深入理解Mysql索引底层数据结构与算法
索引是什么
索引是帮助MySQL高效获取数据的排好序的数据结构
索引数据结构
二叉树
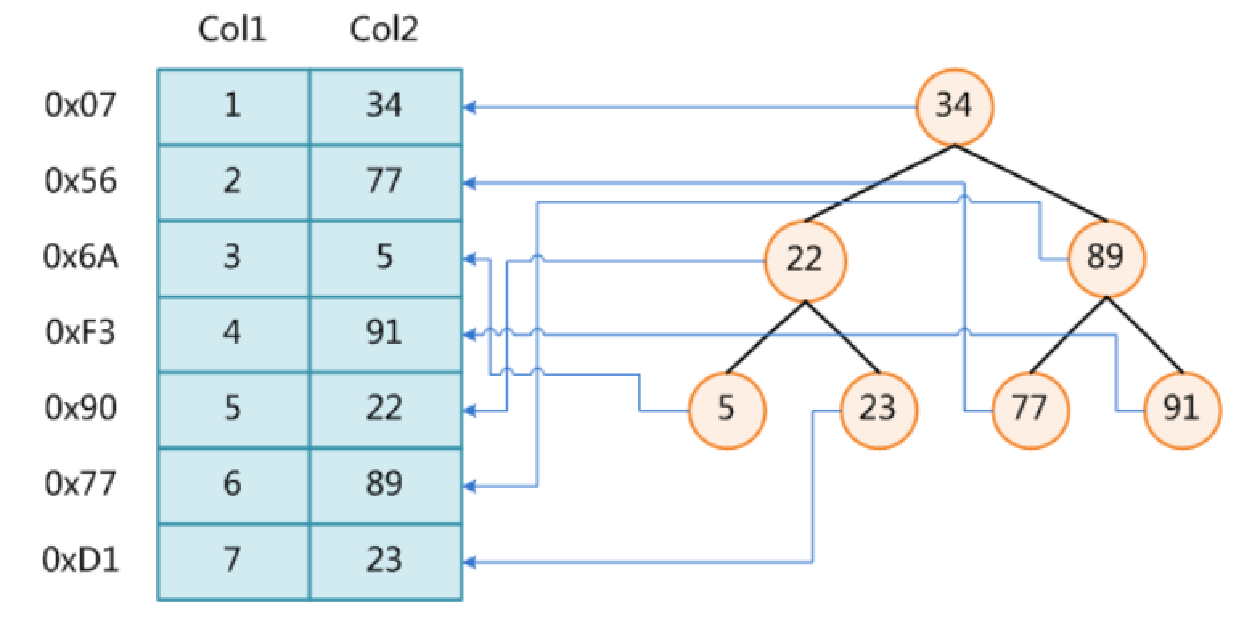
缺点:
- 索引树的高度 >= log2N + 1 高度可能较高,不可控
- 索引步骤同样不可控,效率较低
- 可能形成单向链表、索引效果底下
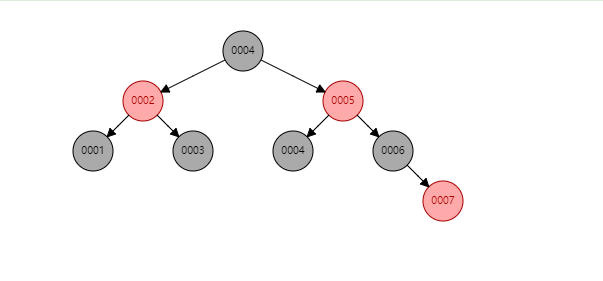
红黑树 (效率比二叉树高)
缺点:
- 可能存在自旋,维护复杂
- 高度不可控(千万级别数据,层数高)
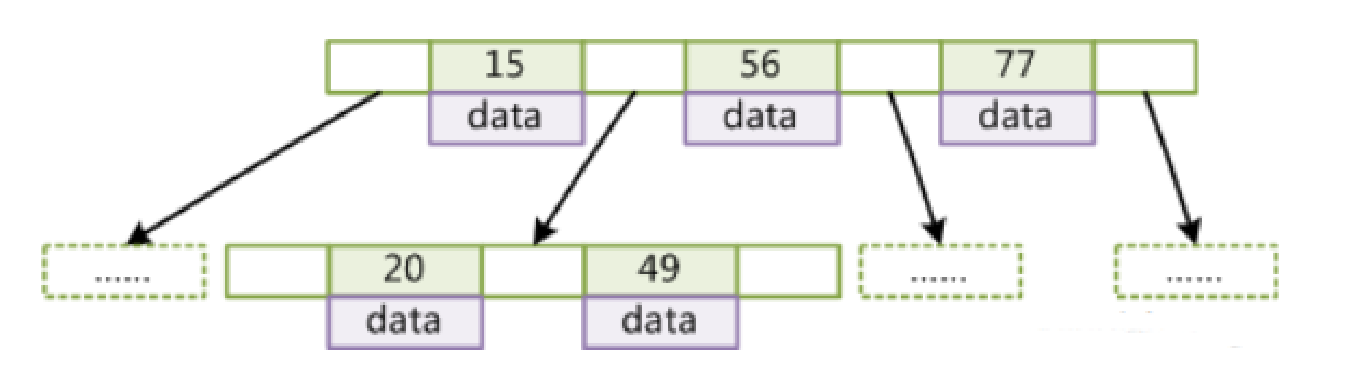
B-Tree
特点:
