming),Bean 在 Spring 中处于核心地位。Bean对于Spring的意义就像Object对于OOP的意义一样,Spring中没有Bean也就没有Spring存在的意义。Spring IoC容器通过配置文件或者注解的方式来管理bean对象之间的依赖关系。
spring中bean用于对一个类进行封装。如下面的配置:
1 | |
为什么Bean如此重要呢?
- spring 将bean对象交由一个叫IOC容器进行管理。
- bean对象之间的依赖关系在配置文件中体现,并由spring完成。
7.3 Spring IOC相关接口分析
7.3.1 BeanFactory解析
Spring中Bean的创建是典型的工厂模式,这一系列的Bean工厂,即IoC容器,为开发者管理对象之间的依赖关系提供了很多便利和基础服务,在Spring中有许多IoC容器的实现供用户选择,其相互关系如下图所示。
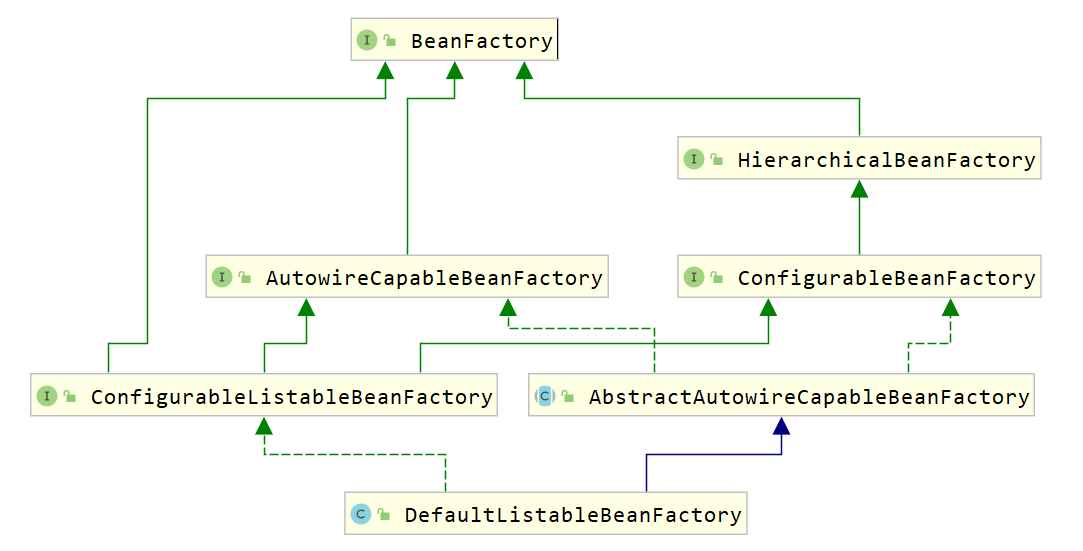
其中,BeanFactory作为最顶层的一个接口,定义了IoC容器的基本功能规范,BeanFactory有三个重要的子接口:ListableBeanFactory、HierarchicalBeanFactory和AutowireCapableBeanFactory。但是从类图中我们可以发现最终的默认实现类是DefaultListableBeanFactory,它实现了所有的接口。
那么为何要定义这么多层次的接口呢?
每个接口都有它的使用场合,主要是为了区分在Spring内部操作过程中对象的传递和转化,对对象的数据访问所做的限制。例如,
- ListableBeanFactory接口表示这些Bean可列表化。
- HierarchicalBeanFactory表示这些Bean 是有继承关系的,也就是每个 Bean 可能有父 Bean
- AutowireCapableBeanFactory 接口定义Bean的自动装配规则。
这三个接口共同定义了Bean的集合、Bean之间的关系及Bean行为。最基本的IoC容器接口是BeanFactory,来看一下它的源码:
1 | |
在BeanFactory里只对IoC容器的基本行为做了定义,根本不关心你的Bean是如何定义及怎样加载的。正如我们只关心能从工厂里得到什么产品,不关心工厂是怎么生产这些产品的。
BeanFactory有一个很重要的子接口,就是ApplicationContext接口,该接口主要来规范容器中的bean对象是非延时加载,即在创建容器对象的时候就对象bean进行初始化,并存储到一个容器中。

要知道工厂是如何产生对象的,我们需要看具体的IoC容器实现,Spring提供了许多IoC容器实现,比如:
- ClasspathXmlApplicationContext : 根据类路径加载xml配置文件,并创建IOC容器对象。
- FileSystemXmlApplicationContext :根据系统路径加载xml配置文件,并创建IOC容器对象。
- AnnotationConfigApplicationContext :加载注解类配置,并创建IOC容器。
7.3.2 BeanDefinition解析
Spring IoC容器管理我们定义的各种Bean对象及其相互关系,而Bean对象在Spring实现中是以BeanDefinition来描述的,如下面配置文件
1 | |
其继承体系如下图所示。
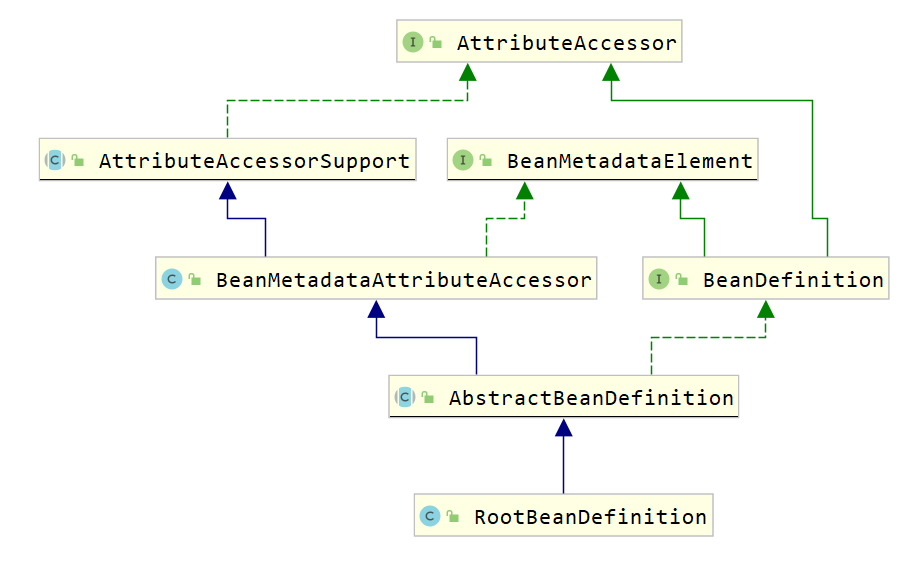
7.3.3 BeanDefinitionReader解析
Bean的解析过程非常复杂,功能被分得很细,因为这里需要被扩展的地方很多,必须保证足够的灵活性,以应对可能的变化。Bean的解析主要就是对Spring配置文件的解析。这个解析过程主要通过BeanDefinitionReader来完成,看看Spring中BeanDefinitionReader的类结构图,如下图所示。
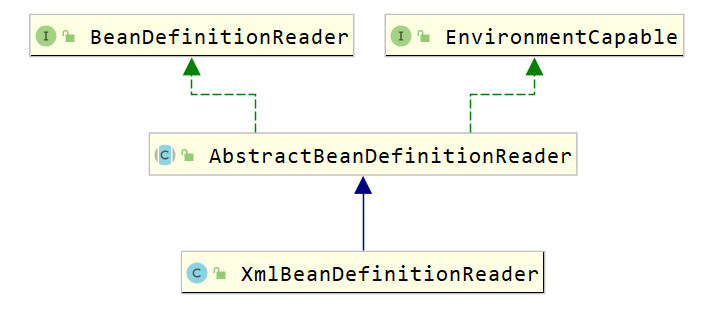
看看BeanDefinitionReader接口定义的功能来理解它具体的作用:
1 | |
7.3.4 BeanDefinitionRegistry解析
BeanDefinitionReader用来解析bean定义,并封装BeanDefinition对象,而我们定义的配置文件中定义了很多bean标签,所以就有一个问题,解析的BeanDefinition对象存储到哪儿?答案就是BeanDefinition的注册中心,而该注册中心顶层接口就是BeanDefinitionRegistry。
1 | |
继承结构图如下:
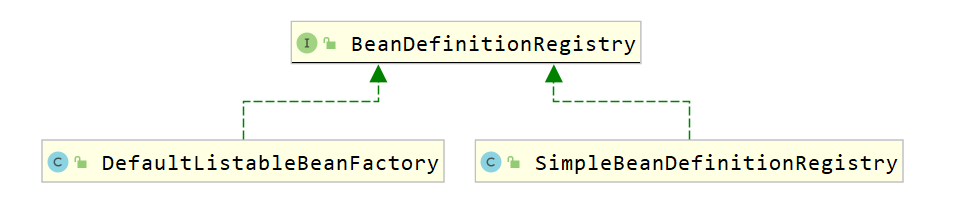
从上面类图可以看到BeanDefinitionRegistry接口的子实现类主要有以下几个:
DefaultListableBeanFactory
在该类中定义了如下代码,就是用来注册bean
1
private final Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>(256);SimpleBeanDefinitionRegistry
在该类中定义了如下代码,就是用来注册bean
1
private final Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>(64);
7.3.5 创建容器
ClassPathXmlApplicationContext对Bean配置资源的载入是从refresh()方法开始的。refresh()方法是一个模板方法,规定了 IoC 容器的启动流程,有些逻辑要交给其子类实现。它对 Bean 配置资源进行载入,ClassPathXmlApplicationContext通过调用其父类AbstractApplicationContext的refresh()方法启动整个IoC容器对Bean定义的载入过程。
7.4 自定义SpringIOC
现要对下面的配置文件进行解析,并自定义Spring框架的IOC对涉及到的对象进行管理。
1 | |
7.4.1 定义bean相关的pojo类
7.4.1.1 PropertyValue类
用于封装bean的属性,体现到上面的配置文件就是封装bean标签的子标签property标签数据。
1 | |
7.4.1.2 MutablePropertyValues类
一个bean标签可以有多个property子标签,所以再定义一个MutablePropertyValues类,用来存储并管理多个PropertyValue对象。
1 | |
7.4.1.3 BeanDefinition类
BeanDefinition类用来封装bean信息的,主要包含id(即bean对象的名称)、class(需要交由spring管理的类的全类名)及子标签property数据。
1 | |
7.4.2 定义注册表相关类
7.4.2.1 BeanDefinitionRegistry接口
BeanDefinitionRegistry接口定义了注册表的相关操作,定义如下功能:
- 注册BeanDefinition对象到注册表中
- 从注册表中删除指定名称的BeanDefinition对象
- 根据名称从注册表中获取BeanDefinition对象
- 判断注册表中是否包含指定名称的BeanDefinition对象
- 获取注册表中BeanDefinition对象的个数
- 获取注册表中所有的BeanDefinition的名称
1 | |
7.4.2.2 SimpleBeanDefinitionRegistry类
该类实现了BeanDefinitionRegistry接口,定义了Map集合作为注册表容器。
1 | |
7.4.3 定义解析器相关类
7.4.3.1 BeanDefinitionReader接口
BeanDefinitionReader是用来解析配置文件并在注册表中注册bean的信息。定义了两个规范:
- 获取注册表的功能,让外界可以通过该对象获取注册表对象。
- 加载配置文件,并注册bean数据。
1 | |
7.4.3.2 XmlBeanDefinitionReader类
XmlBeanDefinitionReader类是专门用来解析xml配置文件的。该类实现BeanDefinitionReader接口并实现接口中的两个功能。
1 | |
7.4.4 IOC容器相关类
7.4.4.1 BeanFactory接口
在该接口中定义IOC容器的统一规范即获取bean对象。
1 | |
7.4.4.2 ApplicationContext接口
