Kafka特性详解&场景介绍
Java集合
Java集合
leetcode100-2
leetcode热题100
leetcode100-树
leetcode热题100
leetcode100-1
leetcode热题100
分布式-分布式事务基础
1、分布式事务?2、ACID和CAP的 CA是一样的吗?3、分布式事务常用的解决方案的优缺点是什么?适用于什么场景?4、分布式事务出现的原因?用来解决什么痛点?
分布式-排队任务
在异步延时任务的基础上,扩展排队任务
分布式-异步延时任务
在异步延时任务的基础上,扩展排队任务
分布式-Dubbo01-认识分布式
Dubbo认识分布式
分布式-Mysql读写分离及高可用方案
Mysql读写分离及高可用方案
主从架构
为什么要主从架构?
1、如果主服务器出现问题,可以快速切换到从服务器提供的服务
2、可以在从服务器上执行查询操作,降低主服务器的访问压力
3、可以在从服务器上执行备份,以避免备份期间影响主服务器的服务
主从方案
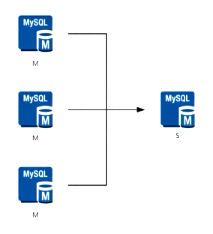
1、M-S:一主一从
2、M-M-M-S:多主一从
3、M-S-S-S:一主多级从