- 叶节点具有相同的深度
- 索引元素不重复
- 节点从左到右递增
缺点:
- 索引树的高度依旧不可控(因为mysql一般规定一个节点16kb,如果使用InnoDB存储引擎且是主建索引,则value存储的可能就是整个表数据,这会导致每个节点存储的接口个数较少,导致层数增大)
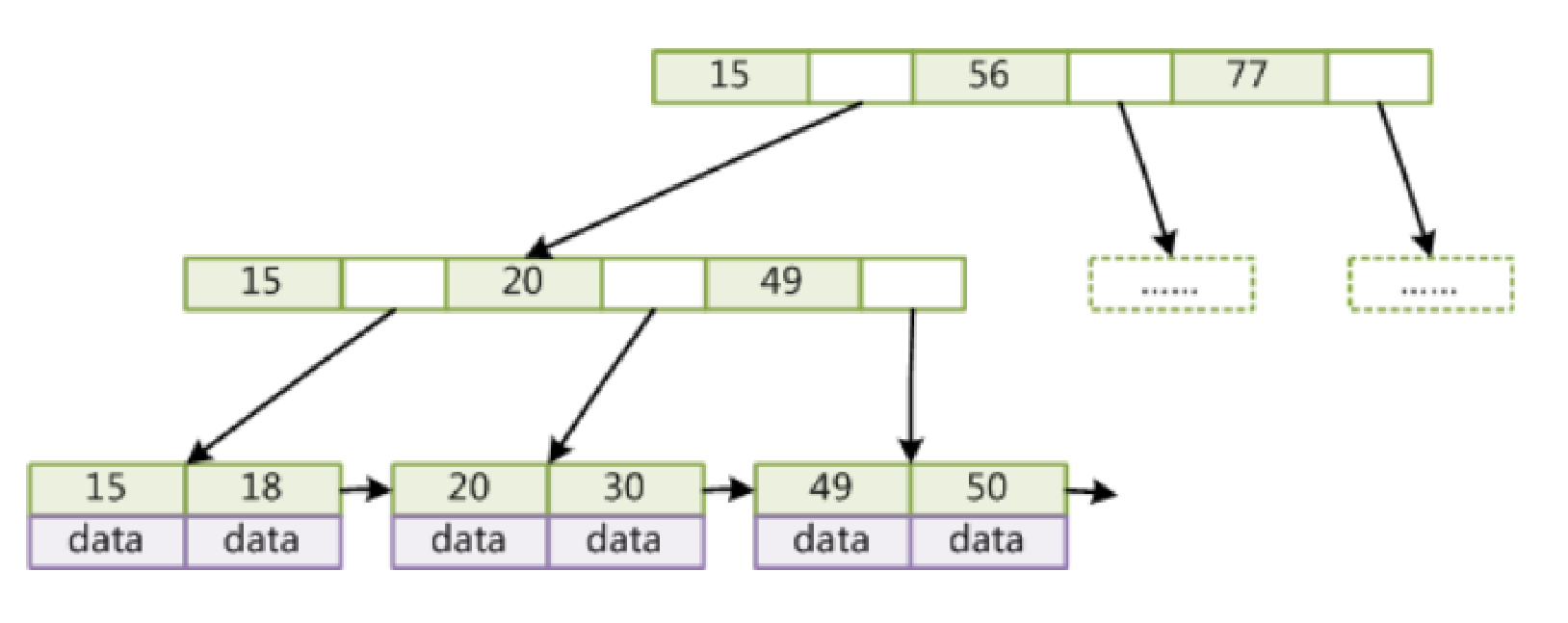
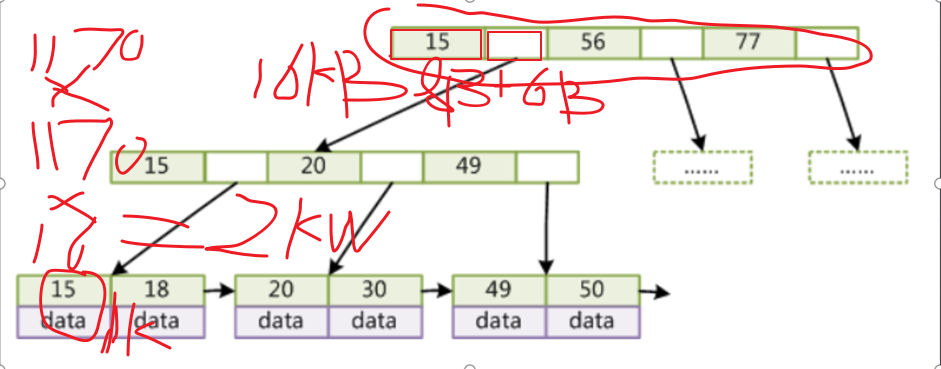
Mysql的B+Tree(原B+Tree叶子结点是单向指针)
特点
- 非叶子节点不存储data,只存储索引(叶子结点会冗余),因此可以放更多的索引
- 叶子结点包含所有的索引字段
- 叶子结点之间通过指针双向连接,提高区间访问的性能