该接口的所以的子实现类对bean对象的创建都是非延时的,所以在该接口中定义 refresh() 方法,该方法主要完成以下两个功能:
- 加载配置文件。
- 根据注册表中的BeanDefinition对象封装的数据进行bean对象的创建。
1 | |
7.4.4.3 AbstractApplicationContext类
作为ApplicationContext接口的子类,所以该类也是非延时加载,所以需要在该类中定义一个Map集合,作为bean对象存储的容器。
声明BeanDefinitionReader类型的变量,用来进行xml配置文件的解析,符合单一职责原则。
BeanDefinitionReader类型的对象创建交由子类实现,因为只有子类明确到底创建BeanDefinitionReader哪儿个子实现类对象。
1 | |
注意:该类finishBeanInitialization()方法中调用getBean()方法使用到了模板方法模式。
7.4.4.4 ClassPathXmlApplicationContext类
该类主要是加载类路径下的配置文件,并进行bean对象的创建,主要完成以下功能:
- 在构造方法中,创建BeanDefinitionReader对象。
- 在构造方法中,调用refresh()方法,用于进行配置文件加载、创建bean对象并存储到容器中。
- 重写父接口中的getBean()方法,并实现依赖注入操作。
1 | |
7.4.5 自定义Spring IOC总结
7.4.5.1 使用到的设计模式
- 工厂模式。这个使用工厂模式 + 配置文件的方式。
- 单例模式。Spring IOC管理的bean对象都是单例的,此处的单例不是通过构造器进行单例的控制的,而是spring框架对每一个bean只创建了一个对象。
- 模板方法模式。AbstractApplicationContext类中的finishBeanInitialization()方法调用了子类的getBean()方法,因为getBean()的实现和环境息息相关。
- 迭代器模式。对于MutablePropertyValues类定义使用到了迭代器模式,因为此类存储并管理PropertyValue对象,也属于一个容器,所以给该容器提供一个遍历方式。
spring框架其实使用到了很多设计模式,如AOP使用到了代理模式,选择JDK代理或者CGLIB代理使用到了策略模式,还有适配器模式,装饰者模式,观察者模式等。
7.4.5.2 符合大部分设计原则
7.4.5.3 整个设计和Spring的设计还是有一定的出入
spring框架底层是很复杂的,进行了很深入的封装,并对外提供了很好的扩展性。而我们自定义SpringIOC有以下几个目的:
- 了解Spring底层对对象的大体管理机制。
- 了解设计模式在具体的开发中的使用。
- 以后学习spring源码,通过该案例的实现,可以降低spring学习的入门成本。
设计模式-day01
1,设计模式概述
1.1 软件设计模式的产生背景
“设计模式”最初并不是出现在软件设计中,而是被用于建筑领域的设计中。
1977年美国著名建筑大师、加利福尼亚大学伯克利分校环境结构中心主任克里斯托夫·亚历山大(Christopher Alexander)在他的著作《建筑模式语言:城镇、建筑、构造》中描述了一些常见的建筑设计问题,并提出了 253 种关于对城镇、邻里、住宅、花园和房间等进行设计的基本模式。
1990年软件工程界开始研讨设计模式的话题,后来召开了多次关于设计模式的研讨会。直到1995 年,艾瑞克·伽马(ErichGamma)、理査德·海尔姆(Richard Helm)、拉尔夫·约翰森(Ralph Johnson)、约翰·威利斯迪斯(John Vlissides)等 4 位作者合作出版了《设计模式:可复用面向对象软件的基础》一书,在此书中收录了 23 个设计模式,这是设计模式领域里程碑的事件,导致了软件设计模式的突破。这 4 位作者在软件开发领域里也以他们的“四人组”(Gang of Four,GoF)著称。
1.2 软件设计模式的概念
软件设计模式(Software Design Pattern),又称设计模式,是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结。==它描==述了在软件设计过程中的一些不断重复发生的问题,以及该问题的解决方案。也就是说,它是解决特定问题的一系列套路,是前辈们的代码设计经验的总结,具有一定的普遍性,可以反复使用。
1.3 学习设计模式的必要性
设计模式的本质是面向对象设计原则的实际运用,是对类的封装性、继承性和多态性以及类的关联关系和组合关系的充分理解。
正确使用设计模式具有以下优点。
- 可以提高程序员的思维能力、编程能力和设计能力。
- 使程序设计更加标准化、代码编制更加工程化,使软件开发效率大大提高,从而缩短软件的开发周期。
- 使设计的代码可重用性高、可读性强、可靠性高、灵活性好、可维护性强。
1.4 设计模式分类
创建型模式
用于描述“怎样创建对象”,它的主要特点是“==将对象的创建与使用分离==”。GoF(四人组)书中提供了单例、原型、工厂方法、抽象工厂、建造者等 5 种创建型模式。
结构型模式
用于描述如何==将类或对象按某种布局组成更大的结构==,GoF(四人组)书中提供了代理、适配器、桥接、装饰、外观、享元、组合等 7 种结构型模式。
行为型模式
用于描述==类或对象之间怎样相互协作共同完成单个对象无法单独完成的任务==,以及怎样分配职责。GoF(四人组)书中提供了模板方法、策略、命令、职责链、状态、观察者、中介者、迭代器、访问者、备忘录、解释器等 11 种行为型模式。
2,UML图
统一建模语言(Unified Modeling Language,UML)是用来设计软件的可视化建模语言。它的特点是简单、统一、图形化、能表达软件设计中的动态与静态信息。
UML 从目标系统的不同角度出发,定义了用例图、类图、对象图、状态图、活动图、时序图、协作图、构件图、部署图等 9 种图。
2.1 类图概述
类图(Class diagram)是显示了模型的静态结构,特别是模型中存在的类、类的内部结构以及它们与其他类的关系等。类图不显示暂时性的信息。类图是面向对象建模的主要组成部分。
2.2 类图的作用
- 在软件工程中,类图是一种静态的结构图,描述了系统的类的集合,类的属性和类之间的关系,可以简化了人们对系统的理解;
- 类图是系统分析和设计阶段的重要产物,是系统编码和测试的重要模型。
2.3 类图表示法
2.3.1 类的表示方式
在UML类图中,类使用包含类名、属性(field) 和方法(method) 且带有分割线的矩形来表示,比如下图表示一个Employee类,它包含name,age和address这3个属性,以及work()方法。

属性/方法名称前加的加号和减号表示了这个属性/方法的可见性,UML类图中表示可见性的符号有三种:
+:表示public
-:表示private
#:表示protected
属性的完整表示方式是: 可见性 名称 :类型 [ = 缺省值]
方法的完整表示方式是: 可见性 名称(参数列表) [ : 返回类型]
注意:
1,中括号中的内容表示是可选的
2,也有将类型放在变量名前面,返回值类型放在方法名前面
举个栗子:

上图Demo类定义了三个方法:
- method()方法:修饰符为public,没有参数,没有返回值。
- method1()方法:修饰符为private,没有参数,返回值类型为String。
- method2()方法:修饰符为protected,接收两个参数,第一个参数类型为int,第二个参数类型为String,返回值类型是int。
2.3.2 类与类之间关系的表示方式
2.3.2.1 关联关系
关联关系是对象之间的一种引用关系,用于表示一类对象与另一类对象之间的联系,如老师和学生、师傅和徒弟、丈夫和妻子等。关联关系是类与类之间最常用的一种关系,分为一般关联关系、聚合关系和组合关系。我们先介绍一般关联。
关联又可以分为单向关联,双向关联,自关联。
1,单向关联
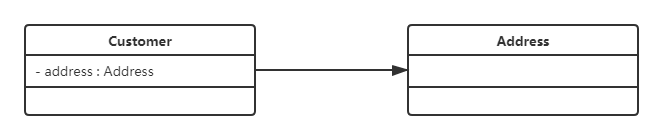
在UML类图中单向关联用一个带箭头的实线表示。上图表示每个顾客都有一个地址,这通过让Customer类持有一个类型为Address的成员变量类实现。
2,双向关联

从上图中我们很容易看出,所谓的双向关联就是双方各自持有对方类型的成员变量。
在UML类图中,双向关联用一个不带箭头的直线表示。上图中在Customer类中维护一个List<Product>,表示一个顾客可以购买多个商品;在Product类中维护一个Customer类型的成员变量表示这个产品被哪个顾客所购买。