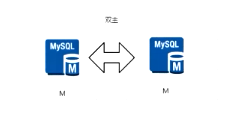
4、M-M(MMM方案):双主
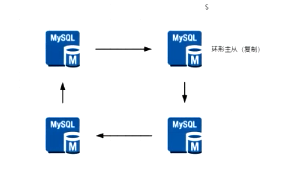
5、S-S-S-S :环型主从
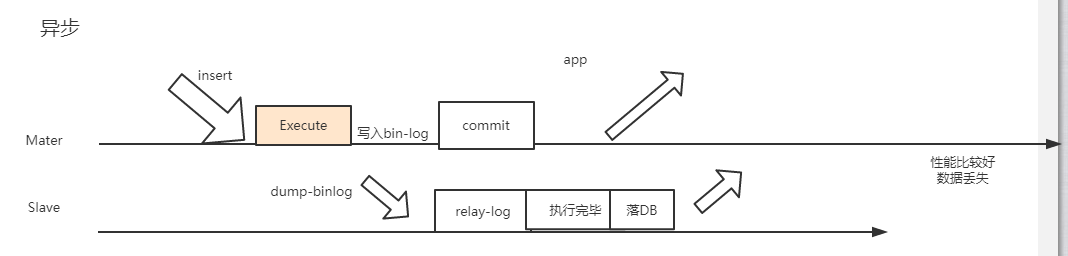
主从复制:延时问题
relay log
从数据库Slave服务的I/O线程从主数据库Master服务的二进制日志中读取数据库的更改记录并写入到中继日志中,然后在Slave数据库执行修改操作。这就是中继日志Relay Log
有哪些主从复制方式
1、同步复制

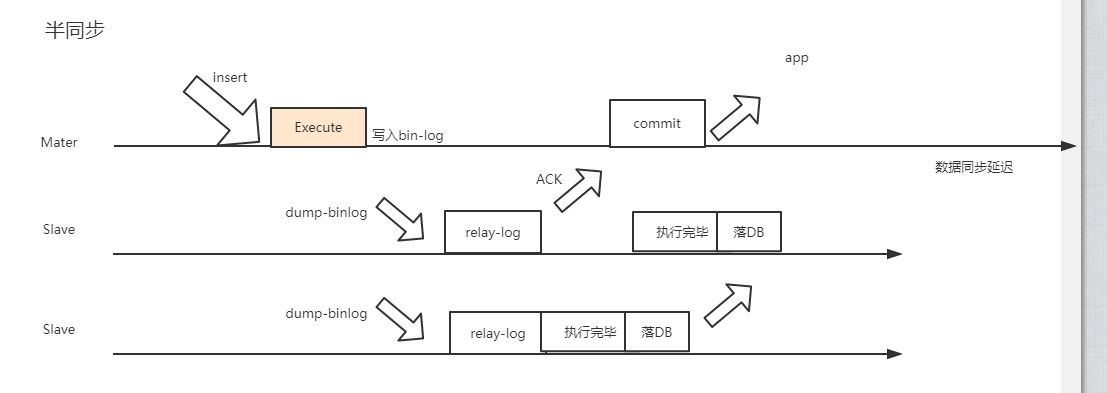
2、半同步复制
3、异步复制(mysql默认的复制方式)
主从复制原理
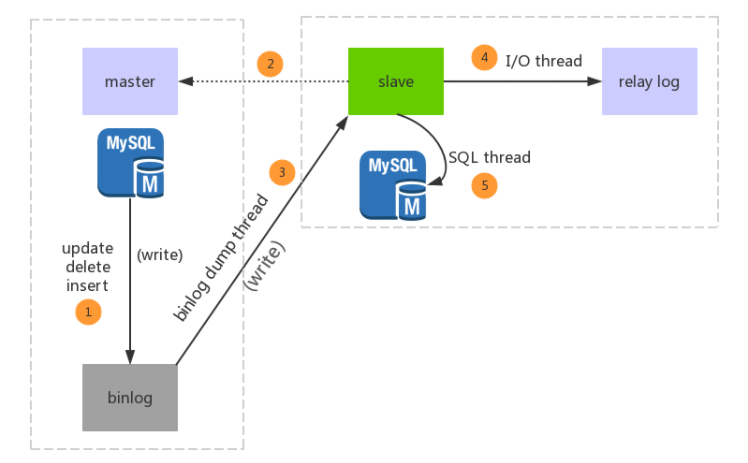
数据同步方式:
1、GTID
2、bin-log
高可用方案
MMM(业界已弃用)
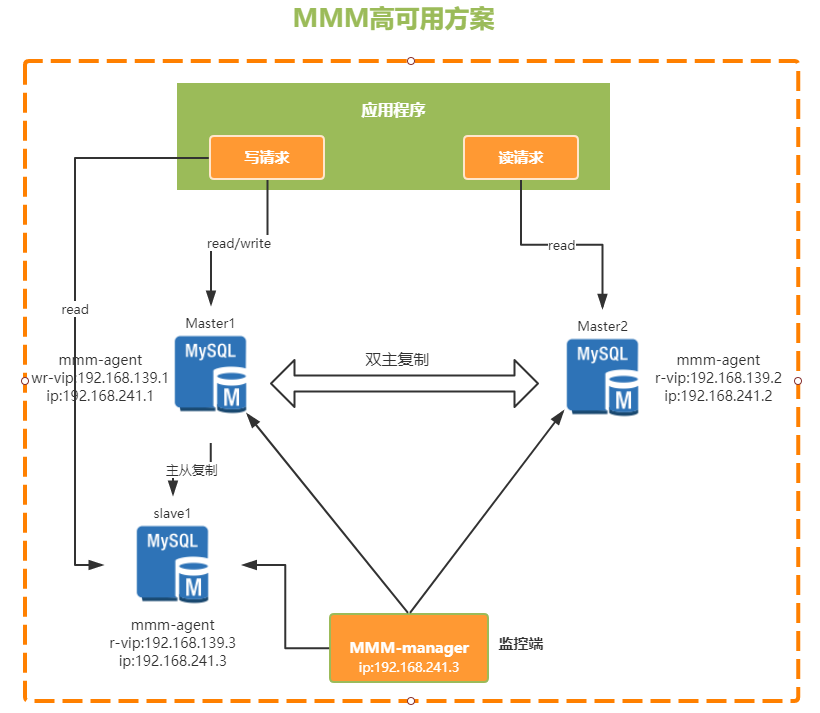
1.1 优点
1、高可用性,扩展性好,出现故障自动转移,对于主主同步,在同一时间只提供一台数
据库写操作,保证数据的一致性。