Mysql的Hash索引
维护索引列值的hash值和所在行的磁盘空间地址的关系表,可以快速查询出某个值所在行。
存在什么问题:
不支持范围查询、模糊查询,排序,
优点:
单等值查询非常快
索引是怎么支撑千万级表的快速查找
使用B+树缩影,假设树的高度 h = 3,一个节点大小限制16k,主建索引,bigint = 8B,指针连接
=6B。总叶子结点 = (161024/14) * (161024/14) * 16 = 21902400
InnoDB存储引擎索引实现
MYSQL5.7
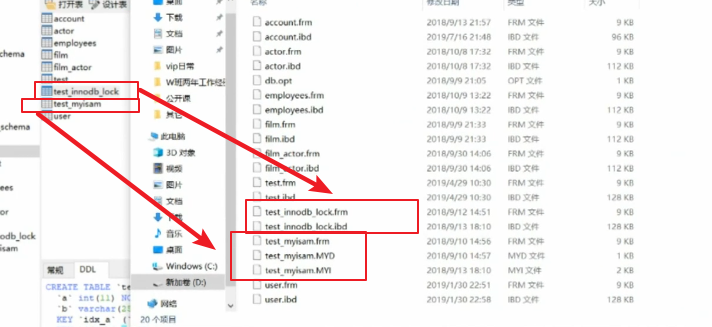
MYISAM存储引擎
.frm 表结构
.MYD 表数据
.MYI 表索引