3,自关联
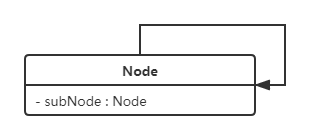
自关联在UML类图中用一个带有箭头且指向自身的线表示。上图的意思就是Node类包含类型为Node的成员变量,也就是“自己包含自己”。
2.3.2.2 聚合关系
聚合关系是关联关系的一种,是强关联关系,是==整体和部分之间的关系==。
聚合关系也是通过成员对象来实现的,其中成员对象是整体对象的一部分,但是成员对象可以脱离整体对象而独立存在。例如,学校与老师的关系,学校包含老师,但如果学校停办了,老师依然存在。
在 UML 类图中,聚合关系可以用带空心菱形的实线来表示,菱形指向整体。下图所示是大学和教师的关系图:

2.3.2.3 组合关系
组合表示类之间的整体与部分的关系,但它是一种更强烈的聚合关系。
在组合关系中,整体对象可以控制部分对象的生命周期,一旦整体对象不存在,部分对象也将不存在,部分对象不能脱离整体对象而存在。例如,头和嘴的关系,没有了头,嘴也就不存在了。
在 UML 类图中,组合关系用带实心菱形的实线来表示,菱形指向整体。下图所示是头和嘴的关系图:

2.3.2.4 依赖关系
依赖关系是一种使用关系,它是对象之间耦合度最弱的一种关联方式,是临时性的关联。在代码中,某个类的方法通过局部变量、方法的参数或者对静态方法的调用来访问另一个类(被依赖类)中的某些方法来完成一些职责。
在 UML 类图中,依赖关系使用带箭头的虚线来表示,箭头从使用类指向被依赖的类。下图所示是司机和汽车的关系图,司机驾驶汽车:
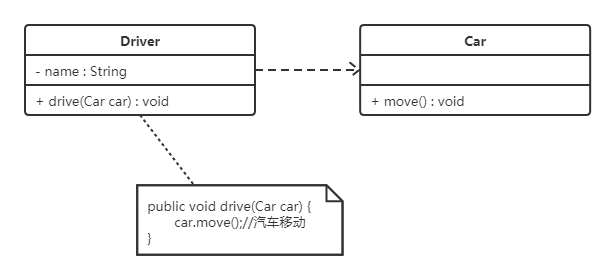
2.3.2.5 继承关系
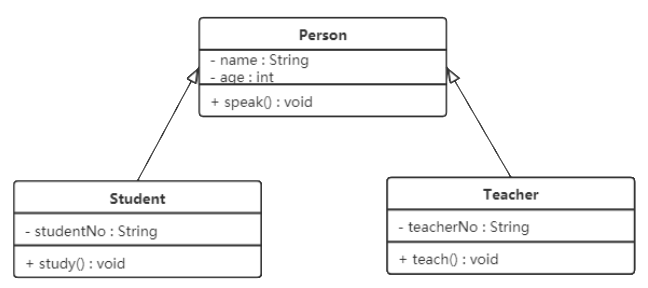
继承关系是对象之间耦合度最大的一种关系,表示一般与特殊的关系,是父类与子类之间的关系,是一种继承关系。
在 UML 类图中,泛化关系用带空心三角箭头的实线来表示,箭头从子类指向父类。在代码实现时,使用面向对象的继承机制来实现泛化关系。例如,Student 类和 Teacher 类都是 Person 类的子类,其类图如下图所示:
2.3.2.6 实现关系
实现关系是接口与实现类之间的关系。在这种关系中,类实现了接口,类中的操作实现了接口中所声明的所有的抽象操作。
在 UML 类图中,实现关系使用带空心三角箭头的虚线来表示,箭头从实现类指向接口。例如,汽车和船实现了交通工具,其类图如图 9 所示。
3,软件设计原则
在软件开发中,为了提高软件系统的可维护性和可复用性,增加软件的可扩展性和灵活性,程序员要尽量根据6条原则来开发程序,从而提高软件开发效率、节约软件开发成本和维护成本。
3.1 开闭原则
对扩展开放,对修改关闭。在程序需要进行拓展的时候,不能去修改原有的代码,实现一个热插拔的效果。简言之,是为了使程序的扩展性好,易于维护和升级。
想要达到这样的效果,我们需要使用接口和抽象类。
因为抽象灵活性好,适应性广,只要抽象的合理,可以基本保持软件架构的稳定。而软件中易变的细节可以从抽象派生来的实现类来进行扩展,当软件需要发生变化时,只需要根据需求重新派生一个实现类来扩展就可以了。
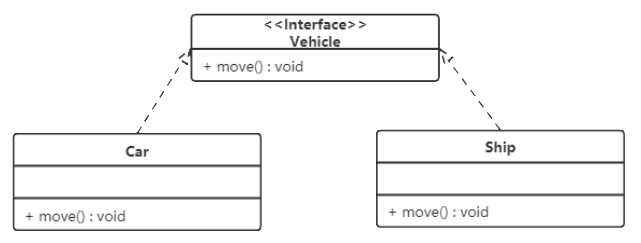
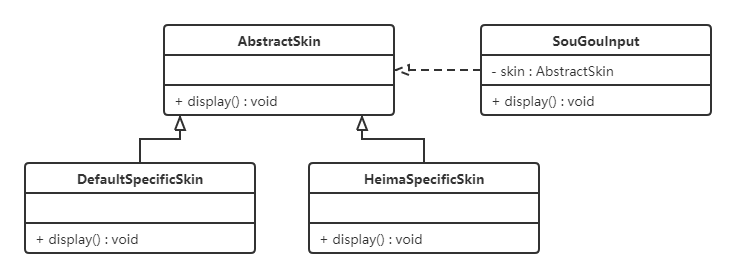
下面以 搜狗输入法 的皮肤为例介绍开闭原则的应用。
【例】搜狗输入法 的皮肤设计。
分析:搜狗输入法 的皮肤是输入法背景图片、窗口颜色和声音等元素的组合。用户可以根据自己的喜爱更换自己的输入法的皮肤,也可以从网上下载新的皮肤。这些皮肤有共同的特点,可以为其定义一个抽象类(AbstractSkin),而每个具体的皮肤(DefaultSpecificSkin和HeimaSpecificSkin)是其子类。用户窗体可以根据需要选择或者增加新的主题,而不需要修改原代码,所以它是满足开闭原则的。
3.2 里氏代换原则
里氏代换原则是面向对象设计的基本原则之一。
里氏代换原则:任何基类可以出现的地方,子类一定可以出现。通俗理解:子类可以扩展父类的功能,但不能改变父类原有的功能。换句话说,子类继承父类时,除添加新的方法完成新增功能外,尽量不要重写父类的方法。
如果通过重写父类的方法来完成新的功能,这样写起来虽然简单,但是整个继承体系的可复用性会比较差,特别是运用多态比较频繁时,程序运行出错的概率会非常大。
下面看一个里氏替换原则中经典的一个例子
【例】正方形不是长方形。
在数学领域里,正方形毫无疑问是长方形,它是一个长宽相等的长方形。所以,我们开发的一个与几何图形相关的软件系统,就可以顺理成章的让正方形继承自长方形。
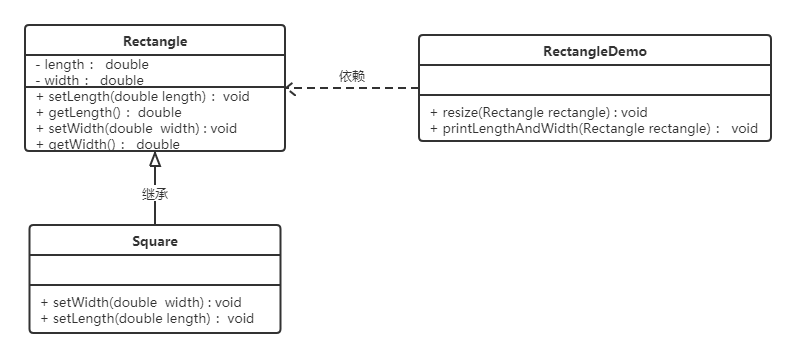
代码如下:
长方形类(Rectangle):
1 | |
正方形(Square):
由于正方形的长和宽相同,所以在方法setLength和setWidth中,对长度和宽度都需要赋相同值。
1 | |
类RectangleDemo是我们的软件系统中的一个组件,它有一个resize方法依赖基类Rectangle,resize方法是RectandleDemo类中的一个方法,用来实现宽度逐渐增长的效果。
1 | |
我们运行一下这段代码就会发现,假如我们把一个普通长方形作为参数传入resize方法,就会看到长方形宽度逐渐增长的效果,当宽度大于长度,代码就会停止,这种行为的结果符合我们的预期;假如我们再把一个正方形作为参数传入resize方法后,就会看到正方形的宽度和长度都在不断增长,代码会一直运行下去,直至系统产生溢出错误。所以,普通的长方形是适合这段代码的,正方形不适合。
我们得出结论:在resize方法中,Rectangle类型的参数是不能被Square类型的参数所代替,如果进行了替换就得不到预期结果。因此,Square类和Rectangle类之间的继承关系违反了里氏代换原则,它们之间的继承关系不成立,正方形不是长方形。
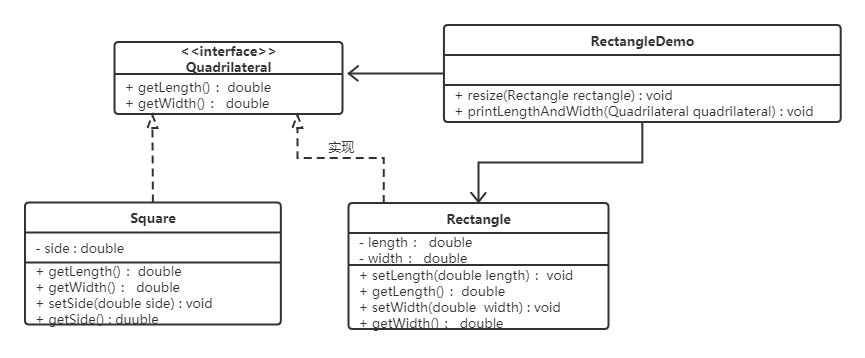
如何改进呢?此时我们需要重新设计他们之间的关系。抽象出来一个四边形接口(Quadrilateral),让Rectangle类和Square类实现Quadrilateral接口
3.3 依赖倒转原则
高层模块不应该依赖低层模块,两者都应该依赖其抽象;抽象不应该依赖细节,细节应该依赖抽象。简单的说就是要求对抽象进行编程,不要对实现进行编程,这样就降低了客户与实现模块间的耦合。
下面看一个例子来理解依赖倒转原则
【例】组装电脑
现要组装一台电脑,需要配件cpu,硬盘,内存条。只有这些配置都有了,计算机才能正常的运行。选择cpu有很多选择,如Intel,AMD等,硬盘可以选择希捷,西数等,内存条可以选择金士顿,海盗船等。
类图如下:
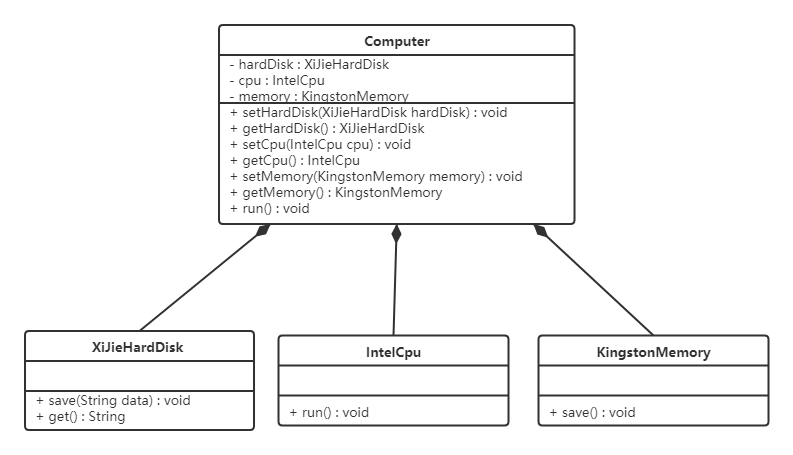
代码如下:
希捷硬盘类(XiJieHardDisk):
1 | |
Intel处理器(IntelCpu):
1 | |
金士顿内存条(KingstonMemory):
1 | |
电脑(Computer):
1 | |
测试类(TestComputer):
测试类用来组装电脑。
1 | |
上面代码可以看到已经组装了一台电脑,但是似乎组装的电脑的cpu只能是Intel的,内存条只能是金士顿的,硬盘只能是希捷的,这对用户肯定是不友好的,用户有了机箱肯定是想按照自己的喜好,选择自己喜欢的配件。
根据依赖倒转原则进行改进:
代码我们只需要修改Computer类,让Computer类依赖抽象(各个配件的接口),而不是依赖于各个组件具体的实现类。
类图如下:
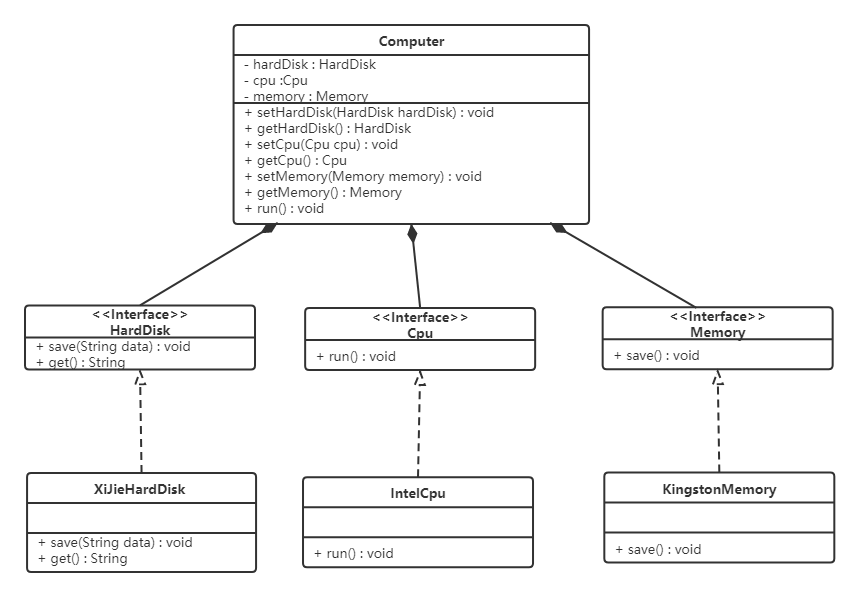
电脑(Computer):
1 | |
面向对象的开发很好的解决了这个问题,一般情况下抽象的变化概率很小,让用户程序依赖于抽象,实现的细节也依赖于抽象。即使实现细节不断变动,只要抽象不变,客户程序就不需要变化。这大大降低了客户程序与实现细节的耦合度。
3.4 接口隔离原则
客户端不应该被迫依赖于它不使用的方法;一个类对另一个类的依赖应该建立在最小的接口上。
下面看一个例子来理解接口隔离原则
【例】安全门案例
我们需要创建一个黑马品牌的安全门,该安全门具有防火、防水、防盗的功能。可以将防火,防水,防盗功能提取成一个接口,形成一套规范。类图如下:
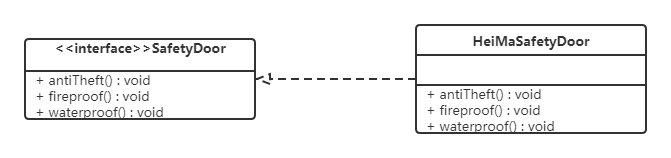
上面的设计我们发现了它存在的问题,黑马品牌的安全门具有防盗,防水,防火的功能。现在如果我们还需要再创建一个传智品牌的安全门,而该安全门只具有防盗、防水功能呢?很显然如果实现SafetyDoor接口就违背了接口隔离原则,那么我们如何进行修改呢?看如下类图:
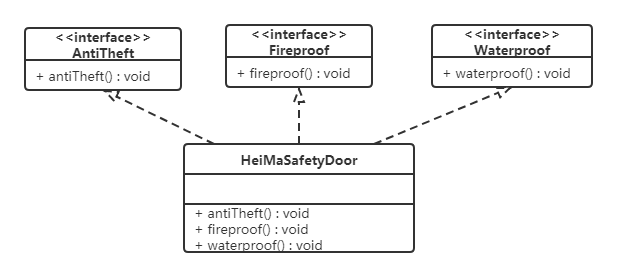
代码如下:
AntiTheft(接口):
1 | |
Fireproof(接口):
1 | |
Waterproof(接口):
1 | |
HeiMaSafetyDoor(类):
1 | |
ItcastSafetyDoor(类):
1 | |
3.5 迪米特法则
迪米特法则又叫最少知识原则。
只和你的直接朋友交谈,不跟“陌生人”说话(Talk only to your immediate friends and not to strangers)。
其含义是:如果两个软件实体无须直接通信,那么就不应当发生直接的相互调用,可以通过第三方转发该调用。其目的是降低类之间的耦合度,提高模块的相对独立性。
迪米特法则中的“朋友”是指:当前对象本身、当前对象的成员对象、当前对象所创建的对象、当前对象的方法参数等,这些对象同当前对象存在关联、聚合或组合关系,可以直接访问这些对象的方法。
下面看一个例子来理解迪米特法则
【例】明星与经纪人的关系实例
明星由于全身心投入艺术,所以许多日常事务由经纪人负责处理,如和粉丝的见面会,和媒体公司的业务洽淡等。这里的经纪人是明星的朋友,而粉丝和媒体公司是陌生人,所以适合使用迪米特法则。
类图如下:
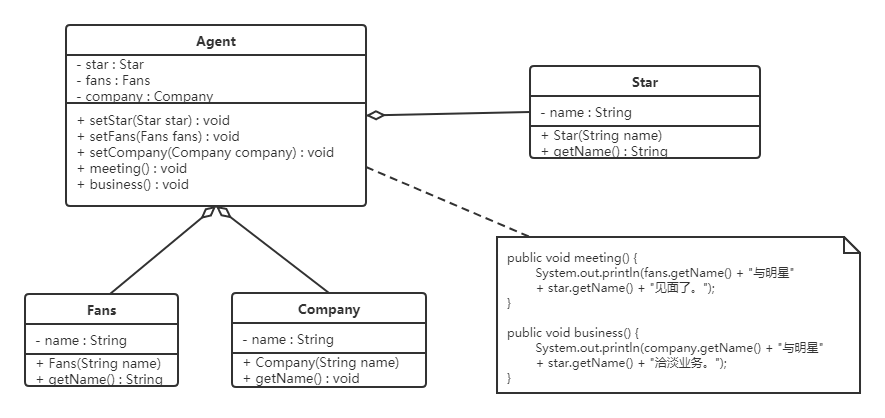
代码如下:
明星类(Star)
1 | |
粉丝类(Fans)
1 | |
媒体公司类(Company)
1 | |
经纪人类(Agent)
1 | |
3.6 合成复用原则
合成复用原则是指:尽量先使用组合或者聚合等关联关系来实现,其次才考虑使用继承关系来实现。
通常类的复用分为继承复用和合成复用两种。
继承复用虽然有简单和易实现的优点,但它也存在以下缺点:
- 继承复用破坏了类的封装性。因为继承会将父类的实现细节暴露给子类,父类对子类是透明的,所以这种复用又称为“白箱”复用。
- 子类与父类的耦合度高。父类的实现的任何改变都会导致子类的实现发生变化,这不利于类的扩展与维护。
- 它限制了复用的灵活性。从父类继承而来的实现是静态的,在编译时已经定义,所以在运行时不可能发生变化。
采用组合或聚合复用时,可以将已有对象纳入新对象中,使之成为新对象的一部分,新对象可以调用已有对象的功能,它有以下优点:
- 它维持了类的封装性。因为成分对象的内部细节是新对象看不见的,所以这种复用又称为“黑箱”复用。
- 对象间的耦合度低。可以在类的成员位置声明抽象。
- 复用的灵活性高。这种复用可以在运行时动态进行,新对象可以动态地引用与成分对象类型相同的对象。
下面看一个例子来理解合成复用原则
【例】汽车分类管理程序
汽车按“动力源”划分可分为汽油汽车、电动汽车等;按“颜色”划分可分为白色汽车、黑色汽车和红色汽车等。如果同时考虑这两种分类,其组合就很多。类图如下:
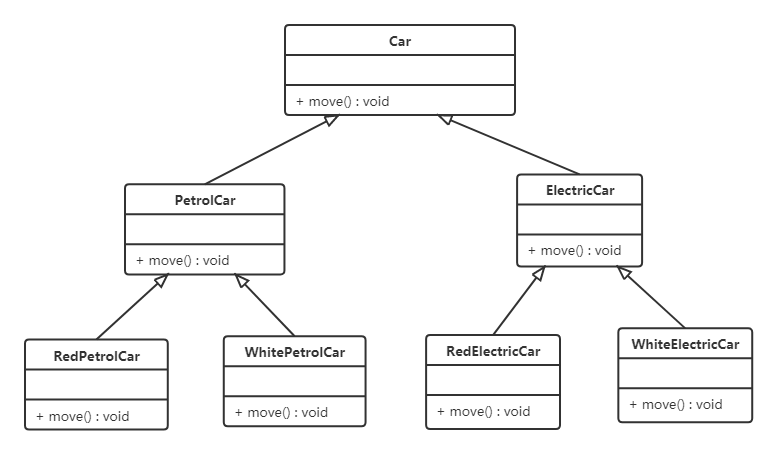
从上面类图我们可以看到使用继承复用产生了很多子类,如果现在又有新的动力源或者新的颜色的话,就需要再定义新的类。我们试着将继承复用改为聚合复用看一下。
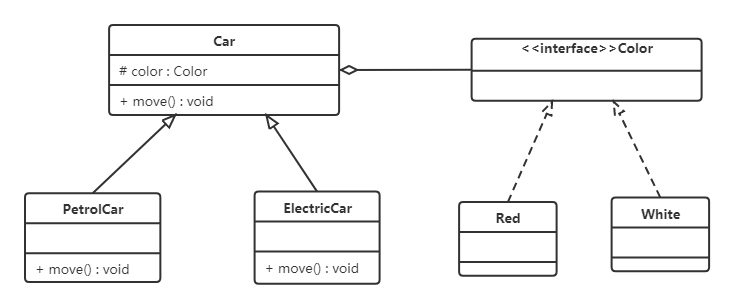
4,创建者模式
创建型模式的主要关注点是“怎样创建对象?”,它的主要特点是“将对象的创建与使用分离”。
这样可以降低系统的耦合度,使用者不需要关注对象的创建细节。
创建型模式分为:
- 单例模式
- 工厂方法模式
- 抽象工程模式
- 原型模式
- 建造者模式
4.1 单例设计模式
单例模式(Singleton Pattern)是 Java 中最简单的设计模式之一。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。这个类提供了一种访问其唯一的对象的方式,可以直接访问,不需要实例化该类的对象。
4.1.1 单例模式的结构
单例模式的主要有以下角色:
- 单例类。只能创建一个实例的类
- 访问类。使用单例类
4.1.2 单例模式的实现
单例设计模式分类两种:
饿汉式:类加载就会导致该单实例对象被创建
懒汉式:类加载不会导致该单实例对象被创建,而是首次使用该对象时才会创建
饿汉式-方式1(静态变量方式)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16/**
* 饿汉式
* 静态变量创建类的对象
*/
public class Singleton {
//私有构造方法
private Singleton() {}
//在成员位置创建该类的对象
private static Singleton instance = new Singleton();
//对外提供静态方法获取该对象
public static Singleton getInstance() {
return instance;
}
}说明:
该方式在成员位置声明Singleton类型的静态变量,并创建Singleton类的对象instance。instance对象是随着类的加载而创建的。如果该对象足够大的话,而一直没有使用就会造成内存的浪费。
饿汉式-方式2(静态代码块方式)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21/**
* 恶汉式
* 在静态代码块中创建该类对象
*/
public class Singleton {
//私有构造方法
private Singleton() {}
//在成员位置创建该类的对象
private static Singleton instance;
static {
instance = new Singleton();
}
//对外提供静态方法获取该对象
public static Singleton getInstance() {
return instance;
}
}说明:
该方式在成员位置声明Singleton类型的静态变量,而对象的创建是在静态代码块中,也是对着类的加载而创建。所以和饿汉式的方式1基本上一样,当然该方式也存在内存浪费问题。
懒汉式-方式1(线程不安全)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20/**
* 懒汉式
* 线程不安全
*/
public class Singleton {
//私有构造方法
private Singleton() {}
//在成员位置创建该类的对象
private static Singleton instance;
//对外提供静态方法获取该对象
public static Singleton getInstance() {
if(instance == null) {
instance = new Singleton();
}
return instance;
}
}说明:
从上面代码我们可以看出该方式在成员位置声明Singleton类型的静态变量,并没有进行对象的赋值操作,那么什么时候赋值的呢?当调用getInstance()方法获取Singleton类的对象的时候才创建Singleton类的对象,这样就实现了懒加载的效果。但是,如果是多线程环境,会出现线程安全问题。
懒汉式-方式2(线程安全)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20/**
* 懒汉式
* 线程安全
*/
public class Singleton {
//私有构造方法
private Singleton() {}
//在成员位置创建该类的对象
private static Singleton instance;
//对外提供静态方法获取该对象
public static synchronized Singleton getInstance() {
if(instance == null) {
instance = new Singleton();
}
return instance;
}
}说明:
该方式也实现了懒加载效果,同时又解决了线程安全问题。但是在getInstance()方法上添加了synchronized关键字,导致该方法的执行效果特别低。从上面代码我们可以看出,其实就是在初始化instance的时候才会出现线程安全问题,一旦初始化完成就不存在了。
懒汉式-方式3(双重检查锁)
再来讨论一下懒汉模式中加锁的问题,对于