2、配置简单,容易操作。
1.2 缺点
1、需要一台备份服务器,浪费资源
2、需要多个虚拟IP
3、agent可能意外终止,引起裂脑。
MHA
MHA(Mysql一主两从) + proxySql(代理2台) + 读写分离
如果需要分库分表:采用shardingsphere,sync_binlog = 1 设置binlog强制刷盘,默认主从采用的异步复制
MHA服务,有两种角色, MHA Manager(管理节点)和 MHA Node(数据节点)。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器。
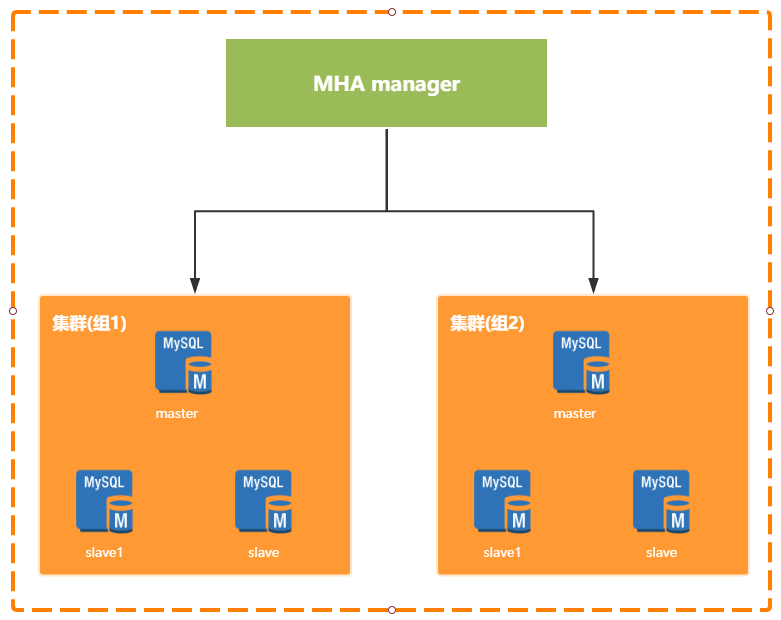
2.1 优点
(1)不需要备份服务器
(2)不改变现有环境
(3)操作非常简单
(4)可以进行日志的差异修复
(5)可以将任意slave提升为master
2.2 缺点
(1)需要全部节点做ssh秘钥
(2)MHA出现故障后配置文件会被修改,如果再次故障转移需要重新修改配置文件。
(3)自带的脚本还需要进一步补充完善,且用perl开发,二次开发困难。
分库分表
什么是分库分表?
将一个表拆分多张表(库内分表与分库分表)
为什么需要分库分表?