MyISAM索引文件和数据文件是分离的(非聚集)
INNODB存储引擎
.frm 表结构
.ibd 表数据
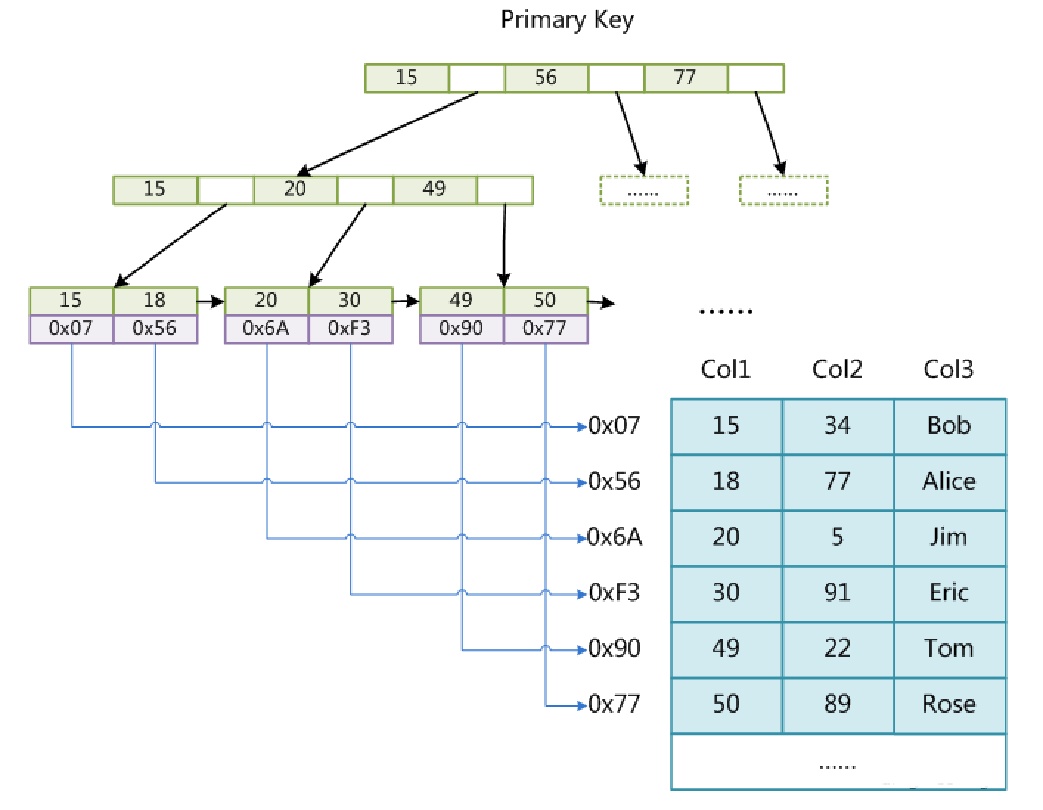
InnoDB的主建索引(聚簇索引)
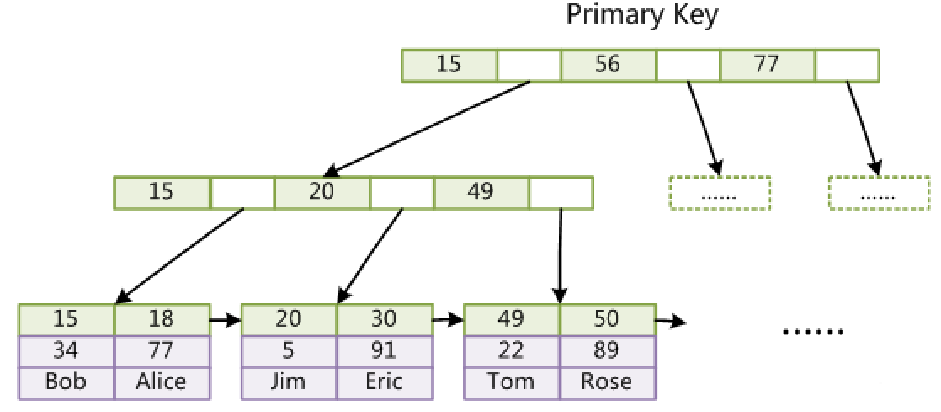
InnoDB的非主键索引(非聚簇索引)
通过检索二级索引树查到对应主建,在检索主建索引树
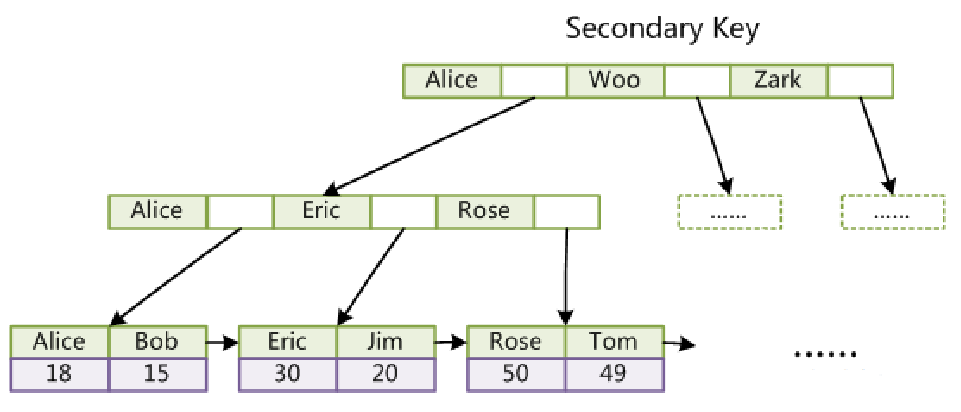
什么是聚簇索引和非聚簇索引
聚簇索引:索引结构和表数据存储在一起的索引
非聚簇索引:索引结构和表数据存储分开存储的索引
为什么InnoDB表必须有主键,并且推荐使用整型的自增主键?