getInstance()方法来说,绝大部分的操作都是读操作,读操作是线程安全的,所以我们没必让每个线程必须持有锁才能调用该方法,我们需要调整加锁的时机。由此也产生了一种新的实现模式:双重检查锁模式1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24/**
* 双重检查方式
*/
public class Singleton {
//私有构造方法
private Singleton() {}
private static Singleton instance;
//对外提供静态方法获取该对象
public static Singleton getInstance() {
//第一次判断,如果instance不为null,不进入抢锁阶段,直接返回实例
if(instance == null) {
synchronized (Singleton.class) {
//抢到锁之后再次判断是否为null
if(instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}双重检查锁模式是一种非常好的单例实现模式,解决了单例、性能、线程安全问题,上面的双重检测锁模式看上去完美无缺,其实是存在问题,在多线程的情况下,可能会出现空指针问题,出现问题的原因是JVM在实例化对象的时候会进行优化和指令重排序操作。
要解决双重检查锁模式带来空指针异常的问题,只需要使用
volatile关键字,volatile关键字可以保证可见性和有序性。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24/**
* 双重检查方式
*/
public class Singleton {
//私有构造方法
private Singleton() {}
private static volatile Singleton instance;
//对外提供静态方法获取该对象
public static Singleton getInstance() {
//第一次判断,如果instance不为null,不进入抢锁阶段,直接返回实际
if(instance == null) {
synchronized (Singleton.class) {
//抢到锁之后再次判断是否为空
if(instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}小结:
添加
volatile关键字之后的双重检查锁模式是一种比较好的单例实现模式,能够保证在多线程的情况下线程安全也不会有性能问题。
懒汉式-方式4(静态内部类方式)
静态内部类单例模式中实例由内部类创建,由于 JVM 在加载外部类的过程中, 是不会加载静态内部类的, 只有内部类的属性/方法被调用时才会被加载, 并初始化其静态属性。静态属性由于被
static修饰,保证只被实例化一次,并且严格保证实例化顺序。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17/**
* 静态内部类方式
*/
public class Singleton {
//私有构造方法
private Singleton() {}
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
//对外提供静态方法获取该对象
public static Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
}说明:
第一次加载Singleton类时不会去初始化INSTANCE,只有第一次调用getInstance,虚拟机加载SingletonHolder
并初始化INSTANCE,这样不仅能确保线程安全,也能保证 Singleton 类的唯一性。
小结:
静态内部类单例模式是一种优秀的单例模式,是开源项目中比较常用的一种单例模式。在没有加任何锁的情况下,保证了多线程下的安全,并且没有任何性能影响和空间的浪费。
枚举方式
枚举类实现单例模式是极力推荐的单例实现模式,因为枚举类型是线程安全的,并且只会装载一次,设计者充分的利用了枚举的这个特性来实现单例模式,枚举的写法非常简单,而且枚举类型是所用单例实现中唯一一种不会被破坏的单例实现模式。
1
2
3
4
5
6/**
* 枚举方式
*/
public enum Singleton {
INSTANCE;
}说明:
枚举方式属于恶汉式方式。
4.1.3 存在的问题
4.1.3.1 问题演示
破坏单例模式:
使上面定义的单例类(Singleton)可以创建多个对象,枚举方式除外。有两种方式,分别是克隆、序列化和反射。
序列化反序列化
Singleton类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14public class Singleton implements Serializable {
//私有构造方法
private Singleton() {}
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
//对外提供静态方法获取该对象
public static Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
}Test类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30public class Test {
public static void main(String[] args) throws Exception {
//往文件中写对象
//writeObject2File();
//从文件中读取对象
Singleton s1 = readObjectFromFile();
Singleton s2 = readObjectFromFile();
//判断两个反序列化后的对象是否是同一个对象
System.out.println(s1 == s2);
}
private static Singleton readObjectFromFile() throws Exception {
//创建对象输入流对象
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("C:\\Users\\Think\\Desktop\\a.txt"));
//第一个读取Singleton对象
Singleton instance = (Singleton) ois.readObject();
return instance;
}
public static void writeObject2File() throws Exception {
//获取Singleton类的对象
Singleton instance = Singleton.getInstance();
//创建对象输出流
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("C:\\Users\\Think\\Desktop\\a.txt"));
//将instance对象写出到文件中
oos.writeObject(instance);
}
}上面代码运行结果是
false,表明序列化和反序列化已经破坏了单例设计模式。反射
Singleton类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public class Singleton {
//私有构造方法
private Singleton() {}
private static volatile Singleton instance;
//对外提供静态方法获取该对象
public static Singleton getInstance() {
if(instance != null) {
return instance;
}
synchronized (Singleton.class) {
if(instance != null) {
return instance;
}
instance = new Singleton();
return instance;
}
}
}Test类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35public class Test {
public static void main(String[] args) throws Exception {
//通过getInstance()获取
Singleton singleton = Singleton.getInstance();