1、数据量大,单表数据量超过千万容易出现性能瓶颈,即便索引优化也提升不了速度(B+树)树高过高,IO次数增加)
2、物理服务器的CPU、内存、存储、连接数等资源存在限制,某个时段大量连接执行操作,会导致数据库处理时遇到性能瓶颈
因此出现了分而治之的思想,对大表进行切割,实施更好地控制和管理,同时使用多台机器的CPU、内存、存储,提供更好的性能。而分而治之则有两种方式:垂直拆分和水平拆分。
垂直拆分
垂直分库
对不同的表进行分库:垂直分库其实是一种简单逻辑分割。比如我们的数据库中有商品表Products、还有对订单表Orders,还有积分表Scores。接下来我们就可以创建三个数据库,一个数据库存放商品,一个数据库存放订单,一个数据库存放积分。如下图所示:
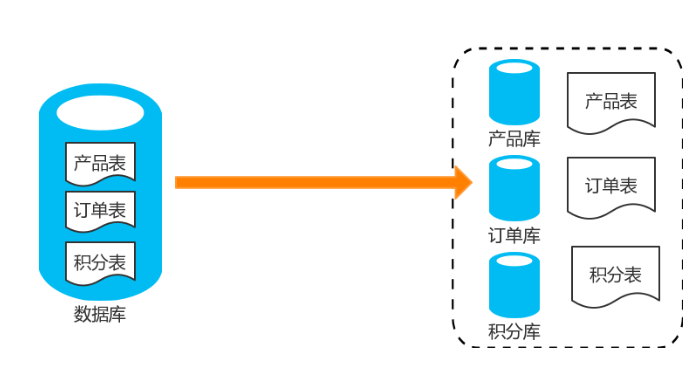
垂直分表
对宽表进行字段拆分:比较适用于那种字段比较多的表,假设我们一张表有100个字段,我们分析了一下当前业务执行的SQL语句,有20个字段是经常使用的,而另外80个字段使用比较少。
这样我们就可以把20个字段放在主表里面,我们在创建一个辅助表,存放另外80个字段。当然主表和辅助表都是有主键的。他们通过主键进行关联合并,就可以凑成100个字段的表
优缺点
优点
1、跟随业务进行分割,和最近流行的微服务概念相似,方便解耦之后的管理及扩展。
2、高并发的场景下,垂直拆分使用多台服务器的CPU、I/O、内存能提升性能,同时对单机数据库连接数、一些资源限制也得到了提升。
3、能实现冷热数据的分离
缺点
1、部分业务表无法join,应用层需要很大的改造,只能通过聚合的方式来实现。增加了开发的难度。
2、当单库中的表数据量增大的时候依然没有得到有效的解决。
3、分布式事务也是一个难题
水平拆分
库内分表
假设当我们的Orders表达到了5000万行记录的时候,非常影响数据库的读写效率,怎么办呢?我们可以考虑按照订单编号的order_id进行rang分区,就是把订单编号在1-1000万的放在order1表中,将编号在1000万-2000万的放在order2中,以此类推,每个表中存放1000万数据。
虽然我们可以通过库内分表把单表的容量固定在1000万,但是这些表的数据仍然存放在一个库内,使用的是该主机的CPU、IO、内存。单库的连接数也有限制。并不能完全的降低系统的压力。此时,我们就要考虑另外一种技术叫分库分表。
分库分表
分库分表在库内分表的基础上,将分的表挪动到不同的主机和数据库上。可以充分的使用其他主机的CPU、内存和IO资源。并且分库之后,单库的连接数限制也不在成为瓶颈。
但是“成也萧何败也萧何”,如果你执行一个扫描不带分片键,则需要在每个库上查一遍。刚刚我们按照order_id分成了5个库,但是我们查询是name=’AAA’的条件并且不带order_id字段时,它并不知道在哪个分片上查,则会创建5个连接,然后每个库都检索一遍。这种广播查询则会造成连接数增多。
因为它需要在每个库上都创立连接。如果是高并发的系统,执行这种广播查询,系统的thread很快就会告警
优缺点
优点
1、水平扩展能持续扩展。不存在某个库某个表过大的情况。
2、能够较好的应对高并发,同时可以将热点数据打散。
缺点
1、增加程序复杂度,增加一成路由选择计算,对一些统计类查询要查询多个库多个表才能聚合出结果
2、市面上的分库分表插件对此存在限制,join、分页性能差,功能存在限制
3、分布式事务的一致性问题
4、横向扩充时,数据迁移问题
分库分表组件
shardingsphere(京东数科)在apache孵化
Mycat(阿里巴巴-基于cobar)不是阿里的
Atlas (奇虎360)
参考:https://juejin.cn/post/7085132195190276109
什么场景需要分库分表
分库分表后存在的问题:
- 事务问题
- 跨库关联
- 排序问题
- 分页问题
- 分布式ID