1、为什么推荐声明主建
答:B+树索引数据结构就是根据某个唯一索引组装而成的,就算不声明主建,Mysql也会自动生成一个唯一序列号作为key去构建整棵树
2、为什么推荐整形
答:如果用字符串,还得统一装换成ASCALL码进行比较大小,如果是整形则比较更加便捷
3、为什么推荐自增
答:B+树在逐步构建时都是某个节点满了才向右扩充,如果这个时候插入某一个值且这个值要放在已经满了的节点,则容易造成B+树频繁调整,维护麻烦。(自增插入的话,只会影响右下角区域的数据调整)
为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)
1、节省存储空间,存在多个索引时,只有主键索引才包含所有数据,其他索引只冗余主建id,这样可以大大节约空间
2、如果多个索引都维护所有数据,那势必会有维护复杂,数据一致性问题,事倍功半。
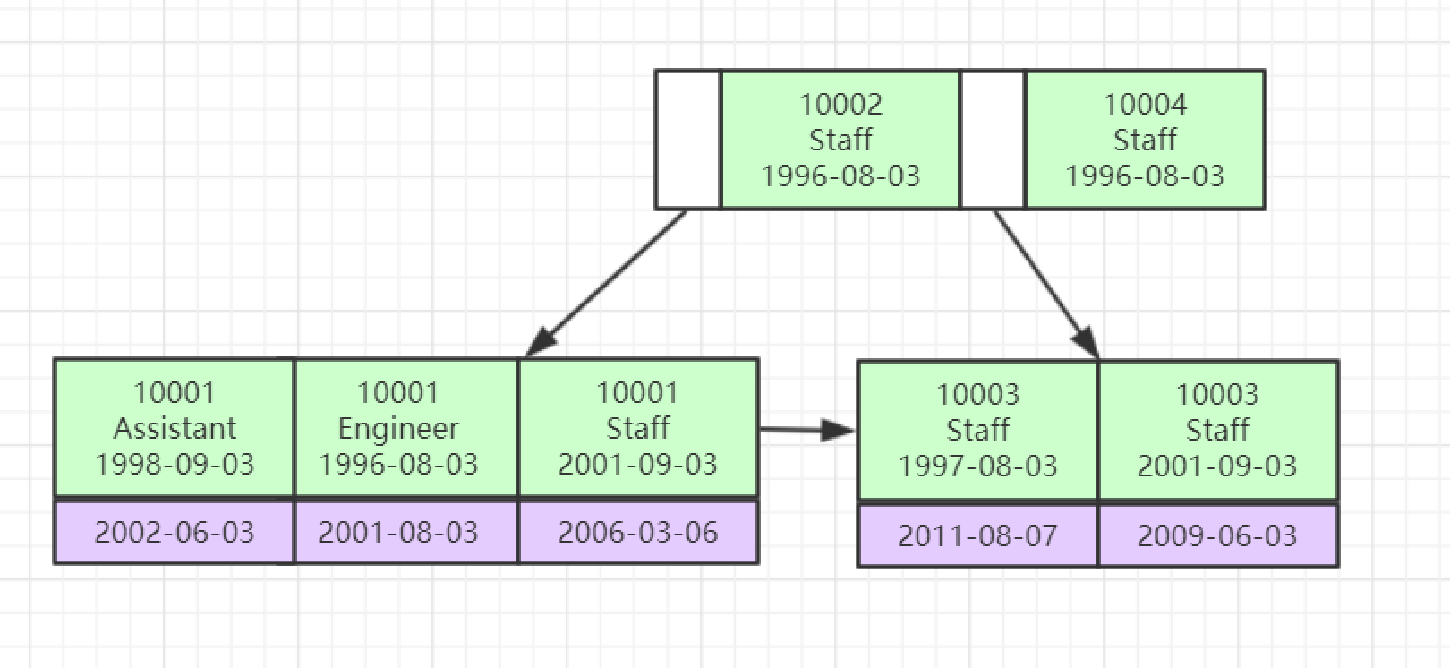
联合索引的底层存储结构长什么样
InnoDB 和 MyIsam 引擎的区别
| 特性 | InnoDB | MyISAM |
|---|---|---|
| 事务支持 | 是 支持ACID | 否 |
| 锁定级别 | 行级锁定 | 表级锁定 |
| 外键支持 | 是 | 否 |
| 崩溃恢复 | 是 | 否 |
| 全文本搜索 | 是(复杂) | 是(简单) |
| 读性能 | 一般 | 较好 |
| 写性能 | 一般 | 较差 |
| 适用场景 | OLTP应用,事务处理 | 读密集型应用,全文本搜索 |