System.out.println("singleton的hashCode:"+singleton.hashCode());
//通过克隆获取
Singleton clob = (Singleton) Singleton.getInstance().clone();
System.out.println("clob的hashCode:"+clob.hashCode());
//通过序列化,反序列化获取
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(Singleton.getInstance());
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
Singleton serialize = (Singleton) ois.readObject();
System.out.println("serialize的hashCode:"+serialize.hashCode());
//通过反射获取
Constructor<Singleton> constructor = Singleton.class.getDeclaredConstructor();
constructor.setAccessible(true);
Singleton reflex = constructor.newInstance();
System.out.println("reflex的hashCode:"+reflex.hashCode());
if(ois != null){
ois.close();
}
if(bis != null){
bis.close();
}
if(oos != null){
oos.close();
}
if(bos != null){
bos.close();
}
}
}上面代码运行结果是
false,表明序列化和反序列化已经破坏了单例设计模式
注意:枚举方式不会出现这两个问题。
4.1.3.2 问题的解决
序列化、反序列方式破坏单例模式的解决方法
在Singleton类中添加
readResolve()方法,在反序列化时被反射调用,如果定义了这个方法,就返回这个方法的值,如果没有定义,则返回新new出来的对象。Singleton类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43public class Singleton implements Serializable,Cloneable {
//私有构造方法
private Singleton() {
/*
反射破解单例模式需要添加的代码
*/
if(instance != null) {
throw new RuntimeException();
}
}
private static volatile Singleton instance;
//对外提供静态方法获取该对象
public static Singleton getInstance() {
if(instance != null) {
return instance;
}
synchronized (Singleton.class) {
if(instance != null) {
return instance;
}
instance = new Singleton();
return instance;
}
}
private Object readResolve() {
return SingletonHolder.INSTANCE;
}
/**
* 下面是为了解决序列化反序列化破解单例模式
*/
@Override
protected Object clone() throws CloneNotSupportedException {
return Singleton.getInstance();
}
}源码解析:
ObjectInputStream类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38public final Object readObject() throws IOException, ClassNotFoundException{
...
// if nested read, passHandle contains handle of enclosing object
int outerHandle = passHandle;
try {
Object obj = readObject0(false);//重点查看readObject0方法
.....
}
private Object readObject0(boolean unshared) throws IOException {
...
try {
switch (tc) {
...
case TC_OBJECT:
return checkResolve(readOrdinaryObject(unshared));//重点查看readOrdinaryObject方法
...
}
} finally {
depth--;
bin.setBlockDataMode(oldMode);
}
}
private Object readOrdinaryObject(boolean unshared) throws IOException {
...
//isInstantiable 返回true,执行 desc.newInstance(),通过反射创建新的单例类,
obj = desc.isInstantiable() ? desc.newInstance() : null;
...
// 在Singleton类中添加 readResolve 方法后 desc.hasReadResolveMethod() 方法执行结果为true
if (obj != null && handles.lookupException(passHandle) == null && desc.hasReadResolveMethod()) {
// 通过反射调用 Singleton 类中的 readResolve 方法,将返回值赋值给rep变量
// 这样多次调用ObjectInputStream类中的readObject方法,继而就会调用我们定义的readResolve方法,所以返回的是同一个对象。
Object rep = desc.invokeReadResolve(obj);
...
}
return obj;
}
4.1.4 JDK源码解析-Runtime类
Runtime类就是使用的单例设计模式。
通过源代码查看使用的是哪儿种单例模式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public class Runtime {
private static Runtime currentRuntime = new Runtime();
/**
* Returns the runtime object associated with the current Java application.
* Most of the methods of class <code>Runtime</code> are instance
* methods and must be invoked with respect to the current runtime object.
*
* @return the <code>Runtime</code> object associated with the current
* Java application.
*/
public static Runtime getRuntime() {
return currentRuntime;
}
/** Don't let anyone else instantiate this class */
private Runtime() {}
...
}从上面源代码中可以看出Runtime类使用的是恶汉式(静态属性)方式来实现单例模式的。
使用Runtime类中的方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public class RuntimeDemo {
public static void main(String[] args) throws IOException {
//获取Runtime类对象
Runtime runtime = Runtime.getRuntime();
//返回 Java 虚拟机中的内存总量。
System.out.println(runtime.totalMemory());
//返回 Java 虚拟机试图使用的最大内存量。
System.out.println(runtime.maxMemory());
//创建一个新的进程执行指定的字符串命令,返回进程对象
Process process = runtime.exec("ipconfig");
//获取命令执行后的结果,通过输入流获取
InputStream inputStream = process.getInputStream();
byte[] arr = new byte[1024 * 1024* 100];
int b = inputStream.read(arr);
System.out.println(new String(arr,0,b,"gbk"));
}
}
设计模式-day02
4,创建型模式
4.2 工厂模式
4.2.1 概述
需求:设计一个咖啡店点餐系统。
设计一个咖啡类(Coffee),并定义其两个子类(美式咖啡【AmericanCoffee】和拿铁咖啡【LatteCoffee】);再设计一个咖啡店类(CoffeeStore),咖啡店具有点咖啡的功能。
具体类的设计如下:
在java中,万物皆对象,这些对象都需要创建,如果创建的时候直接new该对象,就会对该对象耦合严重,假如我们要更换对象,所有new对象的地方都需要修改一遍,这显然违背了软件设计的开闭原则。如果我们使用工厂来生产对象,我们就只和工厂打交道就可以了,彻底和对象解耦,如果要更换对象,直接在工厂里更换该对象即可,达到了与对象解耦的目的;所以说,工厂模式最大的优点就是:解耦。
在本教程中会介绍三种工厂的使用
- 简单工厂模式(不属于GOF的23种经典设计模式)
- 工厂方法模式
- 抽象工厂模式
4.2.2 简单工厂模式
简单工厂不是一种设计模式,反而比较像是一种编程习惯。
4.2.2.1 结构
简单工厂包含如下角色:
- 抽象产品 :定义了产品的规范,描述了产品的主要特性和功能。
- 具体产品 :实现或者继承抽象产品的子类
- 具体工厂 :提供了创建产品的方法,调用者通过该方法来获取产品。
4.2.2.2 实现
现在使用简单工厂对上面案例进行改进,类图如下:
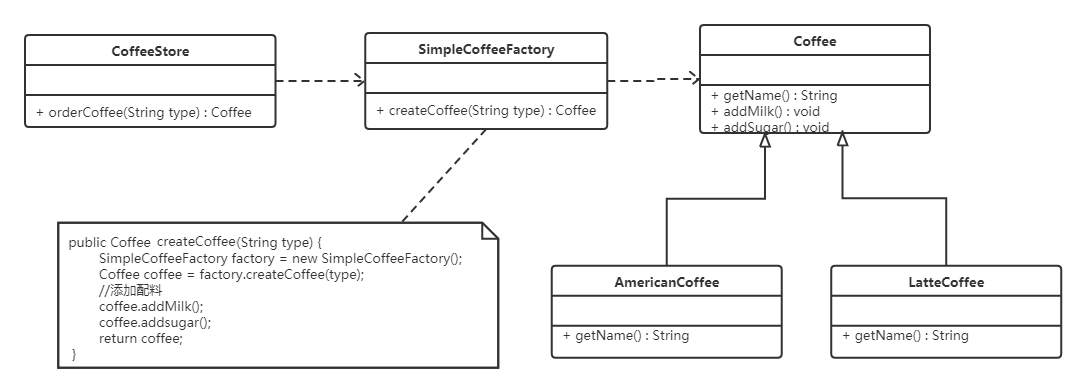
工厂类代码如下:
1 | |
工厂(factory)处理创建对象的细节,一旦有了SimpleCoffeeFactory,CoffeeStore类中的orderCoffee()就变成此对象的客户,后期如果需要Coffee对象直接从工厂中获取即可。这样也就解除了和Coffee实现类的耦合,同时又产生了新的耦合,CoffeeStore对象和SimpleCoffeeFactory工厂对象的耦合,工厂对象和商品对象的耦合。
后期如果再加新品种的咖啡,我们势必要需求修改SimpleCoffeeFactory的代码,违反了开闭原则。工厂类的客户端可能有很多,比如创建美团外卖等,这样只需要修改工厂类的代码,省去其他的修改操作。
4.2.2.4 优缺点
优点:
封装了创建对象的过程,可以通过参数直接获取对象。把对象的创建和业务逻辑层分开,这样以后就避免了修改客户代码,如果要实现新产品直接修改工厂类,而不需要在原代码中修改,这样就降低了客户代码修改的可能性,更加容易扩展。
缺点:
增加新产品时还是需要修改工厂类的代码,违背了“开闭原则”。
4.2.2.3 扩展
静态工厂
在开发中也有一部分人将工厂类中的创建对象的功能定义为静态的,这个就是静态工厂模式,它也不是23种设计模式中的。代码如下:
1 | |
4.2.3 工厂方法模式
针对上例中的缺点,使用工厂方法模式就可以完美的解决,完全遵循开闭原则。
4.2.3.1 概念
定义一个用于创建对象的接口,让子类决定实例化哪个产品类对象。工厂方法使一个产品类的实例化延迟到其工厂的子类。
4.2.3.2 结构
工厂方法模式的主要角色:
- 抽象工厂(Abstract Factory):提供了创建产品的接口,调用者通过它访问具体工厂的工厂方法来创建产品。
- 具体工厂(ConcreteFactory):主要是实现抽象工厂中的抽象方法,完成具体产品的创建。
- 抽象产品(Product):定义了产品的规范,描述了产品的主要特性和功能。
- 具体产品(ConcreteProduct):实现了抽象产品角色所定义的接口,由具体工厂来创建,它同具体工厂之间一一对应。
4.2.3.3 实现
使用工厂方法模式对上例进行改进,类图如下:
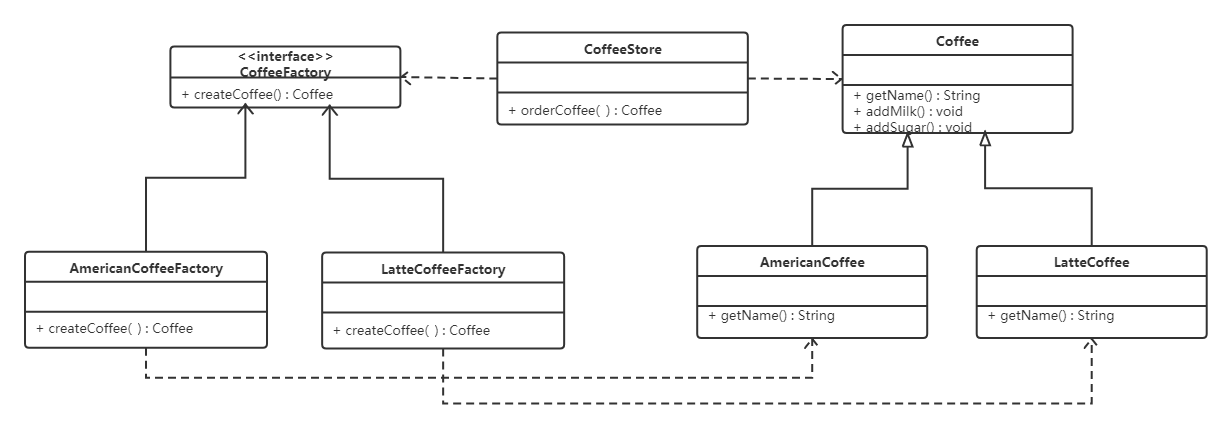
代码如下:
抽象工厂:
1 | |
具体工厂:
1 | |
咖啡店类:
1 | |
从以上的编写的代码可以看到,要增加产品类时也要相应地增加工厂类,不需要修改工厂类的代码了,这样就解决了简单工厂模式的缺点。
工厂方法模式是简单工厂模式的进一步抽象。由于使用了多态性,工厂方法模式保持了简单工厂模式的优点,而且克服了它的缺点。
4.2.3.4 优缺点
优点:
- 用户只需要知道具体工厂的名称就可得到所要的产品,无须知道产品的具体创建过程;
- 在系统增加新的产品时只需要添加具体产品类和对应的具体工厂类,无须对原工厂进行任何修改,满足开闭原则;
缺点:
- 每增加一个产品就要增加一个具体产品类和一个对应的具体工厂类,这增加了系统的复杂度。
4.2.4 抽象工厂模式
前面介绍的工厂方法模式中考虑的是一类产品的生产,如畜牧场只养动物、电视机厂只生产电视机、传智播客只培养计算机软件专业的学生等。
这些工厂只生产同种类产品,同种类产品称为同等级产品,也就是说:工厂方法模式只考虑生产同等级的产品,但是在现实生活中许多工厂是综合型的工厂,能生产多等级(种类) 的产品,如电器厂既生产电视机又生产洗衣机或空调,大学既有软件专业又有生物专业等。
本节要介绍的抽象工厂模式将考虑多等级产品的生产,将同一个具体工厂所生产的位于不同等级的一组产品称为一个产品族,下图所示横轴是产品等级,也就是同一类产品;纵轴是产品族,也就是同一品牌的产品,同一品牌的产品产自同一个工厂。

4.2.4.1 概念
是一种为访问类提供一个创建一组相关或相互依赖对象的接口,且访问类无须指定所要产品的具体类就能得到同族的不同等级的产品的模式结构。
抽象工厂模式是工厂方法模式的升级版本,工厂方法模式只生产一个等级的产品,而抽象工厂模式可生产多个等级的产品。
4.2.4.2 结构
抽象工厂模式的主要角色如下:
- 抽象工厂(Abstract Factory):提供了创建产品的接口,它包含多个创建产品的方法,可以创建多个不同等级的产品。
- 具体工厂(Concrete Factory):主要是实现抽象工厂中的多个抽象方法,完成具体产品的创建。
- 抽象产品(Product):定义了产品的规范,描述了产品的主要特性和功能,抽象工厂模式有多个抽象产品。
- 具体产品(ConcreteProduct):实现了抽象产品角色所定义的接口,由具体工厂来创建,它 同具体工厂之间是多对一的关系。
4.2.4.2 实现
现咖啡店业务发生改变,不仅要生产咖啡还要生产甜点,如提拉米苏、抹茶慕斯等,要是按照工厂方法模式,需要定义提拉米苏类、抹茶慕斯类、提拉米苏工厂、抹茶慕斯工厂、甜点工厂类,很容易发生类爆炸情况。其中拿铁咖啡、美式咖啡是一个产品等级,都是咖啡;提拉米苏、抹茶慕斯也是一个产品等级;拿铁咖啡和提拉米苏是同一产品族(也就是都属于意大利风味),美式咖啡和抹茶慕斯是同一产品族(也就是都属于美式风味)。所以这个案例可以使用抽象工厂模式实现。类图如下:
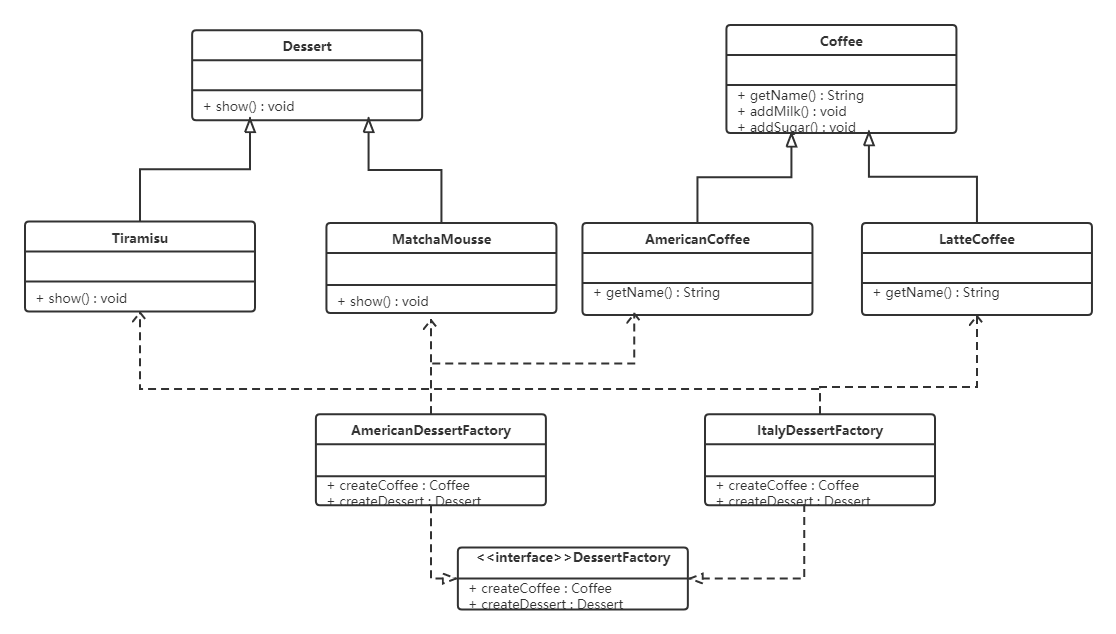
代码如下:
抽象工厂:
1 | |
具体工厂:
1 | |
如果要加同一个产品族的话,只需要再加一个对应的工厂类即可,不需要修改其他的类。
4.2.4.3 优缺点
优点:
当一个产品族中的多个对象被设计成一起工作时,它能保证客户端始终只使用同一个产品族中的对象。
缺点:
当产品族中需要增加一个新的产品时,所有的工厂类都需要进行修改。
4.2.4.4 使用场景
当需要创建的对象是一系列相互关联或相互依赖的产品族时,如电器工厂中的电视机、洗衣机、空调等。
系统中有多个产品族,但每次只使用其中的某一族产品。如有人只喜欢穿某一个品牌的衣服和鞋。
系统中提供了产品的类库,且所有产品的接口相同,客户端不依赖产品实例的创建细节和内部结构。
如:输入法换皮肤,一整套一起换。生成不同操作系统的程序。
4.2.5 模式扩展
简单工厂+配置文件解除耦合
可以通过工厂模式+配置文件的方式解除工厂对象和产品对象的耦合。在工厂类中加载配置文件中的全类名,并创建对象进行存储,客户端如果需要对象,直接进行获取即可。
第一步:定义配置文件
为了演示方便,我们使用properties文件作为配置文件,名称为bean.properties
1 | |
第二步:改进工厂类
1 | |
静态成员变量用来存储创建的对象(键存储的是名称,值存储的是对应的对象),而读取配置文件以及创建对象写在静态代码块中,目的就是只需要执行一次。
4.2.6 JDK源码解析-Collection.iterator方法
1 | |
对上面的代码大家应该很熟,使用迭代器遍历集合,获取集合中的元素。而单列集合获取迭代器的方法就使用到了工厂方法模式。我们看通过类图看看结构:
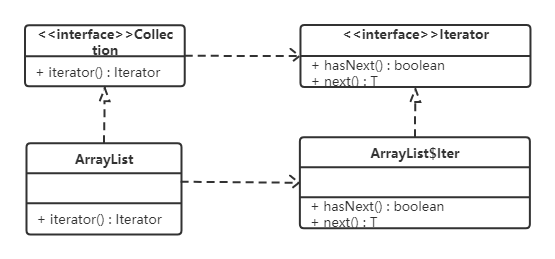
Collection接口是抽象工厂类,ArrayList是具体的工厂类;Iterator接口是抽象商品类,ArrayList类中的Iter内部类是具体的商品类。在具体的工厂类中iterator()方法创建具体的商品类的对象。
另:
1,DateForamt类中的getInstance()方法使用的是工厂模式;
2,Calendar类中的getInstance()方法使用的是工厂模式;
4.3 原型模式
4.3.1 概述
用一个已经创建的实例作为原型,通过复制该原型对象来创建一个和原型对象相同的新对象。
4.3.2 结构
原型模式包含如下角色:
- 抽象原型类:规定了具体原型对象必须实现的的 clone() 方法。
- 具体原型类:实现抽象原型类的 clone() 方法,它是可被复制的对象。
- 访问类:使用具体原型类中的 clone() 方法来复制新的对象。
接口类图如下:
4.3.3 实现
原型模式的克隆分为浅克隆和深克隆。
浅克隆:创建一个新对象,新对象的属性和原来对象完全相同,对于非基本类型属性,仍指向原有属性所指向的对象的内存地址。
深克隆:创建一个新对象,属性中引用的其他对象也会被克隆,不再指向原有对象地址。
Java中的Object类中提供了 clone() 方法来实现浅克隆。 Cloneable 接口是上面的类图中的抽象原型类,而实现了Cloneable接口的子实现类就是具体的原型类。代码如下:
Realizetype(具体的原型类):
1 | |
PrototypeTest(测试访问类):
1 | |
4.3.4 案例
用原型模式生成“三好学生”奖状
同一学校的“三好学生”奖状除了获奖人姓名不同,其他都相同,可以使用原型模式复制多个“三好学生”奖状出来,然后在修改奖状上的名字即可。
类图如下:
代码如下:
1 | |
4.3.5 使用场景
- 对象的创建非常复杂,可以使用原型模式快捷的创建对象。
- 性能和安全要求比较高。
4.3.6 扩展(深克隆)
将上面的“三好学生”奖状的案例中Citation类的name属性修改为Student类型的属性。代码如下:
1 | |
运行结果为:

说明:
stu对象和stu1对象是同一个对象,就会产生将stu1对象中name属性值改为“李四”,两个Citation(奖状)对象中显示的都是李四。这就是浅克隆的效果,对具体原型类(Citation)中的引用类型的属性进行引用的复制。这种情况需要使用深克隆,而进行深克隆需要使用对象流。代码如下:
1 | |
运行结果为:

注意:Citation类和Student类必须实现Serializable接口,否则会抛NotSerializableException异常。
4.5 建造者模式
4.4.1 概述
将一个复杂对象的构建与表示分离,使得同样的构建过程可以创建不同的表示。

- 分离了部件的构造(由Builder来负责)和装配(由Director负责)。 从而可以构造出复杂的对象。这个模式适用于:某个对象的构建过程复杂的情况。
- 由于实现了构建和装配的解耦。不同的构建器,相同的装配,也可以做出不同的对象;相同的构建器,不同的装配顺序也可以做出不同的对象。也就是实现了构建算法、装配算法的解耦,实现了更好的复用。
- 建造者模式可以将部件和其组装过程分开,一步一步创建一个复杂的对象。用户只需要指定复杂对象的类型就可以得到该对象,而无须知道其内部的具体构造细节。
4.4.2 结构
建造者(Builder)模式包含如下角色:
抽象建造者类(Builder):这个接口规定要实现复杂对象的那些部分的创建,并不涉及具体的部件对象的创建。
具体建造者类(ConcreteBuilder):实现 Builder 接口,完成复杂产品的各个部件的具体创建方法。在构造过程完成后,提供产品的实例。
产品类(Product):要创建的复杂对象。
指挥者类(Director):调用具体建造者来创建复杂对象的各个部分,在指导者中不涉及具体产品的信息,只负责保证对象各部分完整创建或按某种顺序创建。
类图如下:
4.4.3 实例
创建共享单车
生产自行车是一个复杂的过程,它包含了车架,车座等组件的生产。而车架又有碳纤维,铝合金等材质的,车座有橡胶,真皮等材质。对于自行车的生产就可以使用建造者模式。
这里Bike是产品,包含车架,车座等组件;Builder是抽象建造者,MobikeBuilder和OfoBuilder是具体的建造者;Director是指挥者。类图如下:
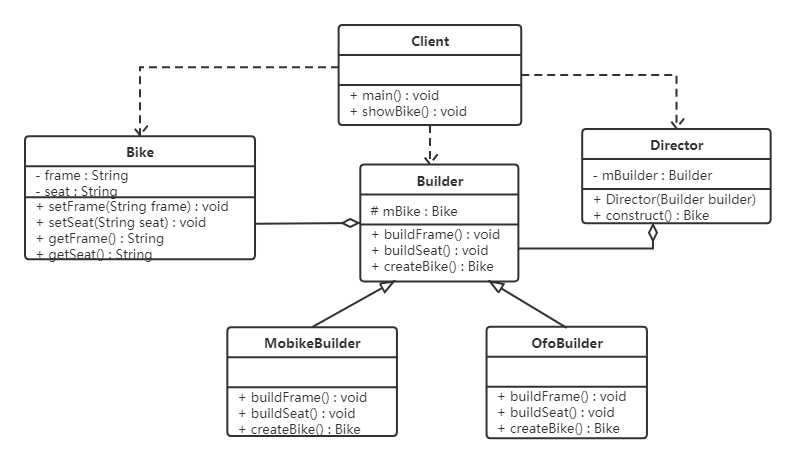
具体的代码如下:
1 | |
注意:
上面示例是 Builder模式的常规用法,指挥者类 Director 在建造者模式中具有很重要的作用,它用于指导具体构建者如何构建产品,控制调用先后次序,并向调用者返回完整的产品类,但是有些情况下需要简化系统结构,可以把指挥者类和抽象建造者进行结合
1 | |
说明:
这样做确实简化了系统结构,但同时也加重了抽象建造者类的职责,也不是太符合单一职责原则,如果construct() 过于复杂,建议还是封装到 Director 中。
4.4.4 优缺点
优点:
- 建造者模式的封装性很好。使用建造者模式可以有效的封装变化,在使用建造者模式的场景中,一般产品类和建造者类是比较稳定的,因此,将主要的业务逻辑封装在指挥者类中对整体而言可以取得比较好的稳定性。
- 在建造者模式中,客户端不必知道产品内部组成的细节,将产品本身与产品的创建过程解耦,使得相同的创建过程可以创建不同的产品对象。
- 可以更加精细地控制产品的创建过程 。将复杂产品的创建步骤分解在不同的方法中,使得创建过程更加清晰,也更方便使用程序来控制创建过程。
- 建造者模式很容易进行扩展。如果有新的需求,通过实现一个新的建造者类就可以完成,基本上不用修改之前已经测试通过的代码,因此也就不会对原有功能引入风险。符合开闭原则。
缺点:
造者模式所创建的产品一般具有较多的共同点,其组成部分相似,如果产品之间的差异性很大,则不适合使用建造者模式,因此其使用范围受到一定的限制。
4.4.5 使用场景
建造者(Builder)模式创建的是复杂对象,其产品的各个部分经常面临着剧烈的变化,但将它们组合在一起的算法却相对稳定,所以它通常在以下场合使用。
- 创建的对象较复杂,由多个部件构成,各部件面临着复杂的变化,但构件间的建造顺序是稳定的。
- 创建复杂对象的算法独立于该对象的组成部分以及它们的装配方式,即产品的构建过程和最终的表示是独立的。
4.4.6 模式扩展
建造者模式除了上面的用途外,在开发中还有一个常用的使用方式,就是当一个类构造器需要传入很多参数时,如果创建这个类的实例,代码可读性会非常差,而且很容易引入错误,此时就可以利用建造者模式进行重构。
重构前代码如下:
1 | |
上面在客户端代码中构建Phone对象,传递了四个参数,如果参数更多呢?代码的可读性及使用的成本就是比较高。
重构后代码:
1 | |
重构后的代码在使用起来更方便,某种程度上也可以提高开发效率。从软件设计上,对程序员的要求比较高。
4.6 创建者模式对比
4.6.1 工厂方法模式VS建造者模式
工厂方法模式注重的是整体对象的创建方式;而建造者模式注重的是部件构建的过程,意在通过一步一步地精确构造创建出一个复杂的对象。
我们举个简单例子来说明两者的差异,如要制造一个超人,如果使用工厂方法模式,直接产生出来的就是一个力大无穷、能够飞翔、内裤外穿的超人;而如果使用建造者模式,则需要组装手、头、脚、躯干等部分,然后再把内裤外穿,于是一个超人就诞生了。
4.6.2 抽象工厂模式VS建造者模式
抽象工厂模式实现对产品家族的创建,一个产品家族是这样的一系列产品:具有不同分类维度的产品组合,采用抽象工厂模式则是不需要关心构建过程,只关心什么产品由什么工厂生产即可。
建造者模式则是要求按照指定的蓝图建造产品,它的主要目的是通过组装零配件而产生一个新产品。
如果将抽象工厂模式看成汽车配件生产工厂,生产一个产品族的产品,那么建造者模式就是一个汽车组装工厂,通过对部件的组装可以返回一辆完整的汽车。